
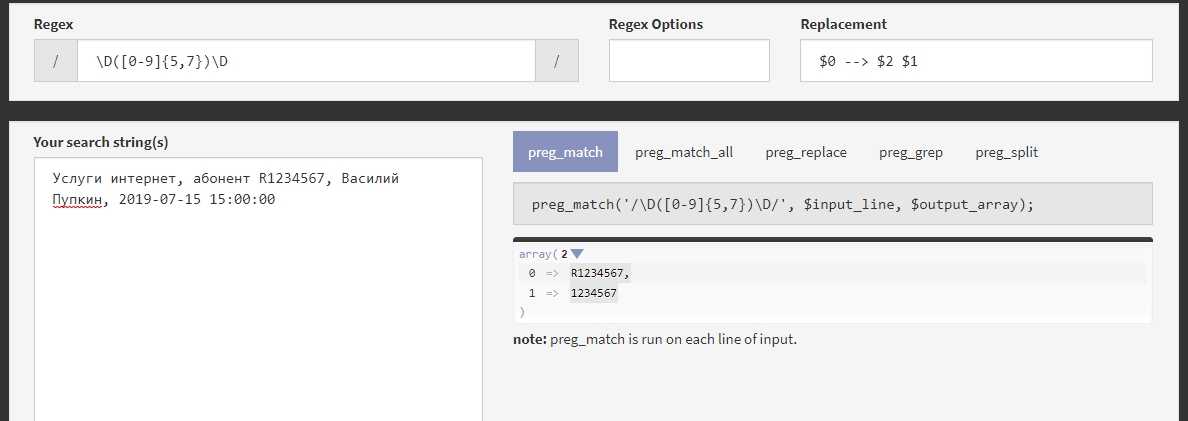
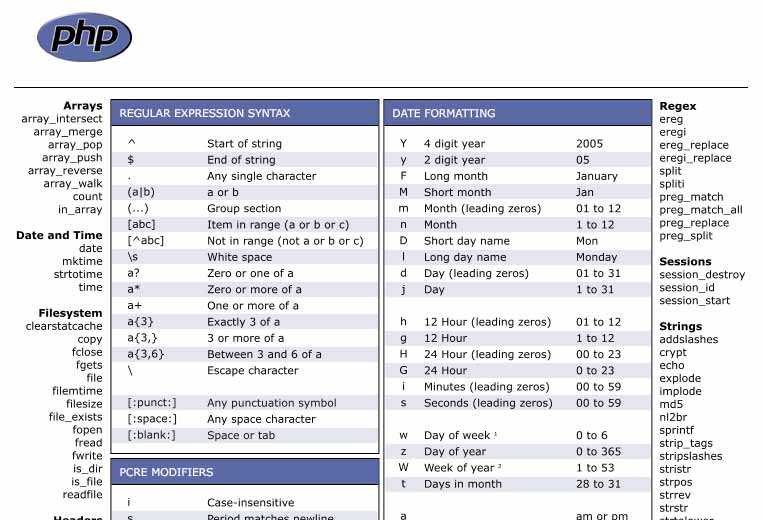
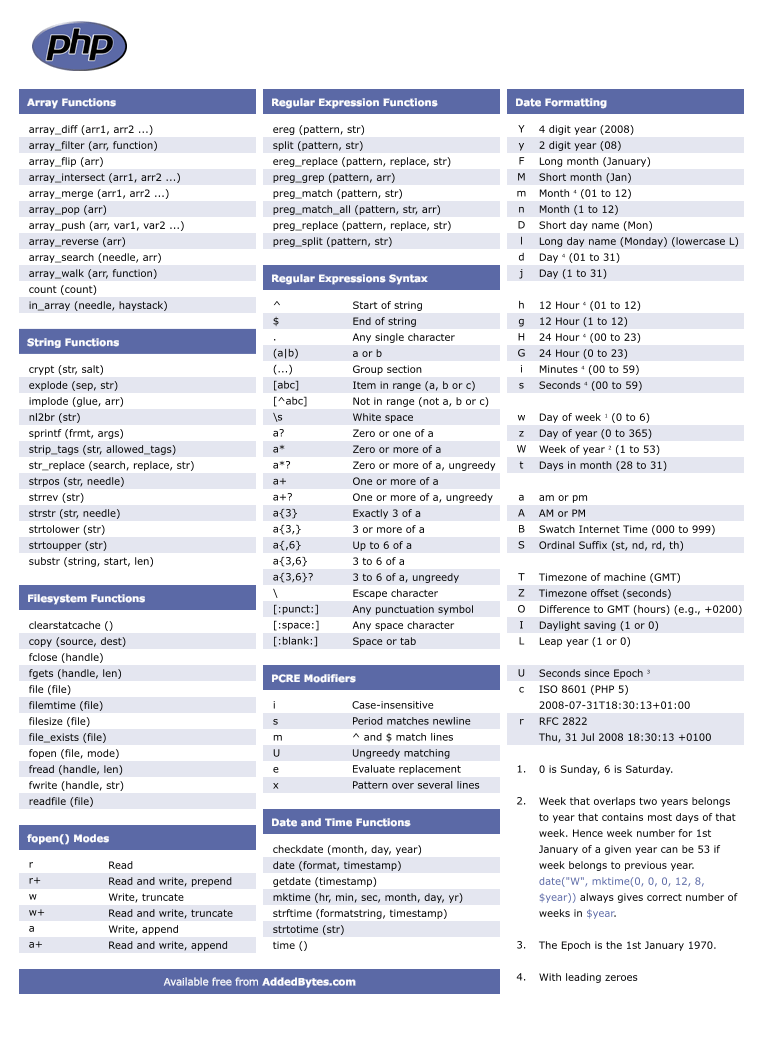
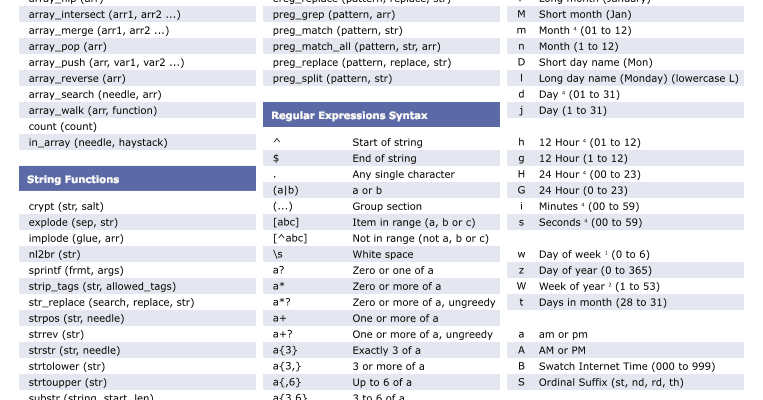
ereg( )
Функция еrеg( ) ищет в заданной строке совпадение для шаблона. Если
совпадение найдено, возвращается TRUE, в противном случае возвращается FALSE.
