
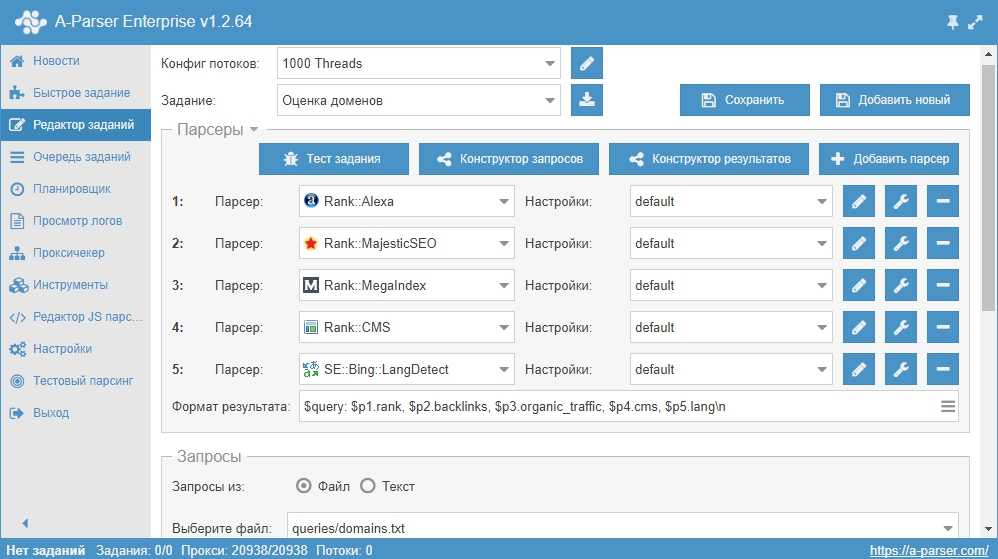
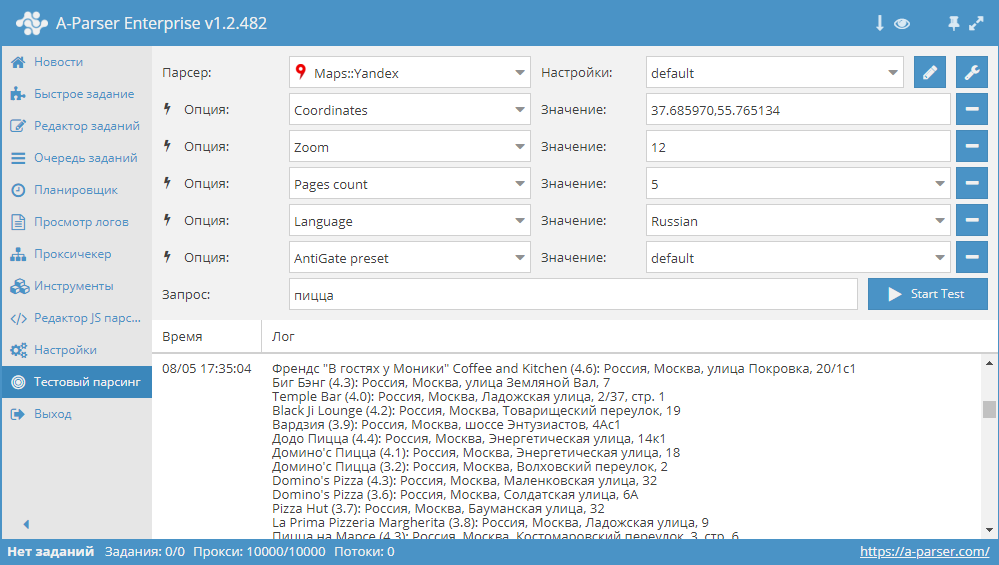
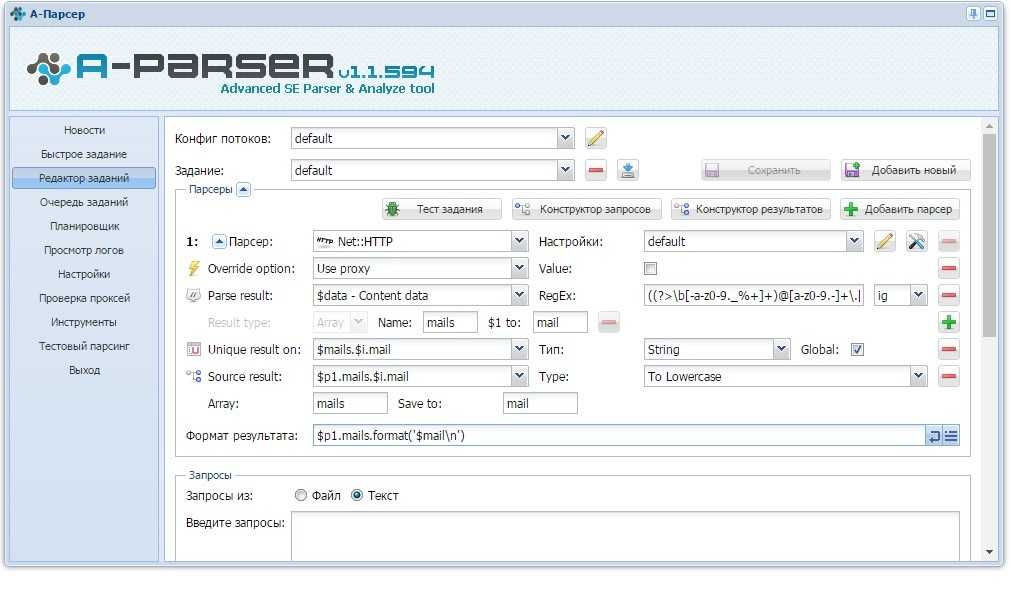
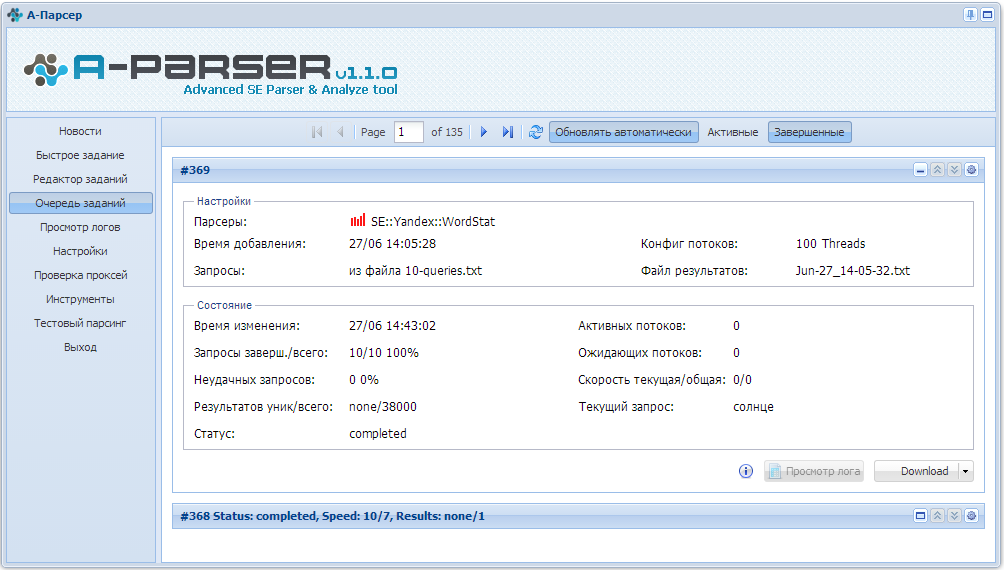
Зачем люди пишут парсеры
Немного отклонившися от курса этой статьи, на живом примере расскажу, где из популярных сайтов используется регулярный парсинг и наполнение с другого более популярного сайта.
Существует один сайт, уверен, на который вы натыкались в гугле при поиске решений проблем при программировании — qaru.site. И идея этого сайта как раз и строится на основу двух парсеров. Первый из которых копирует вопросы со всей информацией с популярного англоязычного сайта-аналога stackoverflow.com. А задача второго — переводить текст вопроса и ответов с английского на русский (с первого взгляда кажется, что это производится через Google Translate).
То, есть, если рассматривать роль парсера в проекте qaru.site, то, без раздумий можно утверждать то, что парсер в этом проекте — это 80% его успеха. Ведь, вместо того, чтобы развивать свой форум с нуля, просто было скопировано большое количество реальной информации с другого сайта. И из-за того, что эта информация в оригинале была на английском, то, со стороны поисковых систем её перевод расценивается как условно-полностью уникальный текст (невзирая на то, что перевод постов там сродни «я твой дом труба шатать»).
