
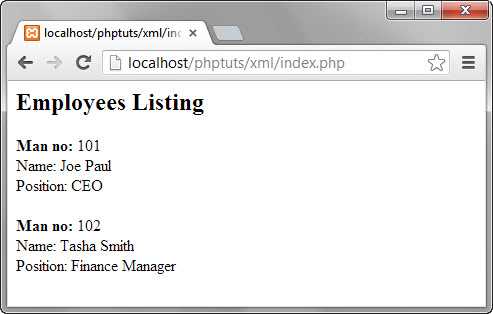
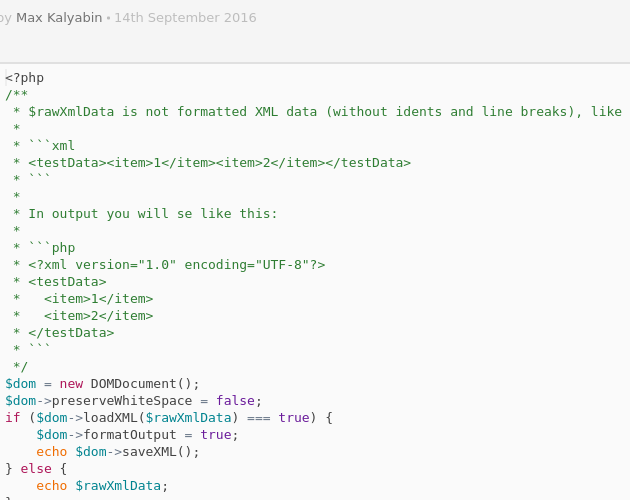
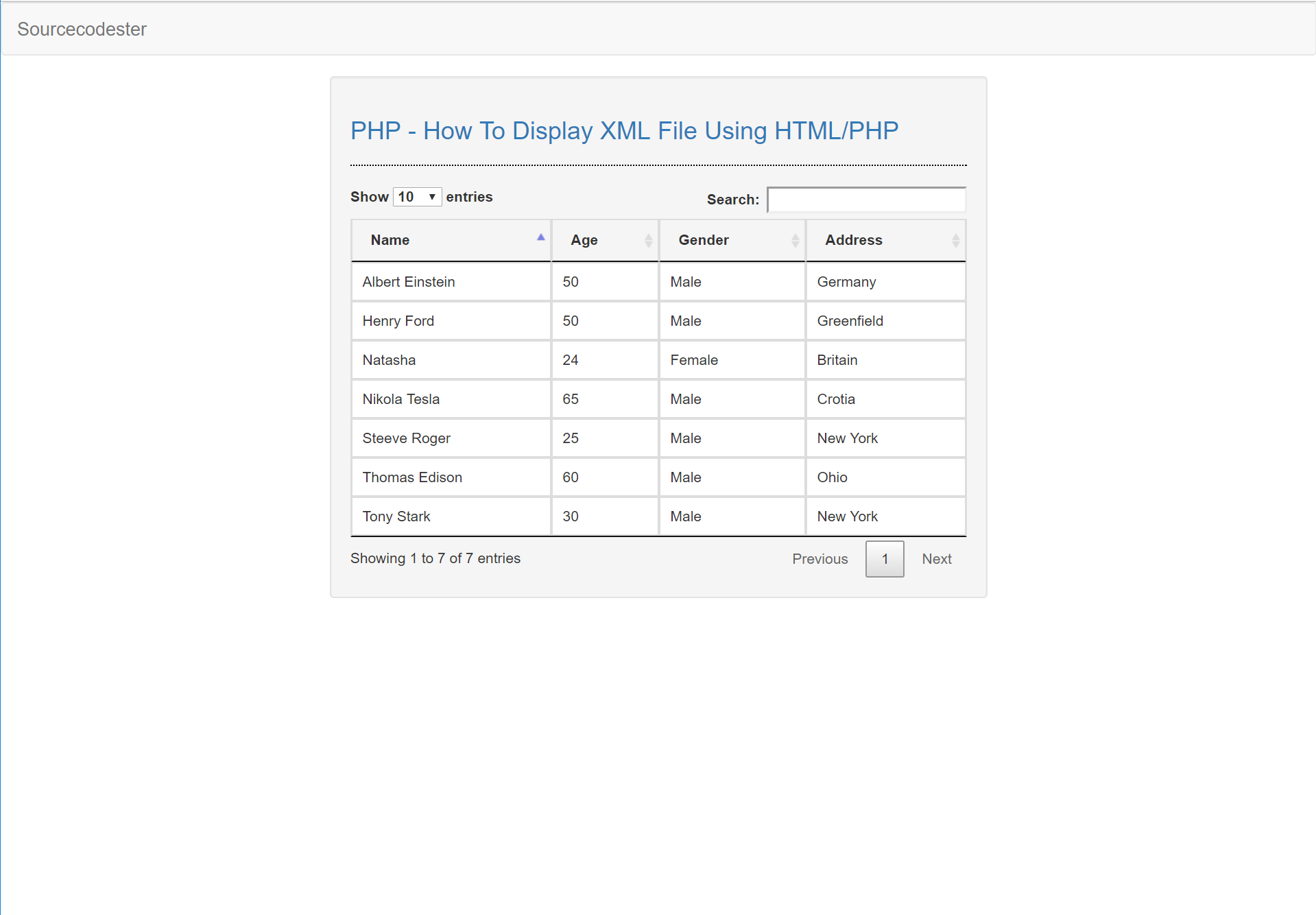
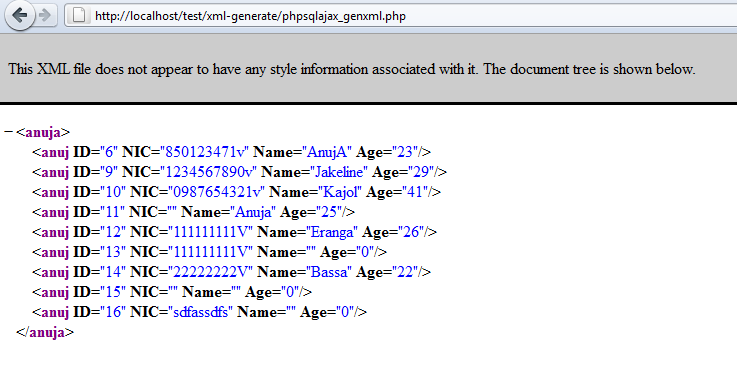
XML Document example
Let’s suppose that you are developing an application that gets data from a web service in XML format.
Below is the sample of how the XML document looks like.
<?xml version="1.0" encoding="utf-8"?>
<employees status = "ok">
<record man_no = "101">
<name>Joe Paul</name>
<position>CEO</position>
</record>
<record man_no = "102">
<name>Tasha Smith</name>
<position>Finance Manager</position>
</record>
</employees>
HERE,
- “<?xml version=”1.0″ encoding=”utf-8″?>” specifies the xml version to be used and encoding
- “<employees status = “ok”>” is the root element.
- “<record…>…</record>” are the child elements of administration and sales respectively.
Пространства имен для заметок
Такие заметки в XSD-схемах можно обозначить при помощи пространства имен, указанном в теге , например:
<xsd:schema xmlns:xsd="http://www.w3.org/2022/XMLSchema"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
...
</xsd:schema>
Префикс этого пространства имени можно записать произвольно для того, чтобы отличать их от других .
Пример схемы с заметками ():
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:annotation> <xs:appinfo>W3Schools Note</xs:appinfo> <xs:documentation xml:lang="en"> This Schema defines a W3Schools note! </xs:documentation> </xs:annotation> . . . </xs:schema>
Разобравшись с XSD более детально, становится понятно, что без него пользователю было бы очень неудобно работать с XML-документами.
Ну, а если вы хотите больше информации по рассматриваемой теме — вот несколько полезных ссылок на обучающие видеоролики, подробно объясняющие эту концепцию:
https://youtube.com/watch?v=RlHrfdzJwMM
https://youtube.com/watch?v=Bk9DfQd_EOs
https://youtube.com/watch?v=kvphrP8iZsY
Основные сайты и книги
Русскоязычные ресурсы:
- xmlhack.ru: Новости XML, статьи, советы, переводы, ссылки, XML FAQ, форумы.
- raleigh.ru: Учебники по XSLT, XPath, статьи, шлюз в fido7.ru.xml
- XML-форумы: Обсуждение вопросов, связанных с XML
- fido7.ru.xml: Конференция fido.
- Школы Консорциума W3C: Введение в основные XML-технологии.
- IBM developerWorks, XML: Русская версия
- Книги: Книги по XML на books.ru
В бумажном виде рекомендуем книгу Алексея Валикова «Технология XSLT». Она частично опубликована на сервере xmlhack.ru.
Прочее:
- ru_xml: ЖЖ-сообщество, посвящённое XML
- xhtml.ru: Сайт, посвящённый XHTML
- ru_xhtml: ЖЖ-сообщество, посвящённое XHTML
- Библиотека онтологий: Web-онтологии. Практика применения
- Технологии web-сервисов: Новости, статьи, форумы
Read Specific XML Elements
Use simplexml_load_file function to load external XML file in your PHP program and create an object. After that, you can access any element from the XML by this object as follows.
PHP
<?php
$xmldata = simplexml_load_file(«employees.xml») or die(«Failed to load»);
echo $xmldata->employee->firstname . «<\n>»;
echo $xmldata->employee->firstname;
?>
|
1 2 3 4 5 |
<?php $xmldata=simplexml_load_file(«employees.xml»)ordie(«Failed to load»); echo$xmldata->employee->firstname.»<\n>»; echo$xmldata->employee1->firstname; ?> |
Output:
Tom Tyler
If the XML file is available on the remote server, you can use HTTP URL for the XML file as followings:
PHP
<?php
$xmldata = simplexml_load_file(«https://tecadmin.net/employees.xml») or die(«Failed to load»);
echo $xmldata->employee->firstname . «<\n>»;
echo $xmldata->employee->firstname;
?>
|
1 2 3 4 5 |
<?php $xmldata=simplexml_load_file(«https://tecadmin.net/employees.xml»)ordie(«Failed to load»); echo$xmldata->employee->firstname.»<\n>»; echo$xmldata->employee1->firstname; ?> |
Отображение XML во Всемирной паутине
Наиболее распространены три способа преобразования XML-документа в отображаемый пользователю вид:
- Применение стилей CSS;
- Написание на каком-либо языке программирования обработчика XML-документа.
Без использования CSS или XSL XML-документ отображается как простой текст в большинстве Web-браузеров. Некоторые браузеры, такие как Internet Explorer (браузер), Mozilla и Mozilla Firefox отображают структуру документа в виде дерева, позволяя сворачивать и разворачивать узлы с помощью нажатий клавиши мыши.
Применение стилей CSS
Процесс аналогичен применению CSS к HTML документу для отображения.
Для применения CSS при отображении в браузере, XML документ должен содержать специальную ссылку на таблицу стилей. Например:
<source lang=»xml»>
<?xml-stylesheet type=»text/css» href=»myStyleSheet.css»?>
</source>
Это отличается от подхода HTML, где используется элемент <link>.
Применение преобразования XSLT
XSL является технологией, описывающей как форматировать или преобразовывать данные XML-документа. Документ трансформируется в формат, подходящий для отображения в браузере. Браузер — это наиболее частое использование XSL, но не стоит забывать, что с помощью XSL можно трансформировать XML в любой формат, например VRML, PDF, текст.
<source lang=»xml»>
<?xml-stylesheet type=»text/xsl» href=»transform.xsl»?>
</source>
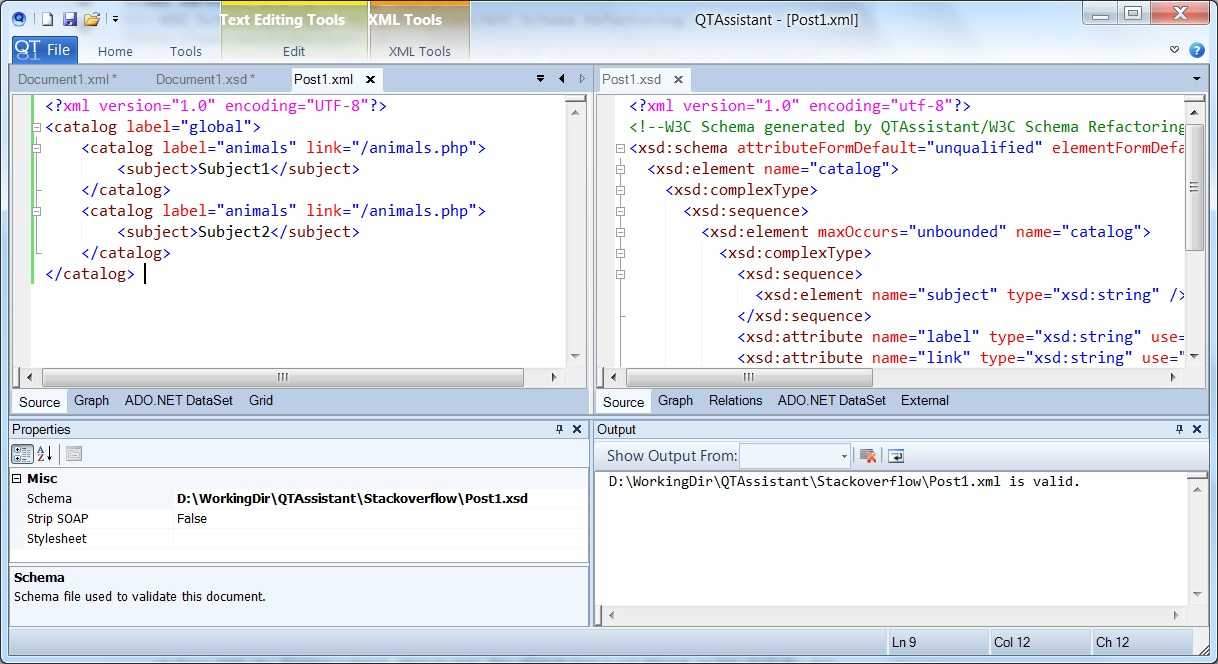
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
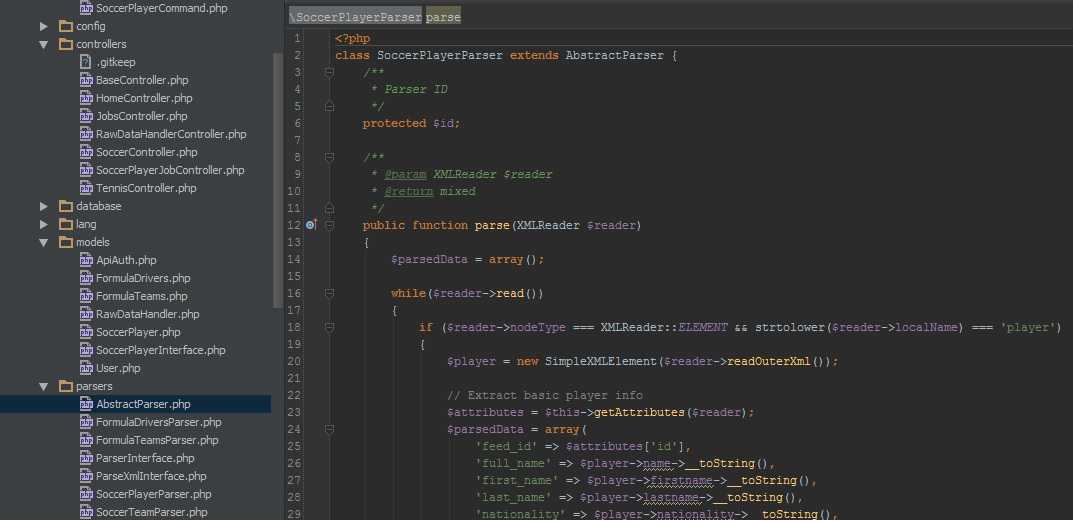




После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Подробнее об XSD смотрите:
- XML Schema
- XSD — умный XML
Примечание
Примером использования XSD cхем может служить электронная отчетность:
ФНС: Справочник налоговой и бухгалтерской отчетности
Повторное использование тега при XSLT трансформации
>>Есть хмл
>>
>> Maxim
>>
>> надо сделать из него Квитанцию и Уведомление.
>Я бы сделал так
>
>
>
>
>
>
>
>
>
> Уведомление-
>
>
>
> Квитанция-
>
>
>Обрати внимание, что есть и
>
В этом случае лучше использовать режимы:
<xsl:template match="root">
<xsl:apply-templates select="client" mode="kvit"/>
<xsl:apply-templates select="client" mode="uved"/>
</xsl:template>
<xsl:template match="client" mode="uved">
<xsl:text>Уведомление-</xsl:text><xsl:value-of select="."/>
</xsl:temlpate>
<xsl:template match="client" mode="kvit">
<xsl:text>Квитанция-</xsl:text><xsl:value-of select="."/>
</xsl:temlpate>
Разница небольшая, но с режимами — стиль лучше.
—
Aleksei Valikov
PHP XML Parser Introduction
The XML functions lets you parse, but not validate, XML documents.
XML is a data format for standardized structured document exchange. More
information on XML can be found in our
XML Tutorial.
This extension uses the Expat XML parser.
Expat is an event-based parser, it views an XML document as a series of
events. When an event occurs, it calls a specified function to handle it.
Expat is a non-validating parser, and ignores any DTDs linked to a document.
However, if the document is not well formed it will end with an error message.
Because it is an event-based, non validating parser, Expat is fast and well
suited for web applications.
The XML parser functions lets you create XML parsers and define handlers for XML
events.
Сравнение API-интерфейсов SAX и DOM
Для обработки кода XML и документов XML чаще всего применяются три основных типа API-интерфейсов: SimpleXML, объектная модель документа (Document Object Model — DOM) и простой API-интерфейс для XML (Simple API for XML — SAX). Все три этих модуля теперь включены во все дистрибутивы PHP.
Для синтаксического анализа и модификации любого документа XML можно использовать любой из трех API-интерфейсов — DOM, SAX или SimpleXML. А для создания или дополнения документа XML исключительно с помощью интерфейса PHP (иными словами, без написания каких-либо фрагментов документа XML вручную) необходимо использовать DOM. Каждый из API-интерфейсов имеет свои преимущества и недостатки, которые описаны ниже:
- SAX
-
API-интерфейс SAX является менее трудоемким и более простым в изучении, но документ XML рассматривается в нем, по существу, как поток строковых данных. Таким образом, если, например, необходимо выполнить синтаксический анализ текста рецепта, то язык PHP позволяет быстро написать синтаксический анализатор SAX и с помощью него, допустим, обозначить полужирным шрифтом элементы списка ингредиентов. Но решить задачу добавления полностью нового элемента или атрибута будет очень сложно, и даже модификация значения одного конкретного ингредиента окажется трудоемкой.
API-интерфейс SAX очень хорошо подходит для выполнения единообразных задач, в которых требуется применение одной и той же операции ко всем элементам определенного типа, например, для замены конкретного дескриптора элемента дескрипторами HTML в ходе преобразования документа XML в документ HTML, предназначенный для вывода на экран. Синтаксический анализатор SAX обрабатывает документ один раз, от начала до конца, поэтому не позволяет возвращаться и выполнять действия с учетом входных данных, находящихся в документе вслед за обрабатываемым элементом.
- DOM
-
Расширение DOM, предусмотренное в языке PHP, позволяет считывать файл XML и создавать в памяти дерево объектов, допускающее обход. Это дает возможность начать обработку с самого документа или с любого элемента документа (элементы в терминологии DOM именуются узлами), после чего получать или задавать значения дочерних и родительских узлов, а также текстовое информационное наполнение в каждой части дерева.
Объекты DOM можно сохранять в контейнерах, а также выводить их в виде текста. API-интерфейс DOM языка XML обеспечивает наилучшие результаты, если доступен весь документ XML. А если код XML поступает очень медленно в виде потока или требуется обработать много разных фрагментов XML как разделы одного и того же документа, то целесообразно использовать API-интерфейс SAX. Кроме того, в расширении DOM предусматривается формирование дерева в памяти, поэтому для обработки больших документов могут потребоваться значительные ресурсы.
- SimpleXML
-
API-интерфейс SimpleXML позволяет быстро открыть файл XML, преобразовать некоторые из обнаруженных в нем элементов в собственные типы PHP (переменные, объекты и т.д.), а затем применить к этим собственным типам необходимые операции, как и в обычной программе. API-интерфейс SimpleXML позволяет обойтись без сложностей, связанных с выполнением большого количества дополнительных вызовов, которые требуются в API-интерфейсах SAX и DOM, и ограничиться меньшим объемом памяти. Кроме того, SimpIeXML часто предоставляет самый простой способ быстрого получения доступа к данным XML.
Тем не менее SimpIeXML имеет некоторые ограничения, в частности, этот API-интерфейс иногда ведет себя непредсказуемо при обработке атрибутов и глубоко вложенных элементов.
![]()
1С+Классы. Версия-0
Разработано ООП-расширение языка 1С, включающее (но не ограничивающееся):
Классы как абстрактные типы данных с элементами «переменная», «свойство», «функция», «процедура»; Интерфейсы как абстрактные классы без элементов состояния («переменная») и без привязки к реализации методов (свойств, процедур, функций) при определении; Имплементация (реализация) интерфейсов классами;
— одиночное открытое наследование; Области видимости «внутренняя» (private), «экспорт» (public), «защищенная» (protected); Статические элементы классов (общие для всех экземпляров класса); Замещение (переопределение реализации) методов при наследовании – «виртуальные методы, свойства»; Сокрытие (затенение) обычных (не замещаемых) элементов при наследовании; Перегрузка процедур и функций по количеству и типам данных аргументов; Конструкторы класса; Деструктор класса; Слабые ссылки; Делегаты.
1 стартмани
Сильные и слабые стороны
Достоинства
- XML — это самодокументируемый формат, который описывает структуру и имена полей также как и значения полей;
- XML имеет строго определённый синтаксис и требования к анализу, что позволяет ему оставаться простым, эффективным и непротиворечивым. Одновременно с этим, разные разработчики не ограничены в выборе экспрессивных методов (например, можно моделировать данные, помещая значения в параметры тегов или в тело тегов, можно использовать различные языки и нотации для именования тегов и т. д.);
- XML — формат, основанный на международных стандартах;
- Иерархическая структура XML подходит для описания практически любых типов документов, кроме аудио и видео мультимедийных потоков, растровых изображений, сетевых структур данных и двоичных данных;
- XML представляет собой простой текст, свободный от лицензирования и каких-либо ограничений;
- XML не зависит от платформы;
- XML не накладывает требований на расположение символов в строке;
- В отличие от бинарных форматов, XML содержит метаданные об именах, типах и классах описываемых объектов, по которым приложение может обработать документ неизвестной структуры (например, для динамического построения интерфейсов);
- XML имеет реализации парсеров для всех современных языков программирования;
- XML поддерживается на низком аппаратном, микропрограммном и программном уровнях в современных аппаратных решениях.
Недостатки
Синтаксис XML избыточен.
-
- Размер XML документа существенно больше бинарного представления тех же данных. В грубых оценках величину этого фактора принимают за 1 порядок (в 10 раз).
- Избыточность XML может повлиять на эффективность приложения. Возрастает стоимость хранения, обработки и передачи данных.
- XML содержит мета-данные (об именах полей, классов, вложенности структур), и одновременно XML позиционируется как язык взаимодействия открытых систем. При передаче между системами большого количества объектов одного типа (одной структуры), передавать метаданные повторно нет смысла, хотя они содержатся в каждом экземпляре XML описания.
- Для большого количества задач не нужна вся мощь синтаксиса XML и можно использовать значительно более простые и производительные решения.
Неоднозначность моделирования.
-
- Нет общепринятой методологии для моделирования данных в XML, в то время как для реляционной модели и объектно-ориентированной такие средства разработаны и базируются на реляционной алгебре, системном подходе и системном анализе.
- В природе есть множество объектов и явлений, для описания которых разные структуры данных (сетевая, реляционная, иерархическая) являются естественными, и отображение объекта в неестественную для него модель является болезненным для его сути. В случае с реляционной и иерархической моделями определены процедуры декомпозиции, обеспечивающие относительную однозначность, чего нельзя сказать о сетевой модели.
- В результате большой гибкости языка и отсутствия строгих ограничений, одна и та же структура может быть представлена множеством способов (различными разработчиками), например, значение может быть записано как атрибут тега или как тело тега и т. д. Например: <a b=»1″ c=»1″/> или <a b=»1″ c=»1″></a> или <a><b>1</b><c>1</c></a> или <a><b value=»1″/><c value=»1″/></a> или <a><fields b=»1″ c=»1″/></a> и т. д.
- Поддержка многих языков в именовании тегов дает возможность назвать, например вес русским словом, в таком случае компьютер никак не сможет установить соответствия этого поля с полем weight в англоязычной версии программы и с полями в версиях модели объекта на множестве других языков.
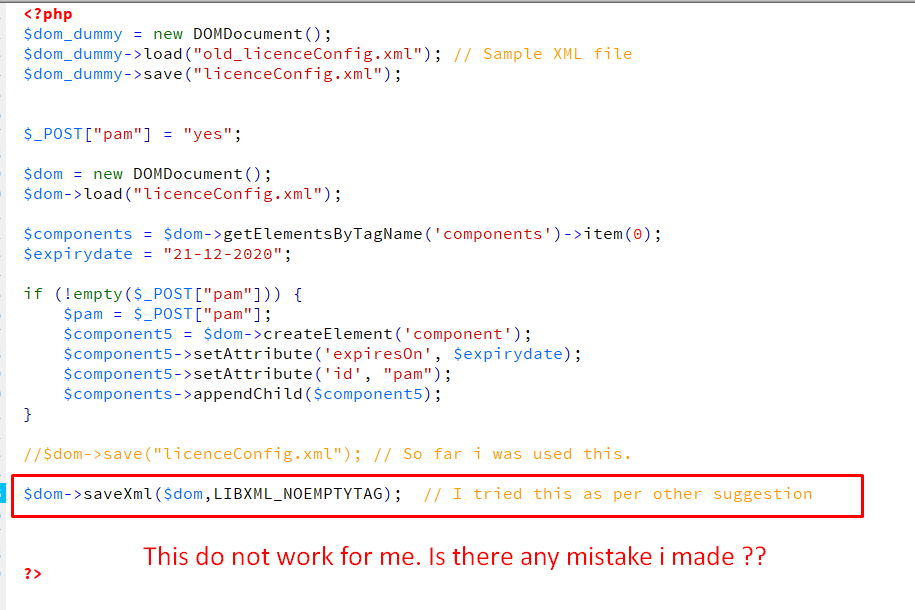
Как связать XML-документ со своей DTD-декларацией?
Возникает вопрос: как же теперь установить связь между самим XML-файлом и его DTD-описанием. Существует два способа связывания: внутренний и внешний.
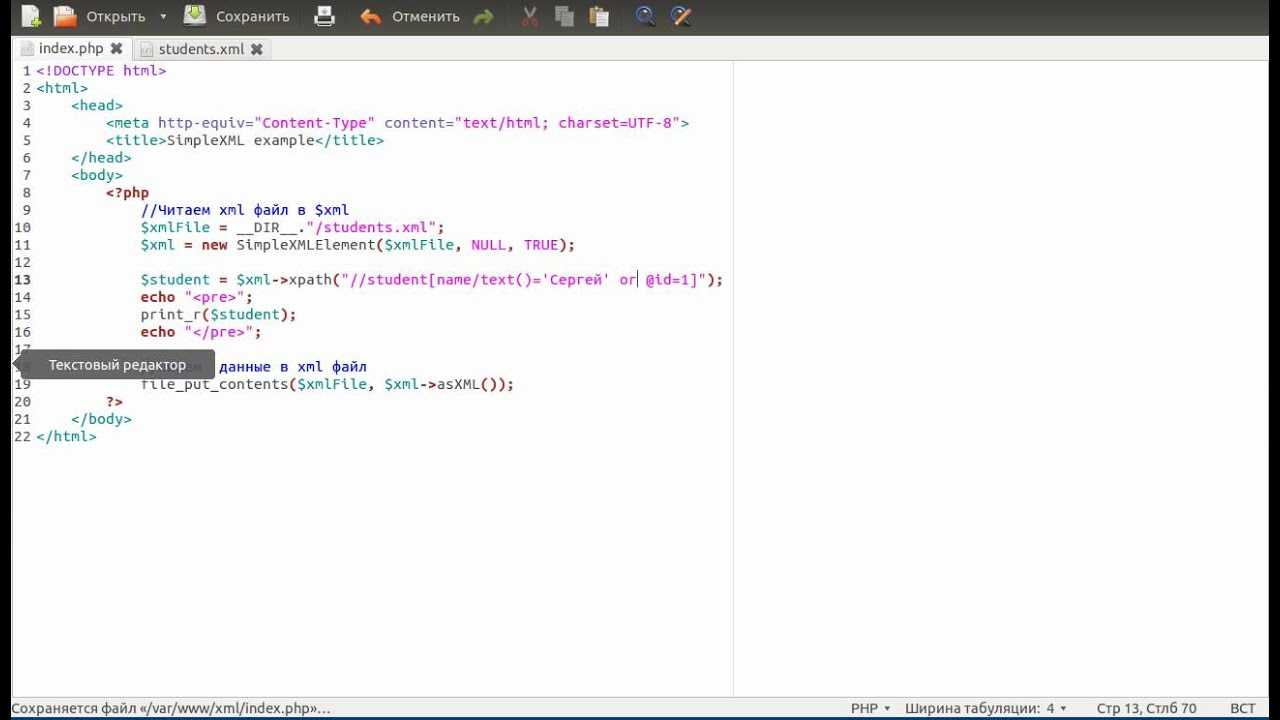


При внутреннем связывании создается специальный декларативный элемент DOCTYPE для корневого элемента POSITION нашего XML-документа, который включает в себя все остальные декларативные элементы. Этот текст внедряется затем в XML-файл сразу после строки-заголовка. Выглядит это так:
При внешнем связывании DTD-декларация XML-документа выкладывается в отдельный файл. Допустим, мы дали XML-файлу имя: chess.xml, а его описанию — имя chess.dtd. Для этого способа связывания также следует включить декларативный элемент DOCTYPE сразу после заголовочной строки. Однако теперь он не содержит в себе все остальные декларативные элементы, а лишь ссылается на тот внешний файл chess.dtd, который их содержит. Выглядит это так:
Такое связывание предполагает, что файл сhess.dtd всегда следует искать в том же самом каталоге, что и файл chess.xml. Это простой подход, однако его никак не назовешь удобным. Ведь DTD-описание мы создаем один раз, а создавать соответствующие ему XML-файлы будем многократно. Зачем же каждый раз пересылать их вместе? Удобнее всего поместить декларацию где-нибудь в общедоступном месте, на которое дать ссылку (URL — universal resource locator). Например, если мы выложим файл chess.dtd на сайте журнала «Лучшие компьютерные игры» (www.lki.ru) в каталоге chess, то строка, обеспечивающая внешнюю связь XML-файлов со своим DTD-описанием, будет выглядеть так:
Такой подход имеет массу преимуществ. Кто бы и где бы ни использовал теперь файлы созданного нами словаря для обмена шахматными позициями, он всегда получит доступ к его описанию. А получив это описание, сможет и проверить правильность синтаксиса при формировании XML-файлов, и организовать их правильный грамматический разбор.
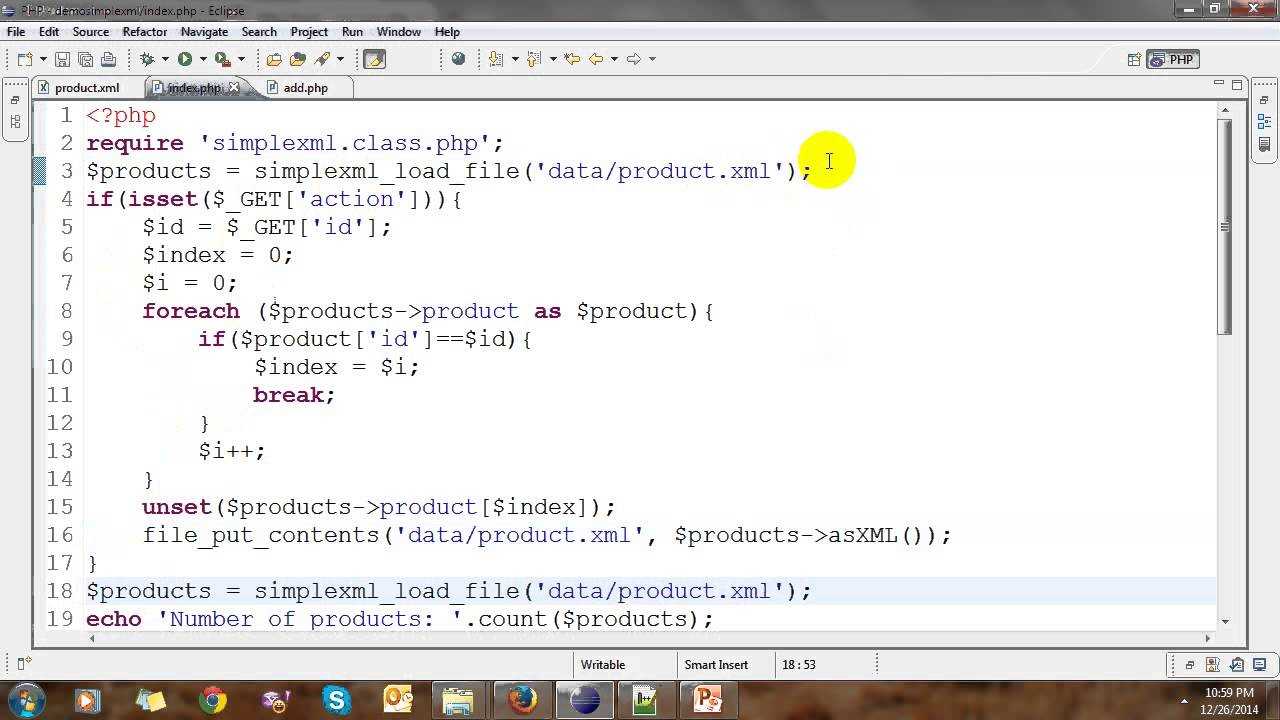
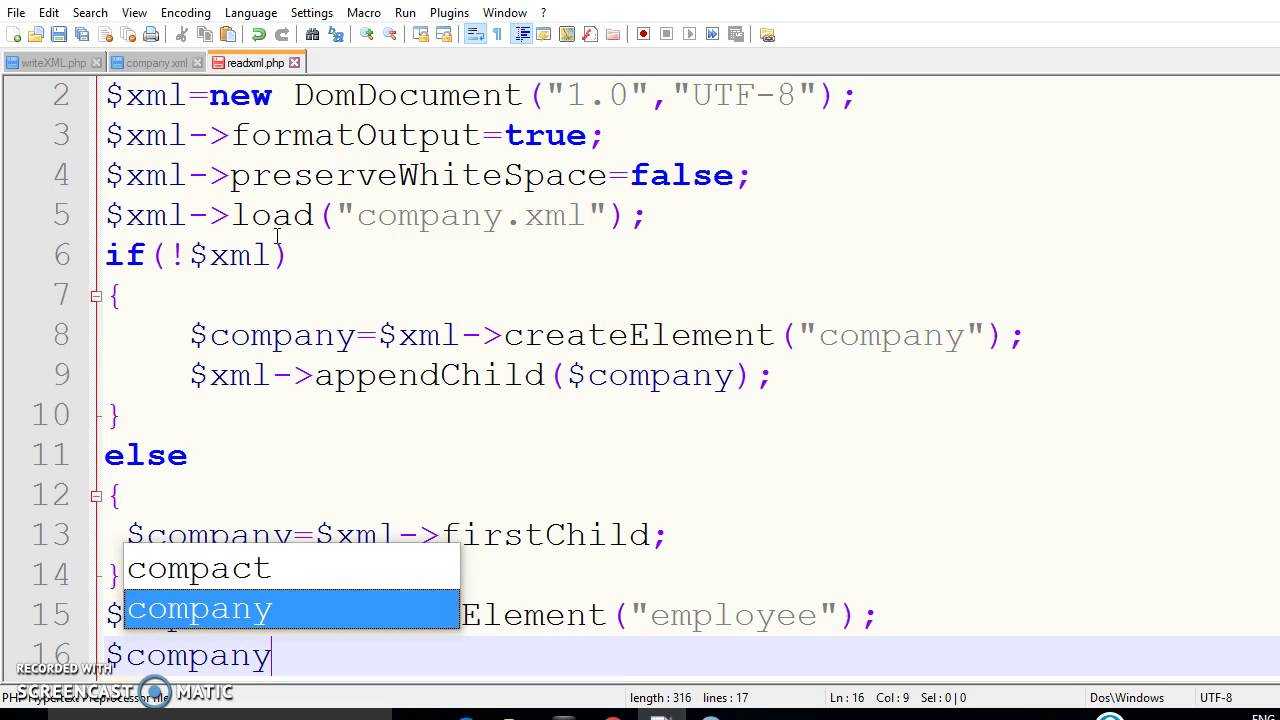
How to Convert XML to an Array With PHP
In this section, we’ll see how you can convert XML content into an array.
First of all, let’s quickly go through the steps that you need to follow to convert XML content into an array with the help of the SimpleXML extension.
- Read the file contents and parse them. At the end of this step, the content is parsed and converted into the object format. We’re going to use the function to achieve this.
- Next, you need to convert the object into a JSON representation by using the function.
- Finally, you need to use the function to decode the JSON content so that it eventually generates an array of all documents.
For demonstration purposes, let’s assume that we have an XML file as shown in the following snippet. We’ll call it employees.xml. It contains the basic details of all employees. Our aim is to convert it into an array that you could use for further processing.
Next, create the simplexml.php file with the following contents.
Let’s go through the important snippets in the above example to understand how it works.
Read and Parse the XML File
Firstly, we’ve used the function to disable standard libxml errors and enable user error handling. In this way, we can catch the XML errors during parsing and display them in a user-friendly way. This is also really useful in the development phase.
Next, we’ve used the function to read and parse the employees.xml file. The first argument of the function is a path to the XML file. It’s important to note that you need to adjust this path as needed. In the above example, it’s assumed that the employees.xml file is at the same directory level as that of the simplexml.php file. If the XML file is parsed successfully, it returns an object of the class; otherwise, it returns .
Next, if the variable is set to , there was a problem parsing the employees.xml file. In that case, we use the function to get all the errors and display them for debugging purposes. The variable is set to if the employees.xml file is parsed successfully.
Convert the Object Into Its JSON Representation
Next, we’ve used the function to convert the object into its JSON representation. We’ve stored the JSON string in the variable, as shown in the following snippet.
Decode the JSON String Into an Array
Finally, we’ve used the function to decode the JSON string data. It’s important to note that we’ve passed in the second argument of the function, which converts all objects into associative arrays.
Had you not passed in the second argument, the function would have produced objects of type instead of arrays.
So that’s an outline of the whole process. Let’s run the simplexml.php file, and you should see the following output.
As expected, the array contains all the documents. As you may have noticed, it has also parsed the field, which is attached with each document in the form of an attribute, and you can access it with the key, as shown in the above output. Basically, everything is available in the form of key-value pairs. So you have a complete array at your disposal for further processing.
So that’s how you can convert XML content into an array in PHP. It was a very simple example, but it should give you some insight into the whole process.
DTD, или декларация
Как же оформить правила нашего языка? Существуют различные способы. Один из них — это определение типа документа, или DTD (аббревиатура от английского «document type definition»). На русском языке это описание часто называют декларацией. Для простоты изложения я создам сначала DTD-описание для каждого из наших словарей, а затем объясню, что означают строки этой записи.
Для первой версии словаря файл DTD будет выглядеть так:
Декларация в виде диаграммы (1-я версия).
Строка <!ELEMENT POSITION (AUTHOR?, SOURCE?, NOTE*, FIGURE*)> означает, что элемент POSITION является составным и включает в себя элементы AUTHOR, SOURCE, NOTE и FIGURE. Символ-суффикс (*) после элементов FIGURE и NOTE означает, что эти элементы могут встречаться в рамках элемента POSITION сколько угодно раз, в том числе и ни разу не встречаться. Полное отсутствие элементов FIGURE соответствует пустой шахматной позиции. Знак (+) после элемента (у нас он не был использован) позволяет элементу появляться один или более раз. Если бы мы захотели запретить изображать пустые позиции в нашем XML-формате, нам следовало бы поставить FIGURE+ вместо FIGURE*. Знак (?) после элементов AUTHOR и SOURCE разрешает использование этих элементов 0 или 1 раз. И, наконец, отсутствие знака означает использование элемента ровно один раз. Такую ситуацию мы описали в строке <!ELEMENT FIGURE (NAME, COLOR, PLACE)>
Она оговаривает, что каждый элемент FIGURE должен обязательно содержать элементы NAME, COLOR и PLACE, причем каждый из них ровно один раз.
Если кто-нибудь из читающих данную статью использовал когда-нибудь регулярные выражения (особенно часто они используются при написании серверных веб-скриптов на языках Perl или PHP), он воспримет такое использование символов-суффиксов как нечто знакомое и естественное. В регулярных выражениях эти знаки используются в том же смысле, хотя и в ином контексте.
Строка <!ELEMENT NAME (#PCDATA)> означает, что элемент NAME содержит в себе некое грамматически разбираемое (в соответствии с теговой структурой) символьное значение. Английская аббревиатура PCDATA (сокращение от «parsed character data») именно это в переводе и означает.
Так что если вы собираетесь помещать в это поле простое символьное значение, позаботьтесь о том, чтобы оно не содержало зарезервированных символов «<», «>» и «&». Эти знаки должны быть заменены на «<», «>», «&» соответственно. Если в тексте встречаются двойные или одинарные кавычки, то их также во избежание неправильного толкования следует заменить на «"» и «'» соответственно.
Для второго варианта XML-словаря, в котором центр тяжести информации перенесен с элементов на атрибуты, DTD-описание будет выглядеть следующим образом:
Декларация в виде диаграммы (2-я версия).
Чем отличается это описание от предыдущего? Во-первых, обратите внимание на указание EMPTY (пустой) для элемента FIGURE, так как этот элемент во втором варианте словаря не имеет ни значения, ни внутренней структуры. Блок
> описывает атрибуты этого элемента. Тип CDATA означает простой символьный тип в отличие от грамматически разбираемого символьного типа PCDATA. Практически это означает, что здесь снимается запрет на употребление угловых скобок и знака апострофа. Путаницы не возникает, так как атрибут окаймляется кавычками. Суффикс #REQUIRED (в переводе с английского — «затребован») оговаривает обязательность указанного атрибута в данном элементе. Для атрибута color значение ограничено двумя вариантами («Черный» и «Белый»). Такие перечисляемые варианты значений должны разделяться вертикальной чертой (символ «|»). Атрибут name имеет аналогичное перечисляемое описание. Это позволяет исключить использование недопустимых наименований шахматных фигур.


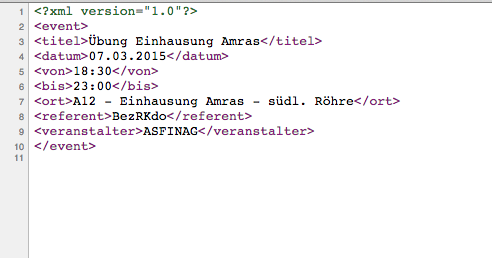

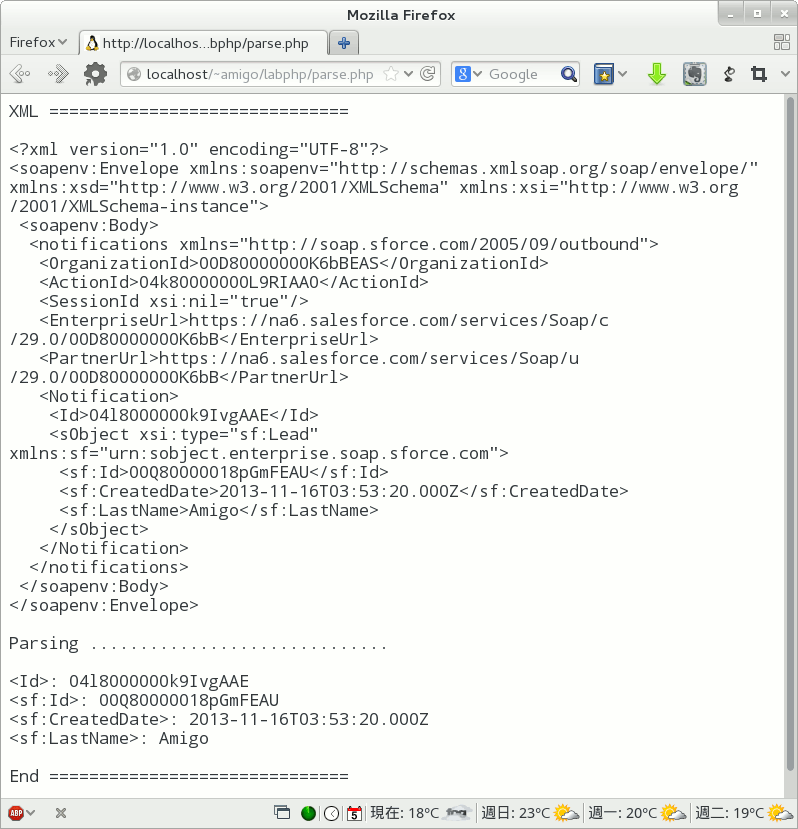
What Does Parsing Mean?
I throw around the word “Parsing” and “parse”, but what does “parsing” something actually entail and what does it mean to “parse” a document?
As the quote I copied from a quick Google search says, Parsing an XML document, pretty much means that we are going to break it down into smaller components that we can work with more easily.
Confused yet? read on…
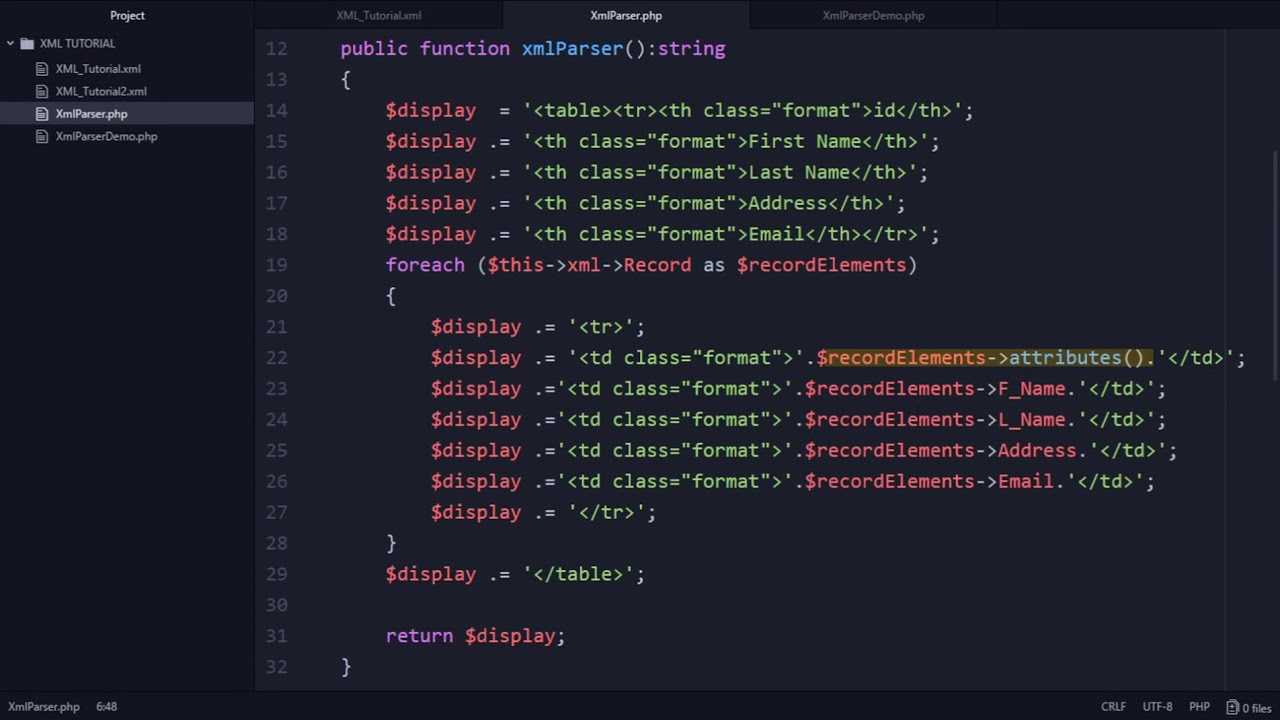
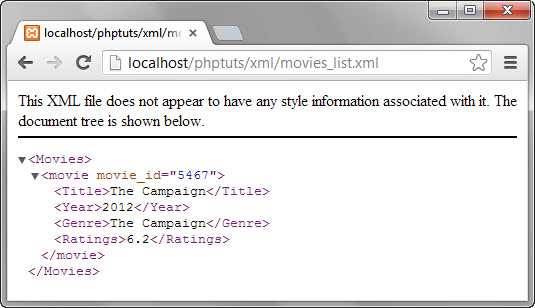
In our XML document there are several tags named <item>, within this node there are various child nodes:
<title> ,
<link> ,
<pubDate> etc.(I call everything within
<tags>IAMANODE<tags> for a node, this is probably not the correct technical term, but it makes more sense to me).
The
<channel> node represents the entire blog, the blog has several blog posts(
<item> ) and each blog post have a title, summary(
<description> ), publication date(
<pubDate> ) and various other information.
These
<item> nodes represents my blog posts, as you can see in the picture below.
- The XML represents my blog posts. (Click for larger image)