Синтаксис функции ereg( ):
int ereg (string шаблон, string строка )
Обратите внимание: из-за присутствия служебного символа $ регулярное
выражение совпадает только в том случае, если строка завершается символами .com. Например, оно совпадет в строке «www.apress.com», но не совпадет в строке
«www.apress.com/catalog»
Необязательный параметр совпадения содержит массив совпадений для всех
подвыражений, заключенных в регулярном выражении в круглые скобки. В листинге
показано, как при помощи этого массива разделить URL на несколько сегментов.
Вывод элементов массива $regs $url = «http://www.apress.com»; //
Разделить $url на три компонента: «http://www». «apress» и «com» $www_url =
ereg(«^(http://www).(+.(]+)». $url, $regs); if
($www_url) : // Если переменная $www_url содержит URL echo $regs; // Вся
строка «http://www.apress.com» print «<br>»; echo $regs; //
«http://www» print «<br>»; echo $regs; // «apress» print
«<br>»; echo $regs; // «com» endif;
При выполнении сценария будет получен следующий результат:
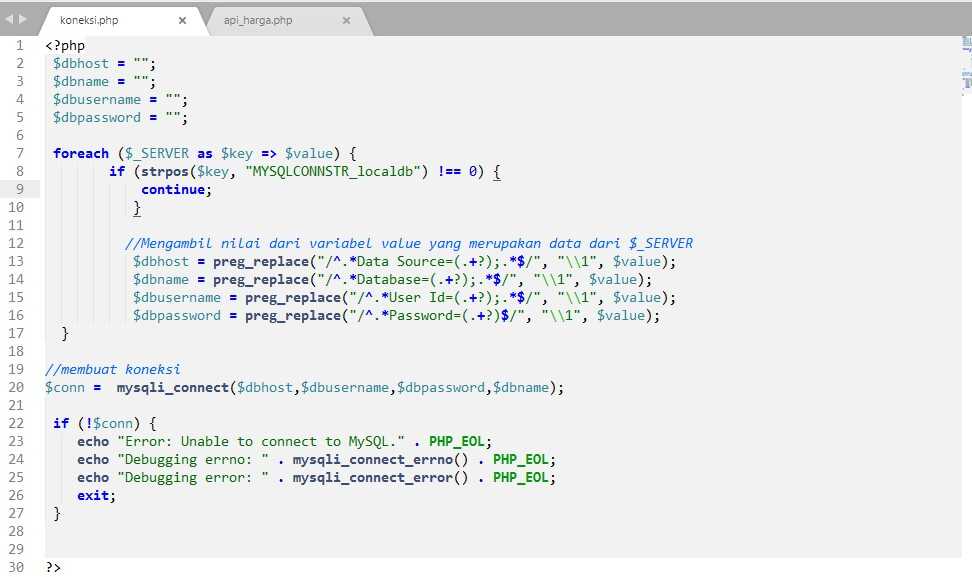
http://www.apress.com http://www apress com
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли «Я хочу найти/заменить/удалить то-то и то-то». Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101.com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
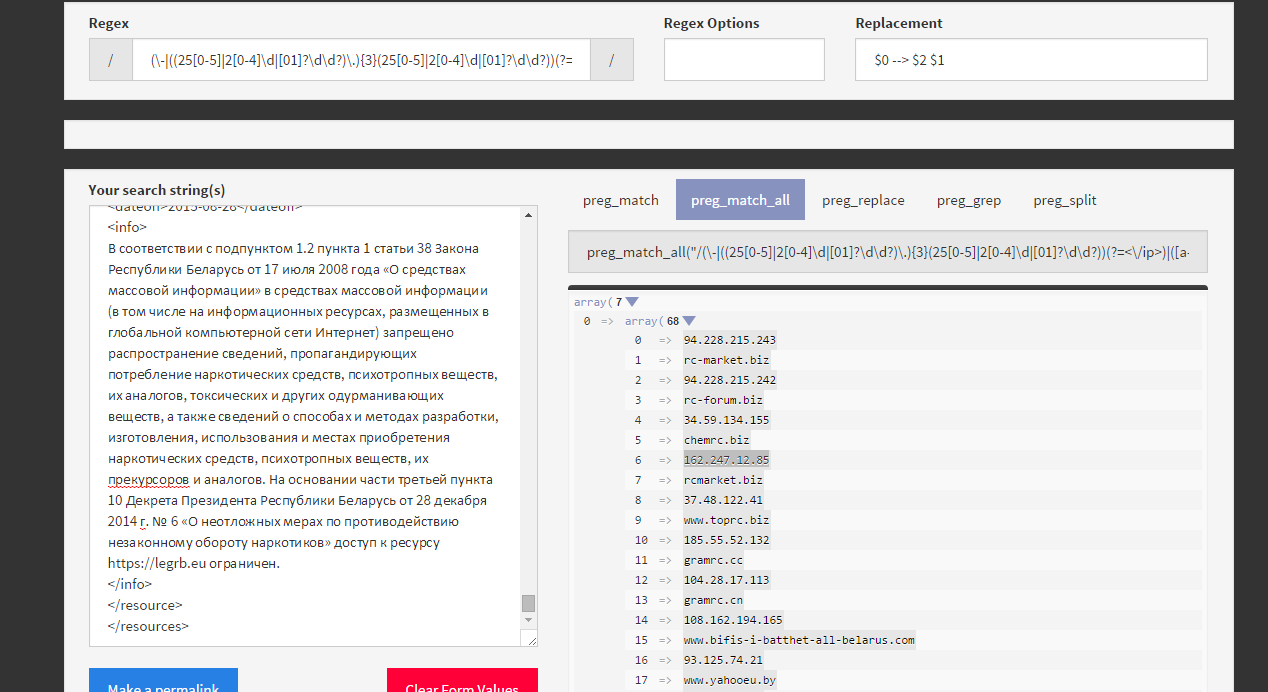
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: «Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?». Затем нужен список валидных и невалидных адресов:
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой — любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
Обратите внимание, что я использовал границу слова \b, чтобы искать полные байты. Пробуем регулярку в деле:
![]()
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
Результат выглядит так:
![]()
Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Модификаторы
Доступны несколько модификаторов, которые могут облегчить вашу работу с регулярными выражениями , например, чувствительность к регистру, поиск по нескольким линиям и т.д.
| Модификатор | Описание |
|---|---|
| i | Делает регистр без учета регистра |
| m | Указывает, что если строка имеет новую строку или каретку возвращаемые символы, теперь будут выполняться операторы ^ и $ сопоставление с границей новой строки, а не граница строки |
| o | оценивает выражение только один раз |
| s | Позволяет использовать. для соответствия символу новой строки |
| x | Позволяет использовать пробел в выражении для ясности |
| g | Глобально находит все совпадения |
| cg | Позволяет продолжить поиск даже после сбоя глобального соответствия |
Прочие служебные символы
Служебные символы $ и ^ совпадают не с символами, а с определенными позициями
в строке. Например, выражение р$ означает строку, которая завершается символом
р, а выражение ^р — строку, начинающуюся с символа р.
- Конструкция совпадает с любым символом, не входящим в указаные
интервалы (a-z и A-Z). - Служебный символ . (точка) означает <любой символ>. Например,
выражение р.р совпадает с символом р, за которым следует произвольный символ,
после чего опять следует символ р.
Объединение служебных символов приводит к появлению более сложных выражений.
Рассмотрим несколько примеров:
- ^.{2}$ — любая строка, содержащая ровно два символа;
- <b>(.*)</b> — произвольная последовательность символов,
заключенная между <Ь> и </Ь> (вероятно, тегами HTML для вывода
жирного текста); - p(hp)* — символ р, за которым следует ноль и более экземпляров
последовательности hp (например, phphphp).
Иногда требуется найти служебные символы в строках вместо того, чтобы
использовать их в описанном специальном контексте. Для этого служебные символы
экранируются обратной косой чертой (). Например, для поиска денежной суммы в
долларах можно воспользоваться выражением $+, то есть
Обратите внимание на
обратную косую черту перед $. Возможными совпадениями для этого регулярного
выражения являются $42, $560 и $3
PHP regex exact word match
In the following examples we show how to look for exact word matches.
php> echo preg_match("/mother/", "mother");
1
php> echo preg_match("/mother/", "motherboard");
1
php> echo preg_match("/mother/", "motherland");
1
The pattern fits the words mother, motherboard and motherland.
Say, we want to look just for exact word matches. We will use the aforementioned
anchor and characters.
php> echo preg_match("/^mother$/", "motherland");
0
php> echo preg_match("/^mother$/", "Who is your mother?");
0
php> echo preg_match("/^mother$/", "mother");
1
Using the anchor characters, we get an exact word match for a pattern.
Базовые понятия[править]
Регулярные выражения используются для сжатого описания некоторого множества строк с помощью шаблонов, без необходимости перечисления всех элементов этого множества. При составлении шаблонов используется специальный синтаксис, поддерживающий обычно следующие операции:
- Перечисление
- Вертикальная черта разделяет допустимые варианты. Например, «gray|grey» соответствует gray или grey.
- Группировка
- Круглые скобки используются для определения области действия и приоритета операторов. Например, «gray|grey» и «gr(a|e)y» являются разными образцами, но они оба описывают множество, содержащее gray и grey.
- Квантификация
-
Квантификатор после символа или группы определяет, сколько раз предшествующее выражение может встречаться.
- {n,m}
- общее выражение, повторений может быть от n до m включительно.
- {n,}
- общее выражение, n и более повторений.
- {,m}
- общее выражение, не более m повторений.
- {n}
- общее выражение, ровно n повторений
- ?
- Знак вопроса означает 0 или 1 раз, то же самое, что и {0,1}. Например, «colou?r» соответствует и color, и colour.
- *
- Звёздочка означает 0, 1 или любое число раз ({0,}). Например, «go*gle» соответствует gogle, , gooogle, ggle, и др.
- +
- Плюс означает хотя бы 1 раз ({1,}). Например, «go+gle» соответствует gogle, и т. д. (но не ggle).
Конкретный синтаксис регулярных выражений зависит от реализации.
/Быть или не быть/ugi ¶
Синтаксис регулярных выражений прост и логичен. Он разделяется на символ-разделитель (он идёт в начале и конце выражения, обычно это /), шаблон поиска и необязательные модификаторы.

Формальный синтаксис такой:
Разделителем может быть любой символ, но обычно это или
Важно лишь то, чтобы шаблон начинался и заканчивался одним и тем же разделителем. В самом конце регулярных выражений идут модификаторы, которые нужны, чтобы менять логику работы шаблонов (например делать регистронезависимый поиск)
Давайте разберём выражение :
Данное регулярное выражение будет искать текст не зависимо от регистра по всему тексту неограниченное количество раз. Модификатор нужен для того, чтобы явно указать, что текст у нас в юникоде, то есть содержит символы, отличные от латиницы. Модификатор включает регистронезависимый поиск. Модификатор указывает поисковику идти до победного конца, иначе он остановится после первого удачного совпадения.
Регулярные выражения PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP.
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true, если совпадение найдено, и false, если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match, preg_split или PHP regexp replace:
<?php
имя_функции('/шаблон/',объект);
?>
, где
«имя_функции» — это либо preg_match, либо preg_split, либо preg_replace.«/…/» — косые черты обозначают начало и конец регулярного выражения.«‘/шаблон/’» — шаблон, который нам нужно сопоставить.«объект» — строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg match PHP
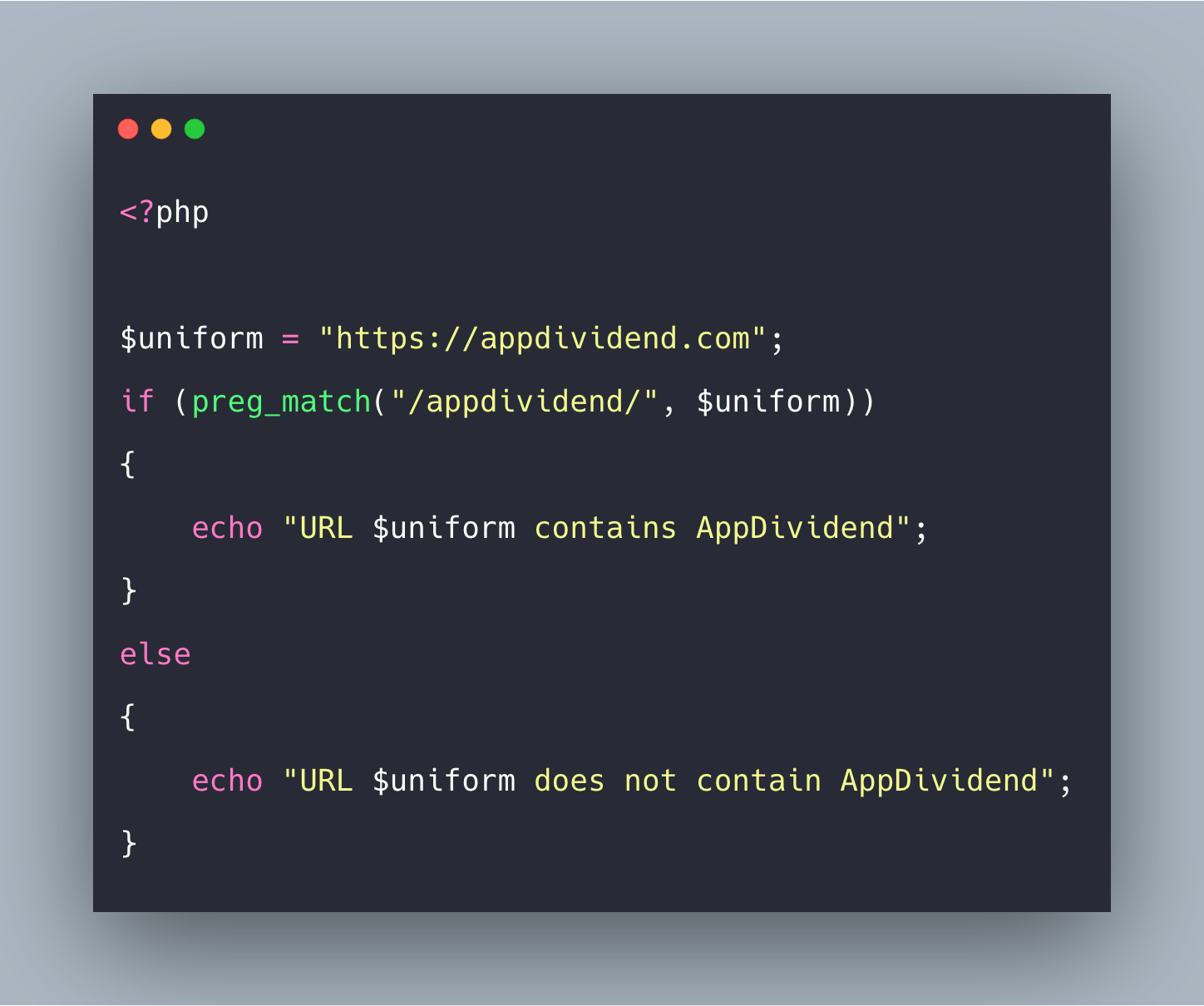
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе.