Но, это только один пример, придуманный сходу. На самом же деле, парсеры используются почти в каждом проекте: для наполнения сайта данными, для актуализации и обновления. Потому, их применение достаточно широко, и интересно. Потому знать, как писать парсер на php нужно. А если вы ещё освоите многопоточный парсинг, то жизнь станет ещё проще ^^.
Причина №1. Не могу разобраться самостоятельно
Даже если сначала в онлайн-обучении программированию всё шло гладко (так обычно и бывает с лёгкими темами), с усложнением материала всегда есть вероятность где-то зависнуть. Новичку может быть трудно разобраться в том материале, который опытный программист щелкает, как орешки. Просто потому, что мозг ещё не натренировался мыслить категориями языка программирования.
Что делать?
Для джунов, которые заблудились в дебрях программирования, в сети созданы программистские форумы типа Quora или StackOverflow. Есть и более специализированные ресурсы для «носителей» определённого языка программирования.
При прохождении онлайн-курсов обычно организуют пространство, где можно задать вопросы или попросить помощи с заданиями. Мы сделали так же: на JavaRush есть раздел «Помощь» — это так называемый «коллективный разум» студентов и нас, разработчиков этого Java-ресурса. В этом разделе вы можете задать конкретный вопрос, касающийся решения задачи из курса.
А те, кто совсем не справляется самостоятельно в изучении программирования, могут дать объявление о поиске ментора или попросить помощи в изучении сложной темы в разделе «Форум».
Интеграция 1С с ГИИС ДМДК
ГИИС ДМДК — единая информационная платформа для взаимодействия участников рынка драгоценных металлов и драгоценных камней. с 01.09.21 стартовал обязательный обмен данными с Федеральной пробирной палатой (ФПП) исключительно через ГИИС. А постепенно — с 01.01.2022 и с 01.03.2022 — все данные о продаже драгоценных металлов и камней должны быть интегрированы с ГИИС.
У многих пользователей возникает вопрос как автоматизировать обмен между программой 1С и ГИИС ДМДК.
В настоящей статье ВЦ Раздолье поделится своим опытом о реализации такого обмена.
Автор статьи — Мордовин Антон — архитектор систем на базе 1С Внедренческого центра «Раздолье».
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price.text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings.text)
#
# #
# # print(len(containers))
# print(container.div.img)
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratings\n"
f.write(headers)
for container in containers:
product_name = container.div.img
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container.text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container.text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee
split_price = add_rs_price.split("E")
final_price = split_price
split_rating = str(ratings).split(" ")
final_rating = split_rating
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"\n")
f.close()
Выход:
Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Почему и зачем использовать веб-парсинг?
Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
Динамический мониторинг цен
Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
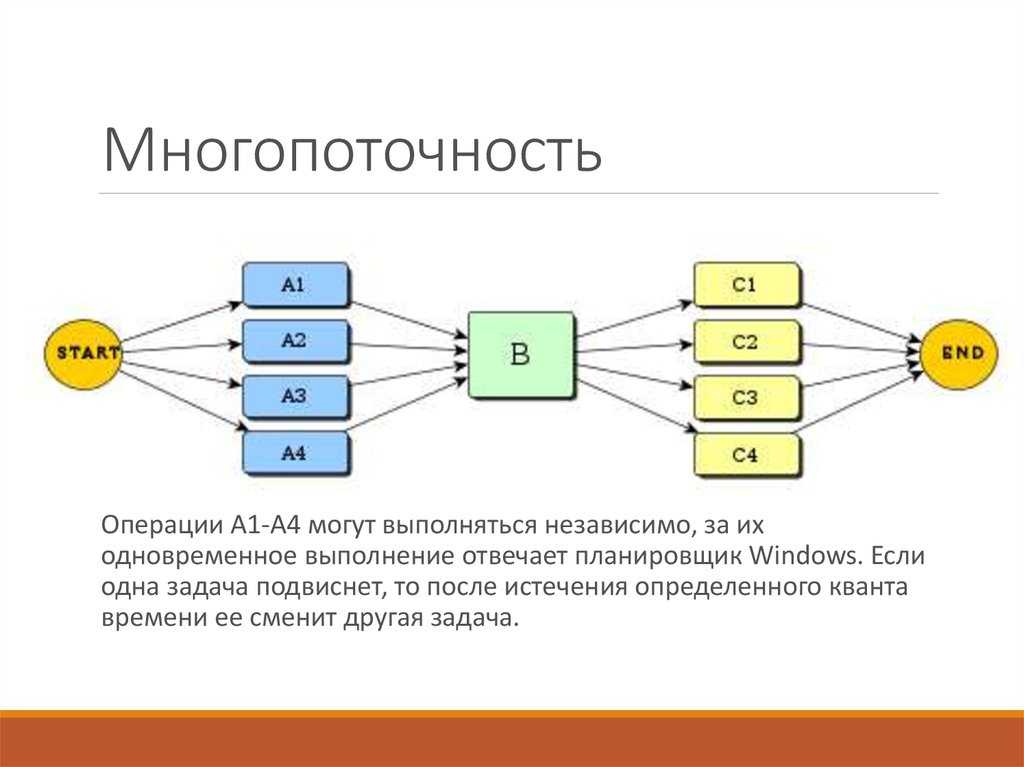
Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Причина №4. Прокрастинация
Вместо учебы убираете квартиру или смотрите сериалы (шпилите в игры или что угодно ещё), а учебный проект пишете в последнюю ночь перед дедлайном? Если вы узнали в этом себя, то вас одолела прокрастинация. Кстати, по словам ученых, прокрастинация — это не синоним лени, а скорее откладывание дел до последнего. Зачастую прокрастинацией страдают люди, склонные к перфекционизму. Это можно объяснить тем, что перфекционисты склонны доводить результат до совершенства. Когда ты сам от себя требуешь идеала, облажаться и правда становится страшно.
Что делать?
Не бросить обучение из-за прокрастинации может помочь дробление большого важного дела (например «выучить программирование») на более мелкие («пройти новую тему»). Ещё один способ — это так называемый «волшебный пендель», то есть регулярные напоминания о том, что пора заниматься
Конечно, мы не могли в требованиях для курса написать «завербовать человека для напоминания» (вместо этого мы добавили менторов :D) и нам нужно было универсальное решение. Так появился «График пинков» на JavaRush: там можно установить уведомления на нужные дни:
Ещё один способ — это так называемый «волшебный пендель», то есть регулярные напоминания о том, что пора заниматься. Конечно, мы не могли в требованиях для курса написать «завербовать человека для напоминания» (вместо этого мы добавили менторов :D) и нам нужно было универсальное решение. Так появился «График пинков» на JavaRush: там можно установить уведомления на нужные дни:
В борьбе с прокрастинацией помогает и определение чекпоинтов: можно выставлять контрольные точки по времени (работать 45 минут, а 15 минут отдыхать) или по задачам (решить 3 задачи, а потом сделать перерыв).
Просмотр через браузер
Если на компьютере вдруг не оказалось ни одного текстового редактор, или XML не открывается в читаемом виде, можно воспользоваться браузером или посмотреть содержимое файла онлайн.
Браузеры
Все современные браузеры поддерживают чтение формата XML. Однако нужно понимать, что раз в документе нет сведений о том, как отображать данные, веб-обозреватели показывают их «как есть». Чтобы использовать для открытия браузер (на примере Chrome):
- Щелкните правой кнопкой по XML-файлу. Выберите «Открыть с помощью».
- Если веб-обозревателя нет в списке приложений, которые можно использовать для просмотра файла, нажмите «Выбрать программу».
- Если в появившемся окне тоже не будет обозревателя, кликните по кнопке «Обзор».
- Пройдите к исполняемому файлу обозревателя в папке Program Files (Chrome по умолчанию устанавливается в этот каталог, но если вы меняли место инсталляции, то используйте другой путь).
- Выберите chrome.exe и нажмите «ОК».
Аналогичным образом запуск выполняется через другие браузеры. В обозревателе откроется новая вкладка, внутри которой отобразится содержимое документа XML.
В Mozilla Forefox можно открыть файл другим способом:
- Щелкните правой кнопкой по верхней панели. Отметьте пункт «Панель меню».
- Раскройте раздел «Файл». Нажмите «Открыть файл».
- Найдите документ XML через проводник и нажмите «Открыть».
Если файл поврежден, то браузер при попытке открыть документ может вывести сообщение об ошибке. В таком случае рекомендуется воспользоваться одним из редакторов XML, указанных выше.
Онлайн-сервис
Просмотреть и отредактировать XML-файл можно на онлайн-сервисе xmlgrid.net. Порядок работы такой:
- Откройте страничку онлайн-редактора, нажмите «Open File».
- Щелкните по кнопке «Выберите файл» и укажите путь к документу. Нажмите «Submit».
На странице отобразится содержимое документа. Вы можете его просматривать и редактировать прямо в окне браузера. Есть и другие онлайн-сервисы — например, CodeBeautify, XML Editor от TutorialsPoint. Так что файл XML при любом раскладе будет прочитан и отредактирован, если у пользователя возникнет такое желание.
Встроенные расширения XML
Я предпочитаю использовать одно из встроенных расширений XML поскольку они идут в комплекте с PHP и обычно быстрее, чем все сторонние библиотеки, и дают мне весь необходимый контроль над разметкой.
DOM
Расширение DOM позволяет вам работать с XML-документами через DOM API с PHP 5. Это реализация W3C Document Object Model Core Level 3, независимого от платформы и языка интерфейса, который позволяет программам и скриптам динамически получать доступ и обновлять содержание, структуру и стили.
DOM может анализировать и изменять реальный (или поврежденный) HTML и выполнять запросы XPath. Он основан на libxml.
Требуется потратить некоторое время, чтобы продуктивно работать с DOM, но это того стоит. Поскольку DOM — это не зависящий от языка интерфейс, вы найдете реализации на многих языках, поэтому, если вам нужно изменить язык программирования, скорее всего, вы уже будете знать, как использовать DOM API этого языка.
XMLReader
Расширение XMLReader — это синтаксический анализатор XML. Reader действует как курсор, движущийся вперед по потоку документа и останавливающийся на каждом узле по пути.
XMLReader, как и DOM, основан на libxml. Я не знаю, как активировать модуль HTML-синтаксического анализатора, поэтому вероятность использования XMLReader для разбора поврежденного HTML может быть менее надежной, чем использование DOM, где вы можете явно указать, как ему использовать модуль синтаксического анализатора HTML libxml.
XML Parser
Это расширение позволяет создавать синтаксические анализаторы XML, а затем определять обработчики для различных событий XML. У каждого анализатора XML также есть несколько параметров, которые вы можете настроить.
Библиотека XML Parser также основана на libxml и реализует push-синтаксический анализатор XML в стиле SAX. Это может быть лучшим выбором для управления памятью, чем DOM или SimpleXML, но с ним будет труднее работать, чем с синтаксическим анализатором, реализованным в XMLReader.
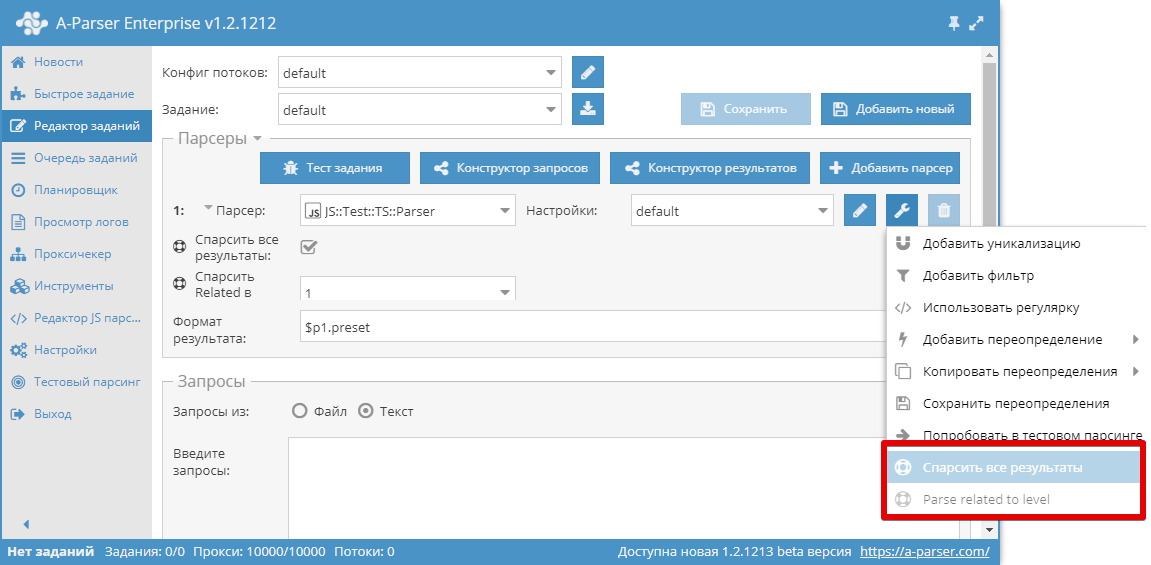
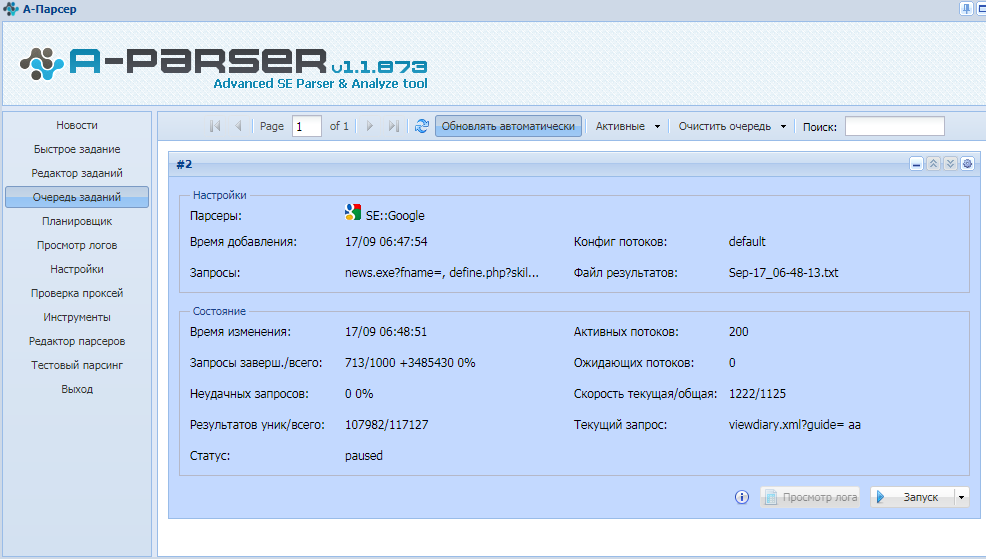
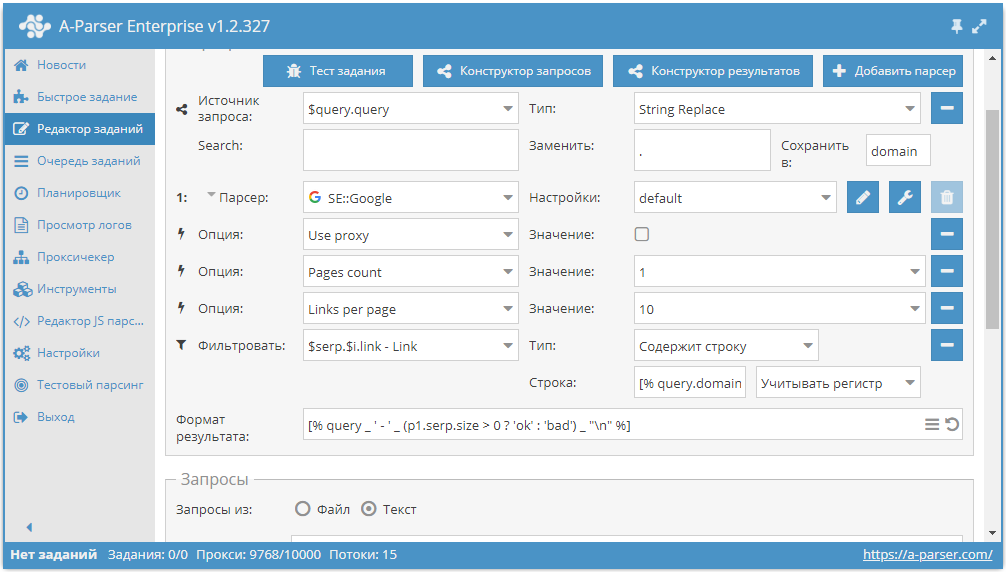
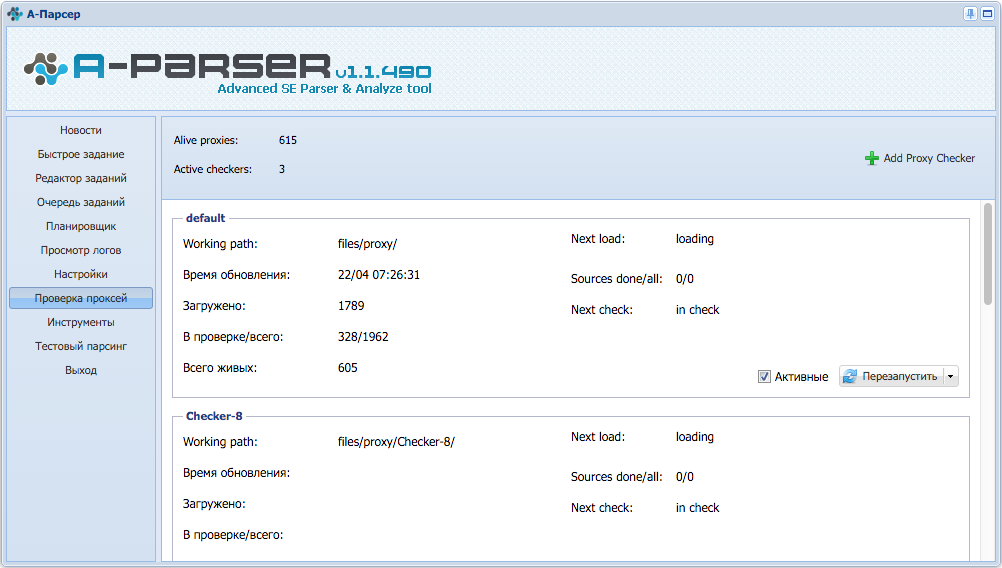
SimpleXml
Расширение SimpleXML предоставляет очень простой и удобный в использовании набор инструментов для преобразования XML в объект, который можно обрабатывать с помощью обычных селекторов свойств и итераторов массивов.
SimpleXML — это вариант, когда вы знаете, что HTML является допустимым XHTML. Если вам нужно проанализировать поврежденный HTML, даже не рассматривайте SimpleXml, потому что он не справится.
Чем открыть расширение XML?
Такой файл может создаваться совершенно разными программами, и он используется для обмена данными или для создания баз данных . Этот файл представляет собой текстовый документ, где все данные разделены с помощью тегов. Он очень похож на HTML, только теги задаёт сам пользователь, их количество не ограничено. Но как открыть XML-файл в читаемом виде?
Рассмотрим несколько возможных способов:
Редактировать файл можно очень легко в любом из доступных вам инструментов, описанных выше. То есть можно использовать и блокноты, и Excel. Но конечно же, лучше использовать специализированное программное обеспечение, например, XML Marker. Его можно бесплатно скачать, затем установить на свой компьютер или ноутбук.
Расширение.xml присуще файлам с текстовыми данными в формате XML.
Изначально язык создавался для использования во «всемирной паутине». Разработчики хотели сделать из него достойную замену HTML, но задумка у них не получилась. В результате XML оказался на своем теперешнем месте. Расширяемым языком разметки eXtensible Markup Language описывается документ и софт (реже), который выполняет чтение таких файлов.
Язык XML имеет простой синтаксис. Его удобно использовать в процессе создания документов для быстрой обработки в программах качественного чтения в интернете. Разработчики выбирают этот язык за его простоту, расширяемость, удобство. Заметим, что XML базируется на кодировках Юникод. Язык имеет способность к свободному расширению разметки (ограничения есть только в синтаксических правилах языка), поэтому он и называется расширяемым. Разработчик сможет применить его для решения почти любых задач.
Сейчас XML приобрел огромную популярность в Интернете. Нередко это расширение используется в документообороте. Заметим, что именно XML стал «прародителем» многих современных форматов, например, (знаком любителям электронных книг) или YML.
Как совершить процесс открытия?
Многие спрашивают, какие есть программы для чтения файлов XML формата, открыть его можно в браузере. Для этого можно использовать, например, Mozilla Firefox (в этом случае нужно выбрать версию с плагином XML Viewer) или Internet Explorer. Чтобы просмотреть файл, который имеет расширение.xml, на своем компьютере через браузер, нужно запустить его, нажать комбинацию клавиш «Ctrl+O» (если ваш ПК управляется операционной системой MacOS, то нужно использовать сочетание клавиш «Command+O»). После этого вы выбираете тот xml-файл, который вам необходим, и нажимаете «ENTER». Любой документ, который имеет расширение.xml, также открывается с помощью текстового редактора. Например, в просмотре и редактировании вам поможет notepad. Разработчики такого расширения рекомендуют открывать xml-файл с использованием такого софта, для которого он был создан.
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки
Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы
Для удобства также приводим ссылку на оригинал (на английском языке).
Вероятно, вы слышали о языке XML и вам известно множество причин, по которым его необходимо использовать в вашей организации. Но что именно представляет собой XML? В этой статье объясняется, что такое XML и как он работает.
Dealing With Namespaces
Many times you’ll encounter namespaced elements while working with XML from different web services. Let’s modify our example to reflect the usage of namespaces:
Now the element is placed under the namespace which points to http://purl.org/dc/elements/1.1/. If you try to print the creator of a language using our previous technique, it won’t work. In order to read namespaced elements like this you need to use one of the following approaches.
The first approach is to use the namespace URI directly in your code when accessing namespaced elements. The following example demonstrates how:
The method takes a namespace and returns the children of the element that are prefixed with it. It accepts two arguments; the first one is the XML namespace and the latter is an optional Boolean which defaults to false. If you pass true, the namespace will be treated as a prefix rather the actual namespace URI.
The second approach is to read the namespace URI from the document and use it while accessing namespaced elements. This is actually a cleaner way of accessing elements because you don’t have to hardcode the URI.
The method returns an array of namespace prefixes with their associated URIs. It accepts an optional parameter which defaults to false. If you set it true then the method will return the namespaces used in parent and child nodes. Otherwise, it finds namespaces used within the parent node only.
Now you can iterate through the list of languages like so:
Яндекс.XML лимиты
Лимит Яндекс.XML — ограничение на количество запросов к базе поисковой системы. Каждому подтвержденному в вебмастере сайту поисковая система выделяет определенное количество лимитов, это число зависит от качества сайта.
Обращаем ваше внимание, если право на управление сайтом подтвердили несколько пользователей, лимиты получает только первый владелец сайта. Перейдем в раздел «Лимиты»
Здесь можно увидеть общее количество лимитов в день, а также количество лимитов по подтвержденным сайтам
Перейдем в раздел «Лимиты». Здесь можно увидеть общее количество лимитов в день, а также количество лимитов по подтвержденным сайтам.
![]()
Также существует ограничение по количеству отправляемых запросов в сутки. Внизу страницы представлена диаграмма, в которой указано количество лимитов, которое можно потратить каждый час.
![]()
Работа с DOM документа
Страница фильма, которую мы парсим не требует никакой авторизации. Если посмотреть на исходный код этой страницы, то можно увидеть, что все данные, за которыми мы охотимся, доступны внутри HTML. Иногда бывают случаи, когда анализ сайта, его противопарсинговые защиты, обход алгоритмов защиты и т.д. занимают на порядок больше времени, чем написание самого кода парсера.
Теперь, когда мы научились получать ответ (содержимое WEB-страницы), можем начать работу с DOM-ом этого документа. Для этого, как я и ранее писал, я буду использовать Didom, подробнее о котором вы можете почитать здесь.
Для начала работы, нужно создать экземпляр класса , конструктор которого принимает HTML-разметку.
Внутри обработчика мы создали экземпляр класса , передав ему HTML-ответ, приведённый к строке. Теперь, нужно выбрать нужные данные, используя соответствующие CSS-селекторы.
Заголовки (Title, Alternative Title)
Заголовок может быть получен с тега h1 (который единственнный на всей странице).
Метод ищет первый элемент, соответствующий указанному селектору. После чего, к найденного элемента вызывается метод , который возвращает текст, содержащийся в этом элементе. Навигация и парсинг DOM-дерева выглядит очень похожим с jQuery:
![]()
Таблица параметров
Такие параметры фильма, как , , и т.д. находятся в таблице с классом .![]()
А ещё из разметки можно увидеть, что нужные нам параметры находятся во втором столбце (td) каждой из строк таблицы (tr). Но, нам не нужно сильно запариваться по поводу парсинга информации, так как можно увидеть, что в каждой строке таблицы есть только по одной ссылке, которые, как раз таки, и содержат внутри себя текст параметров.
Для этого, напишем код, получая сначала все строки таблицы, а потом обращаясь к ним по индексу:
Время и рейтинг (time, rating)
Информация о времени находится в той же таблице, которую парсили в прошлом шаге. Для получение данных, можно, как и в прошлом коде, обратиться по индексу:
Однако, изучив детальнее, можно увидеть, что у блока «время» есть уникальный идентификатор runtime, которым мы и воспользуемся.![]()
И в этом случае, код будет выглядеть:
И, аналогично поступим с рейтингом. Он, правда, не имеет тега id, однако, класс блога рейтинга уникальный, и не повторяется на странице, потому будем обращаться по нему:![]()
Итого, код парсера будет выглядеть так:



