Вопрос 11. Как работает функция range?
Сложность: (ー_ー)
Функция range() генерирует три разных вида последовательностей из целых чисел и часто используется для быстрого создания списков — поэтому этот вопрос и попал в нашу подборку. Да и объяснять работу функции удобнее всего именно с помощью списка.
Последовательность от нуля до n
Используется range(n):
Функция range(n) сгенерировала последовательность от нуля до n (исключая n), а мы эту последовательность двумя способами обернули в список. Первый способ вы уже узнали — это генератор списков, а второй использует функцию list, которая превращает подходящий аргумент в список.
Попробуйте передать в range() отрицательное (-7) или дробное (3.14) число. Получится ли какой-нибудь список из этого, и если да, то какой?
Последовательность от n до m
Здесь в функцию range() нужно передать уже два аргумента: тогда range(n, m) сгенерирует целые числа от n до m (исключая m):
Последовательность от n до m с шагом k
Если в функцию range() передать три аргумента n, m, k, то она снова создаст последовательность от n до m (снова исключая m), но уже с шагом k:
Типо “List Comprehensions”… в генераторном режиме
Есть ещё одни способ создания списков, который похож на списковое включение, но результатом работы является не объект класса list, а генератор. Подробно про генераторы написано в “Уроке 15. Итераторы и генераторы“.
Предварительно импортируем модуль sys, он нам понадобится:
>>> import sys
Создадим список, используя списковое включение :
>>> a =
проверим тип переменной a:
>>> type(a) <class 'list'>
и посмотрим сколько она занимает памяти в байтах:
>>> sys.getsizeof(a) 192
Для создания объекта-генератора, используется синтаксис такой же как и для спискового включения, только вместо квадратных скобок используются круглые:
>>> b = (i for i in range(10)) >>> type(b) <class 'generator'> >>> sys.getsizeof(b) 120
Обратите внимание, что тип этого объекта ‘generator’, и в памяти он занимает места меньше, чем список, это объясняется тем, что в первом случае в памяти хранится весь набор чисел от 0 до 9, а во втором функция, которая будет нам генерировать числа от 0 до 9. Для наших примеров разница в размере не существенна, рассмотрим вариант с 10000 элементами:
>>> c = >>> sys.getsizeof(c) 87624 >>> d = (i for i in range(10000)) >>> sys.getsizeof(d) 120
Сейчас уже разница существенна, как вы уже поняли, размер генератора в данном случае не будет зависеть от количества чисел, которые он должен создать.
Если вы решаете задачу обхода списка, то принципиальной разницы между списком и генератором не будет:
>>> for val in a:
print(val, end=' ')
0 1 2 3 4 5 6 7 8 9
>>> for val in b:
print(val, end=' ')
0 1 2 3 4 5 6 7 8 9
Но с генератором нельзя работать также как и со списком: нельзя обратиться к элементу по индексу и т.п.
Практическая работа по использованию словарей
Дан текст на некотором языке. Требуется подсчитать сколько раз каждое слово входит в этот текст и вывести десять
самых часто употребяемых слов в этом тексте и количество их употреблений.
В качестве примера возьмите файл с текстом лицензионного соглашения Python .
Подсказка №1: Используйте словарь, в котором ключ — слово, а знчение — количество таких слов.
Подсказка №2: Точки, запятые, вопросы и восклицательные знаки перед обработкой замените пробелами(используйте из модуля string).
Подсказка №3: Все слова приводите к нижнему регистру при помощи метода строки .
Подсказка №4: По окончании сбора статистики нужно пробежать по всем ключам из словаря и найти ключ с максимальным значением.
Дан словарь task4/en-ru.txt с однозначным соответствием английских и русских слов в таком формате:
Здесь английское и русское слово разделены двумя табуляциями и минусом: .
В файле task4/input.txt дан текст для перевода, например:
Mouse in house. Cat in house.
Cat eats mouse in dog house.
Dog eats mouse too.
Требуется сделать подстрочный перевод с помощью имеющегося словаря и вывести результат в .
Незнакомые словарю слова нужно оставлять в исходном виде.
Дан список стран и языков на которых говорят в этой стране в формате в файле task5/input.txt. На ввод задается N — длина списка и список языков. Для каждого языка укажите, в каких странах на нем говорят.
| Ввод | Вывод |
|---|---|
| 3 | |
| азербайджанский | Азербайджан |
| греческий | Кипр Греция |
| китайский | Китай Сингапур |
В файле task6/en-ru.txt находятся строки англо-русского словаря в таком формате:
cat — кошка
dog — собака
home — домашняя папка, дом
mouse — мышь, манипулятор мышь
to do — делать, изготавливать
to make — изготавливать
Здесь английское слово (выражение) и список русских слов (выражений) разделены двумя табуляциями и минусом: .
Требуется создать русско-английский словарь и вывести его в файл в таком формате:
делать — to do
дом — home
домашняя папка — home
изготавливать — to do, to make
кошка — cat
манипулятор мышь — mouse
мышь — mouse
собака — dog
Порядок строк в выходном файле должен быть словарным с человеческой точки зрения (так называемый лексикографический порядок слов). То есть выходные строки нужно отсортировать.
Даны два файла словарей: task7/en-ru.txt и task7/ru-en.txt (в формате, описанном в упражнении №6).








en-ru.txt:
home — домашняя папка
mouse — манипулятор мышь
ru-en.txt:
дом — home
мышь — mouse
Требуется синхронизировать и актуализировать их содержимое.
en-ru.txt:
home — домашняя папка, дом
mouse — манипулятор мышь, мышь
ru-en.txt:
дом — home
домашняя папка — home
манипулятор мышь — mouse
мышь — mouse
В одном очень дружном доме, где живет Фёдор, многие жильцы оставляют ключи от квартиры соседям по дому, например на случай пожара или потопа, да и просто чтобы покормили животных или полили цветы.
Вернувшись домой после долгих странствий, Фёдор обнаруживает, что потерял свои ключи и соседей дома нет. Но вдруг у домофона он находит чужие ключи. Помогите Федору найти ключи от своей квартиры в квартирах соседей.
На ввод подается файл input.txt, в котором в первой строке записано три числа через пробел N — номер квартиры Фёдора, M — номер квартиры от которой Федор нашел ключи, K — ключ от этой квартиры. Далее i-я строка хранит описание ключей запертых в i-й квартире в формате , причем реальные номера квартир «зашифрованы» ключем от i-й квартиры(Ki) и находятся по формуле m_ij’ = m_ij — Ki. Номера квартир начинаются с 0 (кпримеру вторая строка файла соответствует 0-й квартире).
Нужно вывести ключ от квартиры Федора или None если его найти не получилось.
| Ввод | Вывод |
|---|---|
| 4 0 1 | 1 |
| 1 1,2 0,3 1,4 0 | |
| 3 0 | |
| 5 1,6 0 | |
| 1 1 | |
| 2 1 |
Подсказка: используйте словарь для хранения ключей от еще не открытых комнат и множество для уже проверенных комнат.
Дан текст-образец, по которому требуется сделать генератор случайного бреда на основе Марковских цепей.
Подробности спрашивайте у семинариста.
Как удвоить все значения в списке
Также должно быть лучшее решение, которое выглядит как , но оно также не работает.
Любые другие советы по поводу циклов и списков будут высоко оценены.
Потому что n или lst , поскольку он вызывается внутри double , никогда не изменяется. x *= 2 эквивалентен x = x * 2 для чисел x и что он только повторно связывает имя x без изменения ссылки на объект.
Чтобы увидеть это, измените double следующим образом:
Чтобы изменить список номеров на месте, вы должны переназначить его элементы:
Если вы не хотите изменять его на месте, используйте понимание:
Для этого вы можете использовать список:
ФУНКЦИЯ:
DEMO:
ВЫВОД:
В питоне, который умножает сам список, вы получите следующее:
Поэтому вам нужно размножать элементы списка, поэтому вы используете for-loop в первую очередь, чтобы перебирать список.
Объединение нескольких списков с использованием метода itertools.chain()
Давайте создадим простую программу на Python для объединения нескольких списков с помощью метода chain(), импортировав пакет itertools.
New.py
# use Python itertools.chain() method to join two list
import itertools
# declare different lists
a =
b =
c =
print(" Display the first list ", a)
print(" Display the second list ", b)
print(" Display the third list ", c)
# use itertools.chain() method to join the list
result = list(itertools.chain(a, b, c))
# pass the result variable in str() function to return the concatenated lists
print(" Concatenated list in python using itertools.chain() method ", str(result))
Выход:
Display the first list Display the second list Display the third list Concatenated list in python using itertools.chain() method
Предварительная обработка
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler from sklearn.feature_selection import SelectKBest,chi2,RFE from sklearn.ensemble import RandomForestClassifier df = pd.read_csv("data/Heart_Disease_Prediction-ru.csv") #df = pd.read_csv("data/Heart_Disease_Prediction.csv") print('Размер Dataframe:', df.shape) print(df.head(5))
Приведенный выше код импортирует необходимые библиотеки и считывает CSV‑файл набора данных из папки данных. Если вы скачали этот набор на свой компьютер, то Вам также необходимо создать отдельную папку данных. Путь к местоположению файла набора данных на своём компьютере можно изменить, соответствующим образом изменив код. Хочу отметить, что здесь для примеров используется не оригинальный файл Heart_Disease_Prediction.csv, а файл Heart_Disease_Prediction-ru.csv, где все категориальные значения переведены на русский язык.
После чего внимательно посмотрим на полученный , вот результат:
Размер Dataframe: (270, 14) Возраст Пол ... Таллий Сердечное заболевание 0 70 1 ... 3 Есть 1 67 0 ... 7 Нет 2 57 1 ... 7 Есть 3 64 1 ... 7 Нет 4 74 0 ... 3 Нет
Получим обобщённую информацию о , используя метод :
print('\n\nИнформация о Dataframe df.info():')
print(df.info())
Здесь ясно видно, что пропуски значений отсутствуют. По всем признакам, во всех строках, все значения не‑нулевые и можно начать работу с нашим , не беспокоясь об очистке пропусков.
Информация о Dataframe df.info(): RangeIndex: 270 entries, 0 to 269 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Возраст 270 non-null int64 1 Пол 270 non-null int64 2 Тип боли в груди 270 non-null int64 3 BP 270 non-null int64 4 Холестерин 270 non-null int64 5 FBS свыше 120 270 non-null int64 6 Результаты EKG 270 non-null int64 7 Max HR 270 non-null int64 8 Стенокардия 270 non-null int64 9 ST депрессия 270 non-null float64 10 Наклон ST 270 non-null int64 11 Количество сосудов флюро 270 non-null int64 12 Таллий 270 non-null int64 13 Сердечное заболевание 270 non-null object dtypes: float64(1), int64(12), object(1)
Сохраним столбец метки в отдельной переменной и полностью удалим его (поэтому и используем ) из . Этот шаг важен для разделения нашего набора данных на обучающий и проверочный в дополнение к тому, что необходима адаптация их к нашей модели.
label = df
df.drop("Сердечное заболевание", axis=1, inplace=True)
print('\n\nЗначение метки "Сердечное заболевание":')
print(label.value_counts())
Вот что получилось:
Значение метки "Сердечное заболевание": Нет 150 Есть 120 Name: Сердечное заболевание, dtype: int64
Важно всегда проверять, насколько сбалансирован наш набор. Большой дисбаланс между классами меньшинства и большинства отрицательно повлияет на модель в том смысле, что она будет наивно предсказывать только класс большинства
Однако, в нашем случае коэффициент дисбаланса, , составляет всего , что вполне себе удовлетворительно.
# создаем диаграмму, где ось x - это признак, а Y указывает значение метки label.value_counts().plot(kind="bar")
В нашем наборе данных есть признаки, имеющие категориальный характер. Однако, при печати этих столбцов мы наблюдаем, что они определяются, как данные целого типа и рассматриваются как целые числа, что может сбить с толку нашу модель, которая при обучении примет их за некий континиум значений, несмотря на то, что они дискретны по сути своей.










Типы данных признаков: Возраст int64 Пол int64 Тип боли в груди int64 BP int64 Холестерин int64 FBS свыше 120 int64 Результаты EKG int64 Max HR int64 Стенокардия int64 ST депрессия float64 Наклон ST int64 Количество сосудов флюро int64 Таллий int64 Сердечное заболевание object dtype: object
По этой причине явно изменим их тип на категориальный, используя метод pandas.
categorical_features =
df = df.astype("category")
Типы данных признаков: Возраст int64 Пол category Тип боли в груди category BP int64 Холестерин int64 FBS свыше 120 category Результаты EKG category Max HR int64 Стенокардия category ST депрессия float64 Наклон ST category Количество сосудов флюро category Таллий category dtype: object
Теперь будем масштабировать наши непрерывные функции с помощью . Это тип нормализации, когда значения загоняются в диапазоне от 0 до 1, согласно уравнению
X_{Norm} = \dfrac{(X — X_{Min})}{(X_{Max} — X_{Min})}.
continuous_features = set(df.columns) - set(categorical_features) scaler = MinMaxScaler() df_norm = df.copy() df_norm = scaler.fit_transform(df)
Как списки хранятся в памяти?
Как уже было сказано выше, список является изменяемым типом данных. При его создании в памяти резервируется область, которую можно условно назвать некоторым “контейнером”, в котором хранятся ссылки на другие элементы данных в памяти. В отличии от таких типов данных как число или строка, содержимое “контейнера” списка можно менять. Для того, чтобы лучше визуально представлять себе этот процесс взгляните на картинку ниже. Изначально был создан список содержащий ссылки на объекты 1 и 2, после операции a = 3, вторая ссылка в списке стала указывать на объект 3.
![]()
Более подробно эти вопросы обсуждались в уроке 3 (Типы и модель данных).
5 способов форматирования строк
1. Конкатенация. Грубый способ форматирования, в котором мы просто склеиваем несколько строк с помощью операции сложения:
2. %-форматирование. Самый популярный способ, который перешел в Python из языка С. Передавать значения в строку можно через списки и кортежи , а также и с помощью словаря. Во втором случае значения помещаются не по позиции, а в соответствии с именами.
3. Template-строки. Этот способ появился в Python 2.4, как замена %-форматированию (), но популярным так и не стал. Поддерживает передачу значений по имени и использует $-синтаксис как в PHP.
4. Форматирование с помощью метода format(). Этот способ появился в Python 3 в качестве замены %-форматированию. Он также поддерживает передачу значений по позиции и по имени.
5. f-строки. Форматирование, которое появилось в Python 3.6 (). Этот способ похож на форматирование с помощью метода format(), но гибче, читабельней и быстрей.
Множество (set)
Множество в языке Python — это структура данных, эквивалентная множествам в математике.
Элементы могут быть различных типов. Порядок элементов не определён.
Действия, которые можно выполнять с множеством:
- добавлять и удалять элементы,
- проверять принадлежность элемента множеству,
- перебирать его элементы,
- выполнять операции над множествами (объединение, пересечение, разность).
Операция “проверить принадлежность элемента” выполняется в множестве намного быстрее, чем в списке.
Элементами множества может быть любой неизменяемый тип данных: числа, строки, кортежи.
Изменяемые типы данных не могут быть элементами множества, в частности, нельзя сделать элементом множества список (вместо этого используйте неизменяемый кортеж) или другое множество. Требование неизменяемости элементов множества накладывается особенностями представления множества в памяти компьютера.
Множество задается перечислением в фигурных скобках. Например:
A = {1, 2, 3}
Исключением явлеется пустое множество:
A = set() # A -- множество
D = {} # D -- не пустое множество, а пустой словарь!
Если функции set передать в качестве параметра список, строку или кортеж, то она вернет множество, составленное из элементов списка, строки, кортежа. Например:
>>> A = set('qwerty')
>>> print(A)
{'e', 'q', 'r', 't', 'w', 'y'}.
Каждый элемент может входить в множество только один раз.
>>> A = {1, 2, 3}
>>> B = {3, 2, 3, 1}
>>> print(A == B) # A и B — равные множества.
True
>>> set('Hello')
{'H', 'e', 'l', 'o'}
| Операция | Значение | Трудоемкость |
|---|---|---|
| принадлежит ли элемент множеству (возвращают значение типа ) | O(1) | |
| то же, что | O(1) | |
| добавить элемент в множество | O(1) | |
| удалить элемент из множества | O(1) | |
| удалить элемент из множества | O(1) | |
| удаляет из множества один случайный элемент и возвращает его | O(1) |
Как мы видим, по времени стандартные оперцаии с одним элементом множества выполняются за O(1).
Поведение и различается тогда, когда удаляемый элемент отсутствует в множестве:
не делает ничего, а метод remove генерирует исключение .
Метод также генерирует исключение , если множество пусто.
При помощи цикла for можно перебрать все элементы множества:
Primes = {2, 3, 5, 7, 11}
for num im Primes
print(num)
Из множества можно сделать список при помощи функции :
>>> A = {1, 2, 3, 4, 5}
>>> B = list(A)
1, 2, 3, 4, 5
Вывести на экран все элементы множества A, которых нет в множестве B.
A = set('bqlpzlkwehrlulsdhfliuywemrlkjhsdlfjhlzxcovt')
B = set('zmxcvnboaiyerjhbziuxdytvasenbriutsdvinjhgik')
for x in A
...
Списки Python
Список — это наиболее универсальный тип данных, доступный в Python, который можно записать в виде списка значений (элементов), разделенных запятыми, в квадратных скобках. Важным моментом в списке является то, что элементы в списке не обязательно должны быть одного типа.
Создать список просто — необходимо поставить различные значения через запятую в квадратных скобках. Например:
list1 = ; list2 = ; list3 =
Подобно строковым индексам, индексы списков начинаются с 0. Списки могут быть нарезаны, объединены и т.д.
Доступ к значениям в списках
Чтобы получить доступ к значениям в списках, используйте квадратные скобки для нарезки вместе с индексом или индексами, чтобы получить значение, доступное по этому индексу. Например —
list1 = ;
list2 = ;
print("list1: ", list1)
print("list2: ", list2)
Когда приведенный выше код выполняется, он дает следующий результат —
list1: physics list2:
Обновление списков
Вы можете обновить один или несколько элементов списков, предоставив срез в левой части оператора присваивания, а также добавить элементы в список с помощью метода append (). Например —
list = ; print "Value available at index 2 : " print list list = 2001; print "New value available at index 2 : " print list
Примечание. Метод append () обсуждается в следующем разделе.
Когда приведенный выше код выполняется, он дает следующий результат —
Value available at index 2 : 1997 New value available at index 2 : 2001
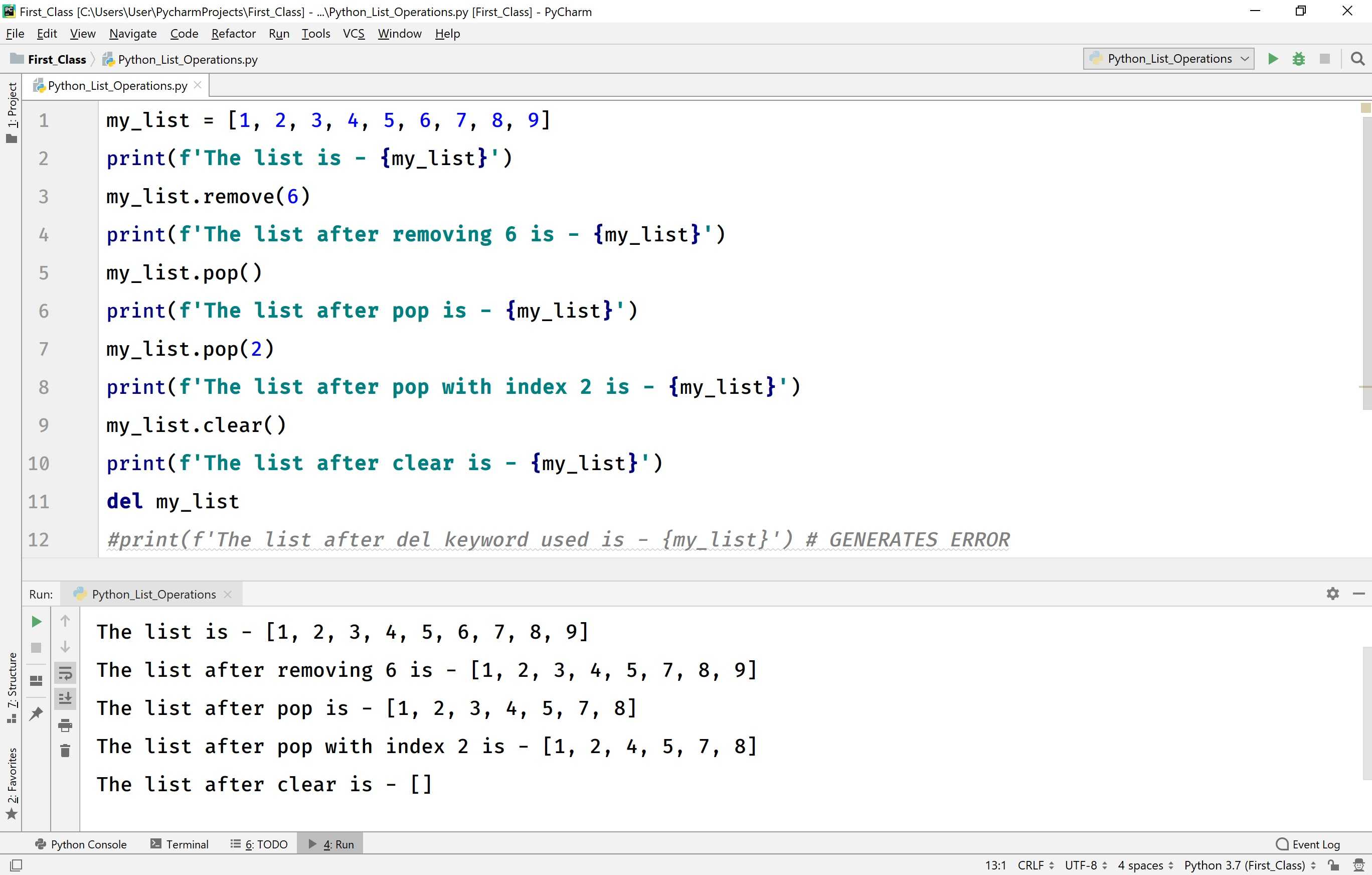
Удалить элементы списка
Чтобы удалить элемент списка, вы можете использовать либо оператор del, если вы точно знаете, какие элементы вы удаляете, либо метод remove (), если вы не знаете. Например —
list1 = ; print list1 del list1; print "After deleting value at index 2 : " print list1
Когда приведенный выше код выполняется, он дает следующий результат —
After deleting value at index 2 :
Примечание. Метод remove () обсуждается в следующем разделе.
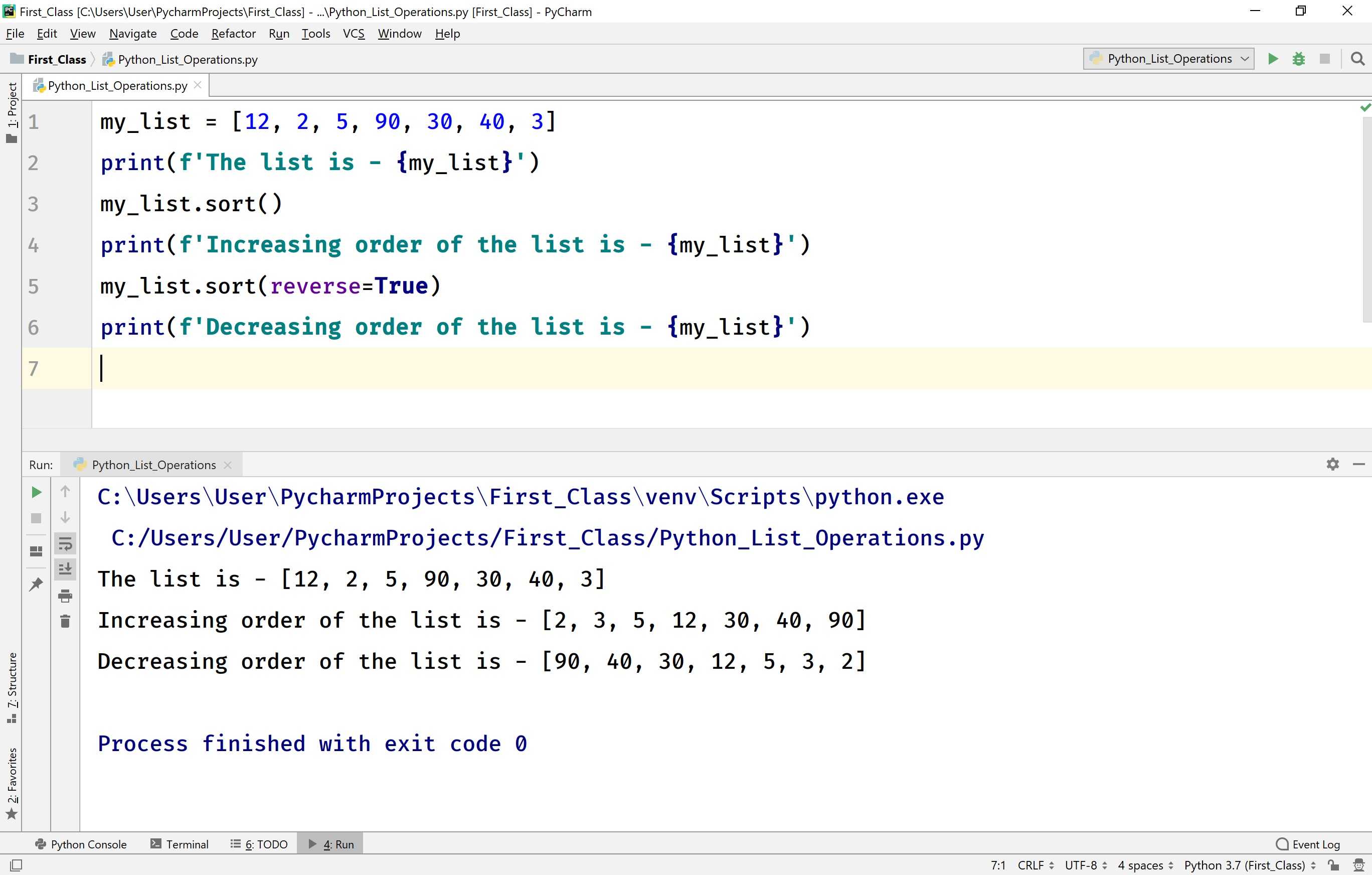
Основные операции со списком
Списки реагируют на операторы + и * так же, как строки; здесь они также означают конкатенацию и повторение, за исключением того, что результатом является новый список, а не строка.
Фактически списки отвечают на все общие операции последовательности, которые мы использовали со строками в предыдущей главе.
| Python Expression | Результаты | Описание |
|---|---|---|
| len() | 3 | Length — длина |
| + | Concatenation — конкатенация | |
| * 4 | Repetition — Повторение | |
| 3 in | True | Membership — членство |
| for x in : print x, | 1 2 3 | Iteration — итерация |
Индексирование, нарезка и матрицы
Поскольку списки являются последовательностями, индексирование и нарезка для списков работают так же, как и для строк.
Предполагая следующий ввод —
L =
| Выражение Python | Результаты | Описание |
|---|---|---|
| L | SPAM! | Смещения начинаются с нуля |
| L | Spam | Отрицательный: считать справа |
| L | Нарезка выборок разделов |
Встроенные функции и методы списка
Python включает в себя следующие функции списка —
| № | Функция с описанием |
|---|---|
| 1 |
cmp(list1, list2) Сравнивает элементы обоих списков. |
| 2 |
len(list) Дает общую длину списка. |
| 3 |
max(list) Возвращает элемент из списка с максимальным значением. |
| 4 |
min(list) Возвращает элемент из списка с минимальным значением. |
| 5 |
list(seq) Преобразует кортеж в список. |
Python включает следующие методы списка
| № | Методы с описанием |
|---|---|
| 1 |
list.append(obj) Добавляет объект obj в список |
| 2 |
list.count(obj) Возвращает количество раз, сколько obj встречается в списке |
| 3 |
list.extend(seq) Добавляет содержимое seq в список |
| 4 |
list.index(obj) Возвращает самый низкий индекс в списке, который появляется obj |
| 5 |
list.insert(index, obj) Вставляет объект obj в список по индексу смещения |
| 6 |
list.pop(obj=list) Удаляет и возвращает последний объект или объект из списка |
| 7 |
list.remove(obj) Удаляет объект obj из списка |
| 8 |
list.reverse() Переворачивает объекты списка на месте |
| 9 |
list.sort() Сортирует объекты списка, используйте функцию сравнения, если дано |