В приведенном ниже коде показан вариант реализации данного примера:
<?php
$my_url = "www.guru99.com";
if (preg_match("/guru/", $my_url))
{
echo "the url $my_url contains guru";
}
else
{
echo "the url $my_url does not contain guru";
}
?>
![]()
Рассмотрим ту часть кода, которая отвечает за вывод «preg_match (‘/ guru /’, $ my_url)».
Здесь:
«preg_match(…)» — функция PHP match regexp.«‘/Guru/’» — шаблон регулярного выражения.«$My_url» — переменная, содержащая текст, с которым нужно сопоставить шаблон.
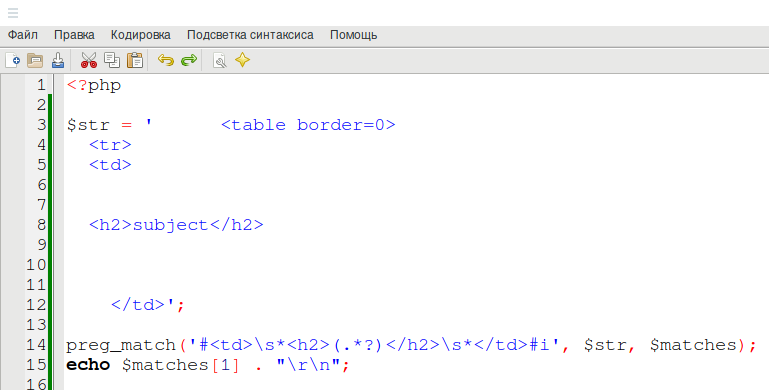
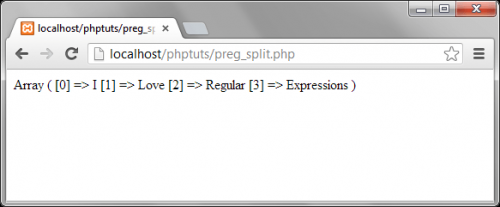
Preg split PHP
Рассмотрим другой пример, в котором используется функция preg_split.
Мы возьмем фразу и разобьем ее на массив; шаблон предназначен для поиска единичного пробела:
<?php
$my_text="I Love Regular Expressions";
$my_array = preg_split("/ /", $my_text);
print_r($my_array );
?>
![]()
Preg replace PHP
Рассмотрим функцию preg_replace, которая выполняет сопоставление с шаблоном и заменяет найденный результат другой строкой.
Приведенный ниже код ищет в строке слово guru. Он заменяет его кодом css, который задает цвет фона:
<?php
$text = "We at Guru99 strive to make quality education affordable to the masses. Guru99.com";
$text = preg_replace("/Guru/", '<span style="background:yellow">Guru</span>', $text);
echo $text;
?>
![]()
PHP regex subpatterns
We can use square brackets to create subpatterns
inside patterns.
php> echo preg_match("/book(worm)?$/", "bookworm");
1
php> echo preg_match("/book(worm)?$/", "book");
1
php> echo preg_match("/book(worm)?$/", "worm");
0
We have the following regex pattern: . The is
a subpattern. The ? character follows the subpattern, which means that the subpattern
might appear 0, 1 times in the final pattern. The character is here for
the exact end match of the string. Without it, words like bookstore, bookmania would match too.
php> echo preg_match("/book(shelf|worm)?$/", "book");
1
php> echo preg_match("/book(shelf|worm)?$/", "bookshelf");
1
php> echo preg_match("/book(shelf|worm)?$/", "bookworm");
1
php> echo preg_match("/book(shelf|worm)?$/", "bookstore");
0
Subpatterns are often used with alternation. The
subpattern enables to create several word combinations.
Скобки
Скобки ([]) имеют особое значение при использовании в контексте регулярных выражений. Они используются для поиска диапазона символов.
| # | Значение | Описание |
|---|---|---|
| Он соответствует любой десятичной цифре от 0 до 9. | ||
| Он соответствует любому символу от нижнего регистра a до нижнего регистра z. | ||
| Он соответствует любому символу в верхнем регистре A в верхнем регистре Z. | ||
| Он соответствует любому символу от нижнего регистра a до верхнего регистра Z. |
Диапазоны, показанные выше, являются общими; вы также можете использовать диапазон для соответствия любой десятичной цифре в диапазоне от 0 до 3 или диапазону , чтобы соответствовать любому строчному символу в диапазоне от b до v.
Основной синтаксис регулярных выражений в PHP
Чтобы использовать регулярные выражения, сначала вам нужно изучить синтаксис шаблонов. Мы можем сгруппировать символы внутри шаблона следующим образом:
- Обычные символы, которые следуют один за другим, например,
- Индикаторы начала и окончания строки в виде и
- Индикаторы подсчета, такие как , ,
- Логические операторы, такие как
- Группирующие операторы, такие как , ,
Пример шаблона регулярного выражения для проверки правильности адреса электронного ящика выглядит следующим образом:
^+@+\.{2,5}$
Код PHP для проверки электронной почты с использованием Perl-совместимого регулярного выражения выглядит следующим образом:
<?php
$pattern = "/^+@+\.{2,5}$/";
$email = "some-email@test.com";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Теперь давайте посмотрим на подробный разбор синтаксиса шаблона при регулярном выражении:
| Регулярное выражение (шаблон) | Проходит проверку (объект) | Не проходит проверку (объект) | Комментарий |
| Hello world | Hello Ivan | Проходит, если шаблон присутствует где-либо в объекте | |
| world class | Hello world | Проходит, если шаблон присутствует в начале объекта | |
| Hello world | world class | Проходит, если шаблон присутствует в конце объекта | |
| This WoRLd | Hello Ivan | Выполняет поиск в нечувствительном к регистру режиме | |
| world | Hello world | Строка содержит только «world» | |
| worl, world, worlddd | wor | Присутствует 0 или больше «d» после «worl» | |
| world, worlddd | worl | Присутствует по крайней мере одна «d» после «worl» | |
| worl, world, worly | wor, wory | Присутствует 0 или 1 «d» после «worl» | |
| world | worly | Присутствует одна «d» после «worl» | |
| world, worlddd | worly | Присутствует одна или больше «d» после «worl» | |
| worldd, worlddd | world | Присутствует 2 или 3 «d» после «worl» | |
| wo, world, worldold | wa | Присутствует 0 или больше «rld» после «wo» | |
| earth, world | sun | Строка содержит «earth» или «world» | |
| world, wwrld | wrld | Содержит любой символ вместо точки | |
| world, earth | sun | Строка содержит ровно 5 символов | |
| abc, bbaccc | sun | В строке есть «a», или «b» или «c» | |
| world | WORLD | В строке есть любые строчные буквы | |
| world, WORLD, Worl12 | 123 | В строке есть любые строчные или прописные буквы | |
| earth | w, W | Фактический символ не может быть «w» или «W» |
Теперь перейдем к более сложному регулярному выражению с подробным объяснением.
Метасимволы
В приведенных выше примерах использовались простые шаблоны. Метасимволы позволяют выполнять более сложные сопоставления шаблонов PHP regexp, такие как проверка адреса электронной почты. Рассмотрим часто используемые метасимволы.


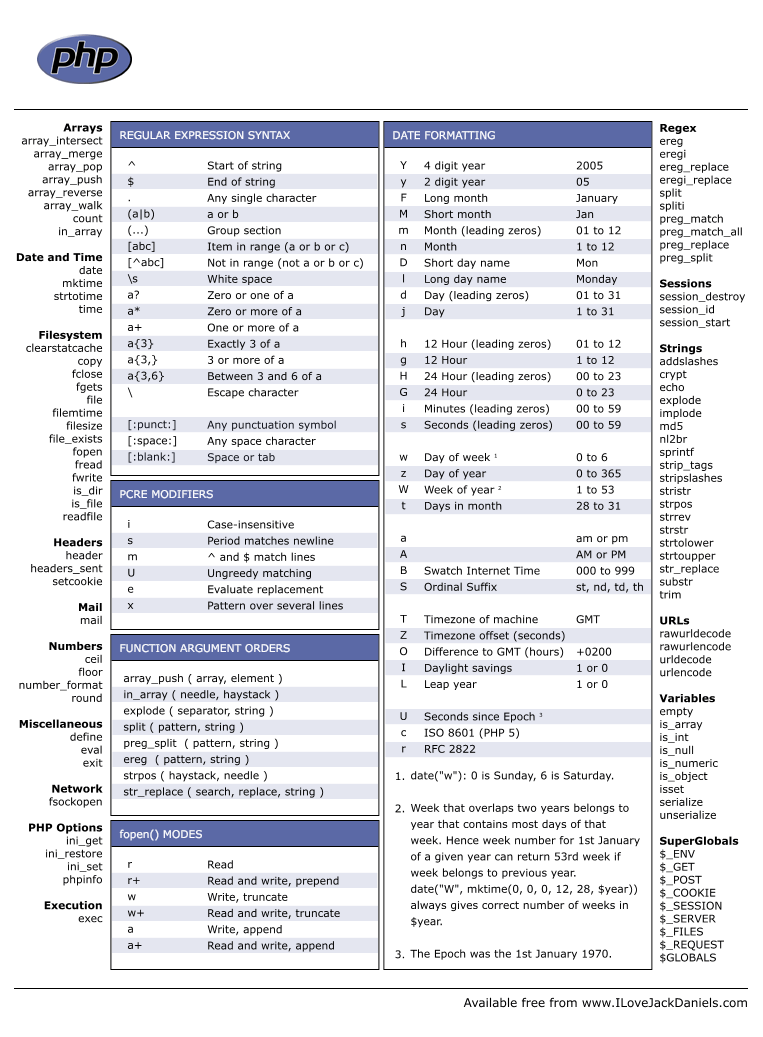

| Метасимвол | Описание | Пример |
| . | Обозначает любой единичный символ, кроме символа новой строки. | /./ — все, что содержит один символ. |
| ^ | Обозначает начало строки, не включая символ /. | /^PH/ — любая строка, которая начинается с PH. |
| $ | Обозначает шаблон в конце строки. | /com$/ — guru99.com,yahoo.com и т.д. |
| * | Обозначает любое количество символов, ноль или больше. | /com*/ — computer, communication и т.д. |
| + | Требуется вхождение перед метасимволом символа (ов) хотя бы один раз. | /yah+oo/ — yahoo. |
| Символ экранирования. | /yahoo+.com/ — воспринимает точку, как дословное значение. | |
| Класс символов. | // — abc. | |
| a-z | Обозначает строчные буквы. | /a-z/ — cool, happy и т.д. |
| A-Z | Обозначает заглавные буквы. | /A-Z/ — WHAT, HOW, WHY и т.д. |
| 0-9 | Обозначает любые цифры от 0 до 9. | /0-4/ — 0,1,2,3,4. |
Теперь рассмотрим сложный PHP regexp пример, в котором проверяется валидность адреса электронной почты:
<?php
$my_email = "name @ company . com"
if (preg_match("/^+@+.{2,5}$/", $my_email)) {
echo "$my_email is a valid email address";
}
else
{
echo "$my_email is NOT a valid email address";
}
?>
Результат: адрес электронной почты name@company.com является валидным.
Группы (подмаски)
Группировка добавляет функционал «обратных ссылок», которые дают возможность запоминать найденные группы символов под порядковыми номерами и обращаться к ним по этим номерам как по ссылкам. Для обращения к обратным ссылкам в «строке-шаблоне» используется обратный слэш и присвоенный номер группе (), а для обращения в «строке-замене» — знак доллара (). Для примера подставим закрывающий HTML-тег заголовка:
В некоторых случаях дополнительно к цифровым удобно использовать именованные группы ( или (), например для обработки динамических HTTP-роутов:
Встречаются ситуации, когда необходимо сгруппировать символы, но саму группу не запоминать. Для этого нужно после открывающейся скобки поставить знак вопроса и двоеточие ().
Существует еще «атомарная группировка« (). Она похожа на «ревнивую« квантификацию, точно также при первом найденном совпадении останавливает поиск в группе и является самой быстрой из группировок.
Подмаска дает возможность применять условия типа и :
- ;
- .
Также подмаску можно использовать для поиска конкретного фрагмента в целевой строке, по указанной подмаске будет производиться поиск, но при этом сама подмаска не будет включена в результат поиска.
| Формат | Название | Пример | Результат |
|---|---|---|---|
| Позитивный просмотр вперёд | .com example.org | ||
| Негативный просмотр вперёд | example.com .org | ||
| Позитивный просмотр назад | example. example. | ||
| Негативный просмотр назад | example.com example.org |
Классы символов¶
Пользовательские классы
Символьный класс — это список символов внутри . Класс соответствует любому одному символу, указанному в этом классе.
| RegEx | Находит |
|---|---|
| , и т. д., но не , и т. д. |
Вы можете класс — если первый символ после является , то класс соответствует любому символу, кроме символов, перечисленных в классе.
| RegEx | Находит |
|---|---|
| , и т. д., но не , и т. д. |
Внутри списка символ используется для указания диапазона, так что представляет все символы между и включительно.
Если вы хотите, чтобы сам был членом класса, поместите его в начало или конец списка или предварите его обратной косой чертой ().
Если вы хотите буквально использовать символ поместите его в начало списка или обратной косой чертой.
| RegEx | Находит |
|---|---|
| , и | |
| , и | |
| , и | |
| символы от до | |
| символы от до |
Как пользоваться регулярными выражениями
Регулярные выражения строятся по определенным правилам. Символы могут быть обычными — буквы, цифры, могут быть специальными — метасимволами, которые используются для задания шаблона строки.
![]()
Всегда можно обойтись исключительно обычными символами — просто перечислить те строковые выражения, которые нужны. Использование метасимволов позволит упростить работу со строками, сэкономить время и силы. Нужно лишь один раз понять, как работают регулярные выражения.
Символ звездочка “ * ”
Этот символ используется, когда необходимо указать произвольное число повторений предшествующего символа.
Пример: tr*ack — маска. Под нее подойдет набор символов tack — символа r нет; подойдет track — одно вхождение символа; подойдет trrrrrack — несколько вхождений символа, стоящего перед звездочкой.
Символ вопросительный знак “ ? ”
Метасимвол так же, как и звездочка, указывает на предстоящий символ. Вопросительный знак указывает, что литера может либо отсутствовать, либо присутствовать в строке.
Пример: под маску tr?ack подходит два варианта. tack — отсутствие символа, track — одно вхождение.
Символ плюс “+”
Этот спецсимвол означает, что предыдущий символ может повторяться неограниченное число раз.
Пример: под маску tr+ack подойдут так же track, trrack, trrrack и т. д.
Символ точка “ . “
Точкой обозначается один произвольный символ.
Пример: к строке tr.ack подойдут наборы tr1ack, trRack, tr7ack и т. д.
Символ крышка “ ^ ”
Данный метасимвол означает, что следующий за ним набор символов должен находиться в начале строки.
Пример: шаблону ^track будут удовлетворять строки track, track10, но строки вида 10track, rtrack.
Символ доллар “ $ ”
Метасимвол указывает на то, что предшествующие ему элементы должны быть в конце строки.
Пример: выражению track$ будут удовлетворять следующие строки: 5track, aaatrack, и не будут удовлетворять track5, trackaaa.
Символы в квадратных скобках “ ”
Квадратные скобки заключают в себя набор символов, для которых допустимо лишь одно вхождение в строку одного символа.
Пример: выражению track будет соответствовать строки track1 либо track0. Строки track10, track01 — нет.
Символы крышка в квадратных скобках “ ”
Такое сочетание специальных символов указывает на то, что литер из квадратных скобок в строке быть не должно.
Пример: регулярке будет соответствовать строка track, и не будут соответствовать строки track08, track1 и т. д.
Символ дефис “ — ”
Это символ используется для задания диапазона. Например, для выбора всех прописных букв латинского алфавита можно воспользоваться дефисом, как было показано в предыдущем примере. Надо помнить, что в регулярных выражениях мы имеем дело с символами. Строка “76” расценивается как символы “7” и “6”. И если нужно исключить, например, диапазон двухзначных чисел, нужно выносить символ за скобки.
Пример: для выбора диапазона чисел 23-29 регулярное выражение примет вид “2”.
Пример: это важный пример. При работе с Google Analytics часто возникает необходимость исключения определенных IP-адресов. Чтобы исключить адреса с 192.168.0.10 по 192.168.0.25, нужно воспользоваться маской 192\.168\.0\.(1|2).
Символ прямой слэш “ | ”
Вертикальный слэш означает логическую операцию ИЛИ. Применяется к группе символов, заключенных в круглые скобки. Выбирается либо выражение слева от метасимвола, либо справа.
Пример: в предыдущем примере мы выбирали диапазон чисел 10 — 25. Поскольку за скобки мы не можем одновременно вынести цифры 1 и 2, мы поступили так — (1|2).
Символы круглые скобки “ ( ) ”
Круглые скобки нужны, когда группу элементов нужно объединить в один символ.
Пример: регулярному выражению track(10)+ будет соответствовать строка track1010, track101010. Мы объединили символы “1” и “0” в одну группу “10”, а “+” указывает, что эта группа может повторяться произвольное число раз.
Символы фигурные скобки “ { } ”
В фигурных скобках задается число повторений последнего символа. Можно указать промежуток, например, “{2,4}” или неограниченное число повторений — “{2,}”.
Пример: маске (track){2} будет соответствовать строка “tracktrack”, а выражению (track){2,} — все строки tracktrack, tracktracktrack и т. д.
Для упрощения работы можно пользоваться конструкциями, которые сокращают запись регулярных выражений.
Эта конструкция ставится в соответствию любому символу и заменяет строку “”.
Этому сочетанию символов ставится в соответствие все символы, которые не входят в предыдущую группу — которые не являются буквами, цифрами или подчеркиванием “_”.
Функции регулярных выражений
PHP предоставляет программистам множество полезных функций, позволяющих использовать регулярные выражения. Рассмотрим некоторые функции, которые являются одними из наиболее часто используемых:
| Функция | Определение |
|---|---|
| preg_match() | Эта функция ищет конкретный образец в некоторой строке. Он возвращает 1 (true), если шаблон существует, и 0 (false) в противном случае. |
| preg_match_all() | Эта функция ищет все вхождения шаблона в строке. Она возвращает количество найденных совпадений с шаблоном в строке, или 0 — если вхождений нет. Функция удобна для поиска и замены. |
| ereg_replace() | Эта функция ищет определенный шаблон строки и возвращает новую строку, в которой совпадающие шаблоны были заменены другой строкой. |
| eregi_replace() | Функция ведет себя как ereg_replace() при условии, что поиск шаблона не чувствителен к регистру. |
| preg_replace() | Эта функция ведет себя как функция ereg_replace() при условии, что регулярные выражения могут использоваться как в шаблоне так и в строках замены. |
| preg_split() | Функция ведет себя как функция PHP split(). Он разбивает строку на регулярные выражения в качестве параметров. |
| preg_grep() | Эта функция ищет все элементы, которые соответствуют шаблону регулярного выражения, и возвращает выходной массив. |
| preg_quote() | Эта функция принимает строку и кавычки перед каждым символом, который соответствует регулярному выражению. |
| ereg() | Эта функция ищет строку, заданную шаблоном, и возвращает TRUE, если она найдена, иначе возвращает FALSE. |
| eregi() | Эта функция ведет себя как функция ereg() при условии, что поиск не чувствителен к регистру. |
Примечание:
- По умолчанию регулярные выражения чувствительны к регистру.
- В PHP есть разница между строками внутри одинарных кавычек и строками внутри двойных кавычек. Первые обрабатываются буквально, тогда как для строк внутри двойных кавычек печатается содержимое переменных, а не просто выводятся их имена.
Функция preg_match()
Функция выполняет проверку на соответствие регулярному выражению.
Пример. Поиск подстроки «php» в строке без учета регистра:
Попробуй сам
Результат выполнения кода:
Вхождение найдено.
В примере выше символ «i» после закрывающего ограничителя шаблона означает регистронезависимый поиск, поэтому вхождение будет найдено.
Примечание: Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Для этого используйте strpos() или strstr(), т.к. они выполнят эту задачу гораздо быстрее.



Функция preg_match_all()
Функция выполняет глобальный поиск шаблона в строке.
В примере регулярное выражение используется для подсчета числа вхождений «ain» в строку без учета регистра:
Попробуй сам
Результат выполнения кода:
3
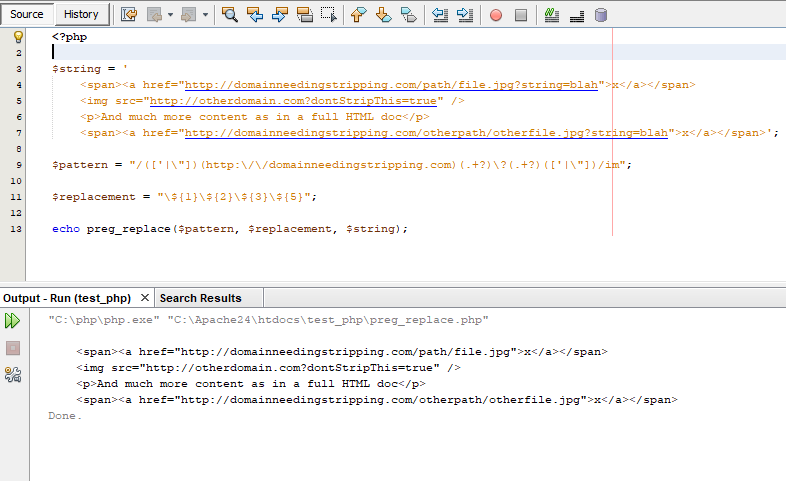
Функция preg_replace()
Функция выполняет поиск и замену по регулярному выражению.
В следующем функция выполняет поиск в строке совпадений с шаблоном pattern и заменяет их на replacement:



