Виды кодировок текста
А их, в общем-то, хватает.
ASCII
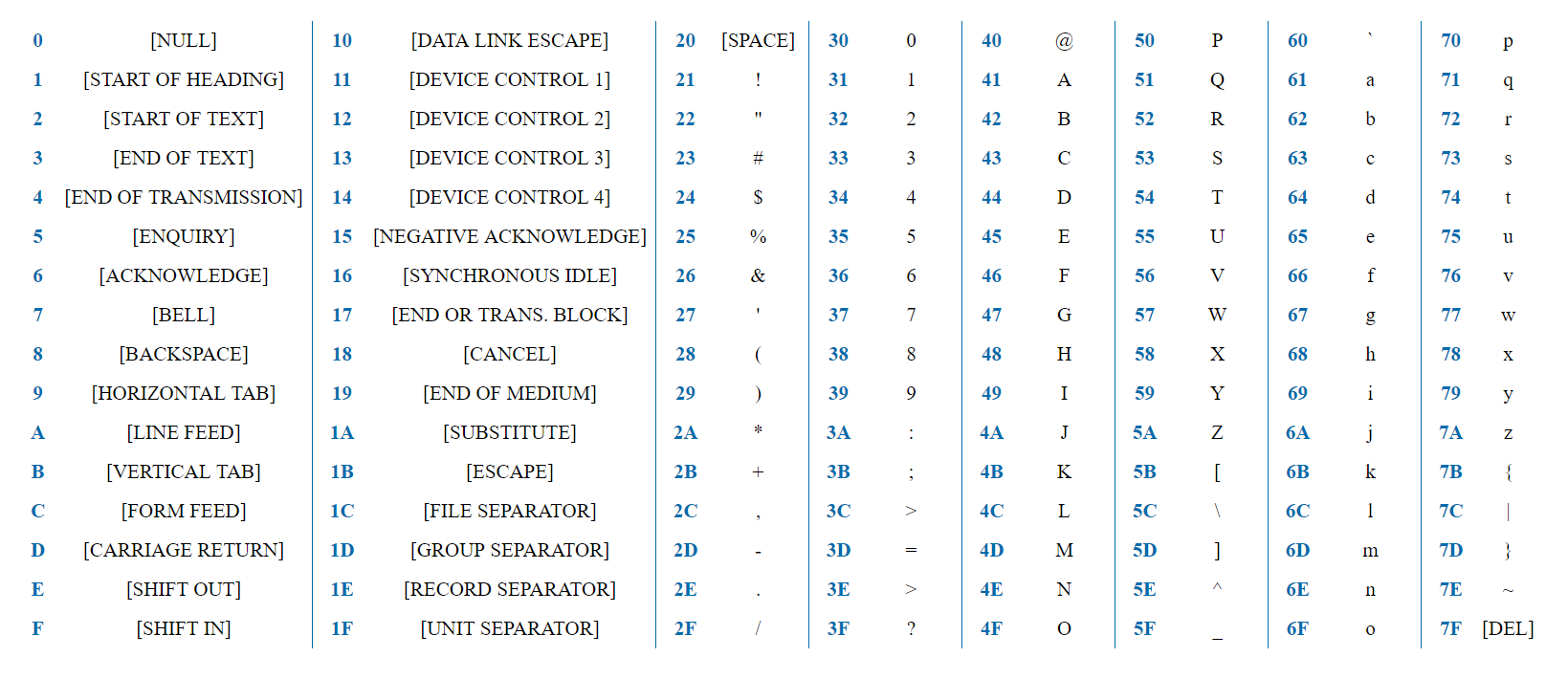
Одной из самых “древних” считается американская кодировочная таблица (ASCII, читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
Кириллица
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256. Заточена под русскоязычную аудиторию.
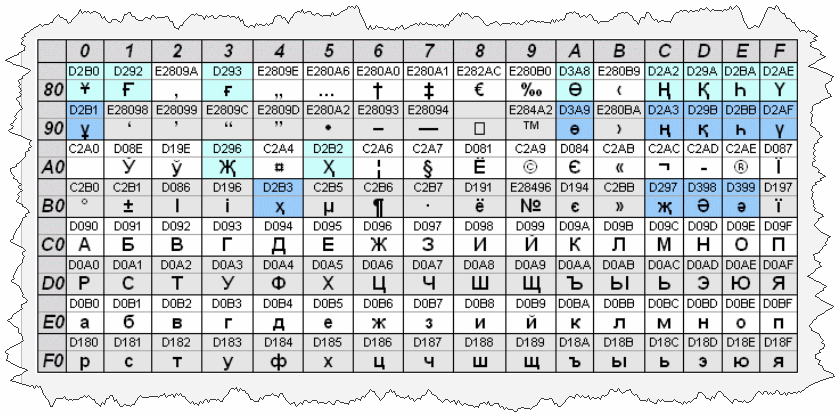
Кодировки семейства MS Windows: Windows 1250-1258.
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows. Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
Код обмена информацией 8 бит – КОИ8
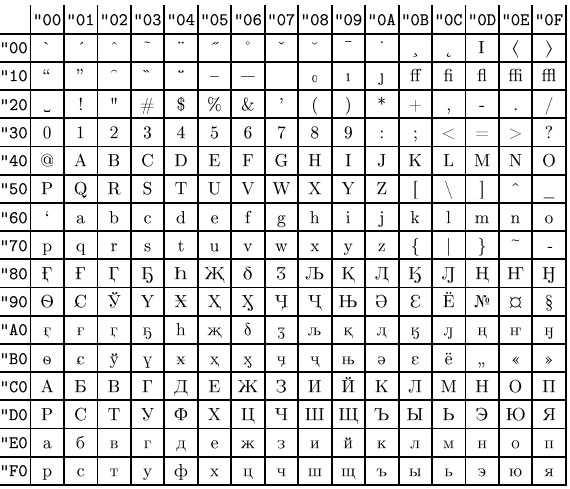
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
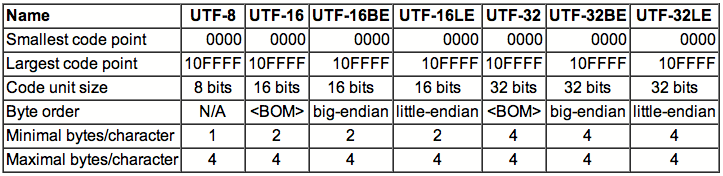
Юникод (Unicode)
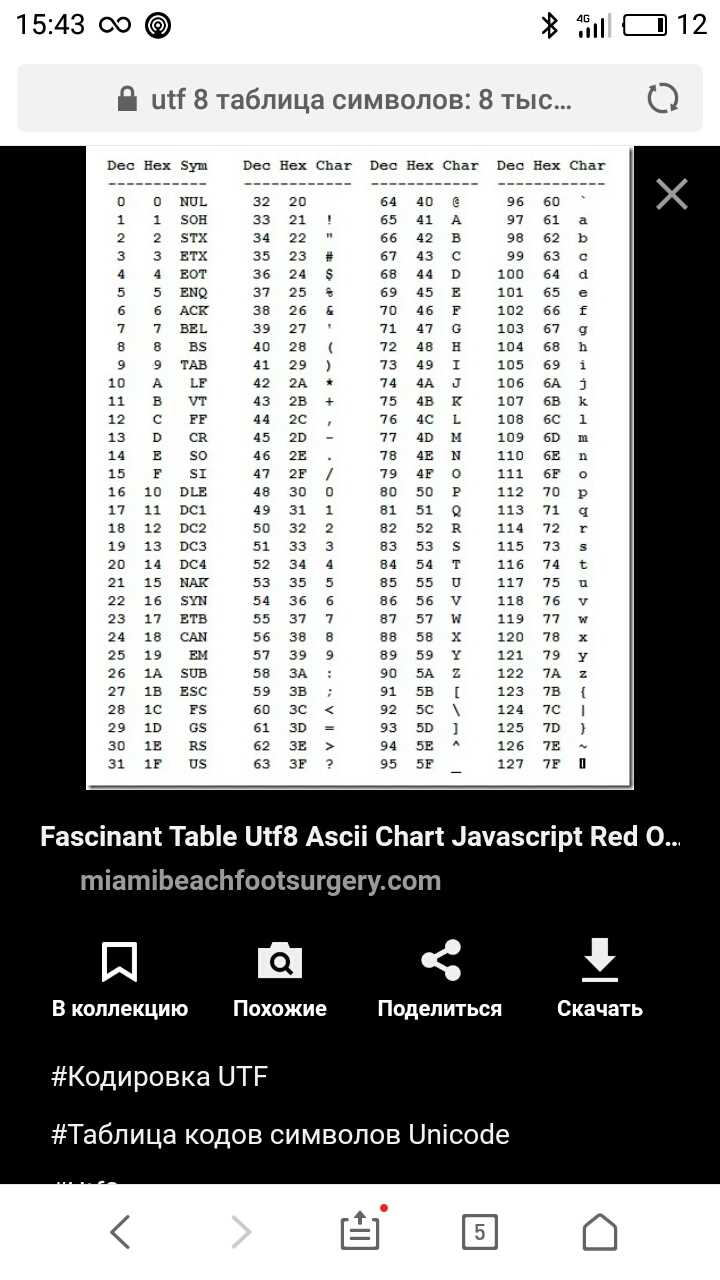
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “U+xxxx” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format): UTF-8, 16, 32.
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС, которые использовали 8-битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “Вид-Кодировка-Выбрать список” и ознакомиться со всевозможными их вариантами (см. изображение).
Думаю возник резонный вопрос: “Какого лешего столько кодировок?”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта «Заметки Сис.Админа» с этим, как Вы заметили всё в порядке :).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “Как убрать кракозябры в браузере?” — разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode, в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся «базово необходимая» теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
|
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
|
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
|
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
|
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
|
|
Греческая |
||
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
|
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
|
|
Вьетнамская |
||
|
Индийские: тамильская |
||
|
Индийские: непальская |
ISCII 57002 (деванагари) |
|
|
Индийские: конкани |
ISCII 57002 (деванагари) |
|
|
Индийские: хинди |
ISCII 57002 (деванагари) |
|
|
Индийские: ассамская |
||
|
Индийские: бенгальская |
||
|
Индийские: гуджарати |
||
|
Индийские: каннада |
||
|
Индийские: малаялам |
||
|
Индийские: ория |
||
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
||
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
Иногда открыв файл, созданный при помощи Microsoft Word и присланный нам по почте, скайпу или другим способом, мы вместо привычных русских слов видим какие-то странные иероглифы. Мы недоумеваем, что же такое нам прислали, связываемся с отправителем, а он говорит, что у него все нормально открывается. Суть данной проблемы скорее всего состоит в том, что файл был сохранен не в той кодировке, что стоит по умолчанию в вашей программе. Чтобы исправить ситуацию необходимо всего лишь поменять кодировку файла и сейчас мы узнаем, как это сделать.
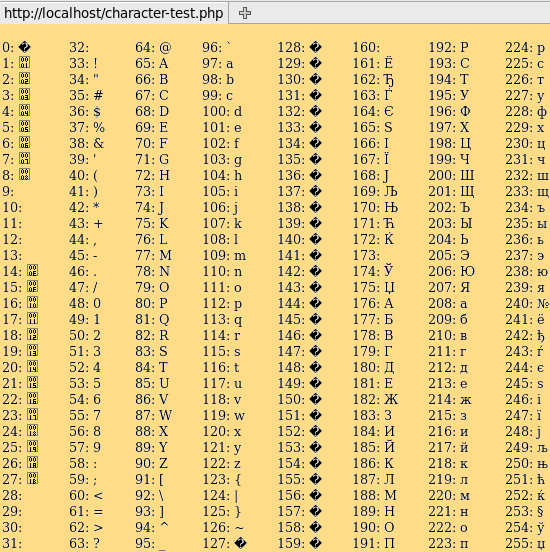


В данном примере будет использоваться Microsoft Word 2010 но принцип решения нашей задачи будет таким же и во всех остальных версиях программы. Итак, открываем наш «проблемный» документ, переходим в меню Файл
и нажимаем на пункте Параметры
.
Нажимаем Ок
и закрываем наш документ. Затем снова открываем его и перед нами должно появится окошко Преобразование файла
, в нем нам нужно выбрать пункт Кодированный текст
.
После этого появится другое окно, в котором нам нужно будет выбрать кодировку для своего файла. Ставим галочку на пункте Другая
и в поле выбора пробуем методом перебора различные кодировки, до тех пор пока не получим результат. В окне Результат
вы можете увидеть, как меняется текст в зависимости от выбранной вами кодировки.
Если вышеописанный метод не помог исправить проблему, то возможно она кроется не в неправильной кодировке, а в отсутствии на вашем компьютере шрифта, с использованием которого создавался данный документ. В таком случае вам придется уточнить у отправителя документа название шрифта и установить нужный шрифт на свой компьютер.
Остались вопросы? — Мы БЕСПЛАТНО ответим на них в
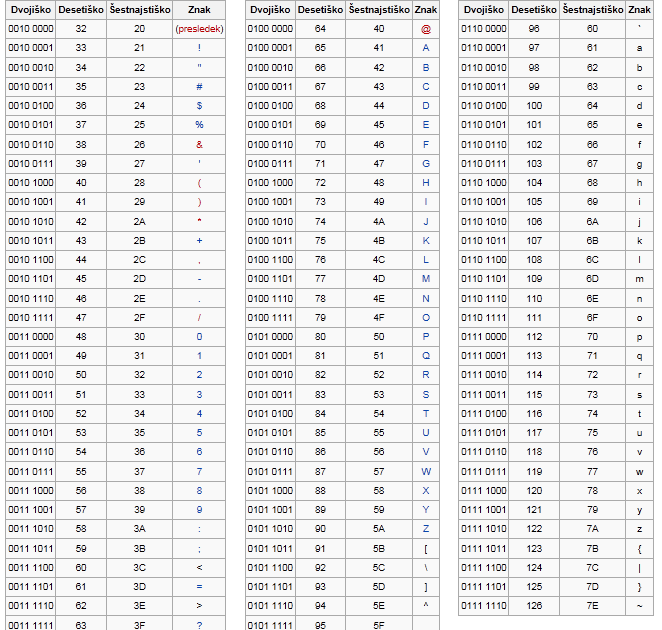
Каким образом компьютер способен воспринимать, разделять и распознавать всё множество команд? Все символы, которыми мы пользуемся, представляют собой набор чисел. Другими словами, каждая буква и любой другой знак имеет своё обозначение в виде числа. Так компьютерной системе гораздо легче и быстрее обрабатывать информацию. Но не стоит забывать о том, что в мире множество языков, а для обозначения команд используется всего 256 символов. Поэтому существуют различные кодировки.
Кодировка
— это способ сохранения информации, данных для последующего использования. Если на экране мы видим набор непонятных нам букв, это означает, что кодировка выбрана неправильно. И эти самые 256 цифр обозначают символы, записанные под их значениями, на иностранном языке. При возникновении этой проблемы компьютер при открытии файла предлагает изменить кодировку на другую, имеющуюся у него. Обычно кодировка определяется автоматически по выбранному языку (раскладке клавиатуры) на компьютере.
Другие Места, Где Кодирование Важно
Нам не просто нужно учитывать кодировку символов при программировании. Тексты могут окончательно испортиться во многих других местах.
наиболее распространенной причиной проблем в этих случаях является преобразование текста из одной схемы кодирования в другую , что может привести к потере данных.
Давайте быстро рассмотрим несколько мест, где мы можем столкнуться с проблемами при кодировании или декодировании текста.
7.1. Текстовые Редакторы
В большинстве случаев текстовый редактор-это место, откуда исходят тексты. Существует множество текстовых редакторов в популярном выборе, включая vi, Блокнот и MS Word. Большинство из этих текстовых редакторов позволяют нам выбрать схему кодирования. Следовательно, мы всегда должны быть уверены, что они подходят для текста, с которым мы работаем.
7.2. Файловая система
После того, как мы создадим тексты в редакторе, нам нужно сохранить их в какой-то файловой системе. Файловая система зависит от операционной системы, на которой она работает. Большинство операционных систем имеют встроенную поддержку нескольких схем кодирования. Однако все еще могут быть случаи, когда преобразование кодировки приводит к потере данных.
7.3. Сеть
Тексты, передаваемые по сети с использованием протокола, такого как протокол передачи файлов (FTP), также включают преобразование между кодировками символов. Для всего, что закодировано в Юникоде, безопаснее всего передавать в двоичном виде, чтобы свести к минимуму риск потери при преобразовании. Однако передача текста по сети является одной из менее частых причин повреждения данных.
7.4. Базы данных
Большинство популярных баз данных, таких как Oracle и MySQL, поддерживают выбор схемы кодирования символов при установке или создании баз данных. Мы должны выбрать это в соответствии с текстами, которые мы ожидаем сохранить в базе данных. Это одно из наиболее частых мест, где повреждение текстовых данных происходит из-за преобразования кодировки.
7.5. Браузеры
Наконец, в большинстве веб-приложений мы создаем тексты и пропускаем их через различные слои с намерением просмотреть их в пользовательском интерфейсе, например в браузере
Здесь также важно, чтобы мы выбрали правильную кодировку символов, которая может правильно отображать символы. Большинство популярных браузеров, таких как Chrome, Edge, позволяют выбирать кодировку символов в своих настройках
Кодировка отображения
Важно разделять кодировку файла и кодировку отображения. Независимо от того, в какой кодировке хранится файл, он может быть отображен и в любой другой кодировке
Это и является одной из причин проблем с кодировкой.
Например, если Вы сохранили HTML-страницу в кодировке ANSI и откроете её в браузере, вместо русских символов Вы можем получить, так называемые, «кракозябрики».
Проблемы с кодировкой отображения HTML-страницы в браузере Firefox
В данном случае нам надо убедиться, что кодировка файла совпадает с кодировкой отображения файла в браузере. Для этого в Firefox кликните иконку меню, а потом пункт «Кодировка». Если такого у Вас нет, кликните пункт «�?зменить» и добавьте элемент «Кодировка» в меню.
Смена кодировки отображения HTML-страницы в браузере Firefox
Как вы видите, браузер отображает файл в кодировке «Юникод» (например, UTF-8) , в то время как файл был сохранён в кодировке ANSI (например, Windows-1251) . Выбрав нужную кодировку, мы получим нужный нам результат.
Проблема с кодировкой решена
В случае с Notepad++ также имеется возможность выбора кодировки отображения. Для этого кликните пункт меню «Кодировки», а потом нужный вариант используемой для отображения кодировки.
Смена кодировки отображения HTML-страницы в Notepad++
В данном случае я изменил кодировку отображения ANSI на UTF-8 (без BOM) .
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить…
Русские буквы в файлах properties
Для чтения файлов properties используются методы загрузки ресурсов, которые
работают специфичным образом. Собственно для чтения используется метод
Properties.load, который не использует file.encoding (там в
исходниках жёстко указана кодировка ISO-8859-1), поэтому единственный способ
указать русские буквы — использовать формат «uXXXX» и утилиту .
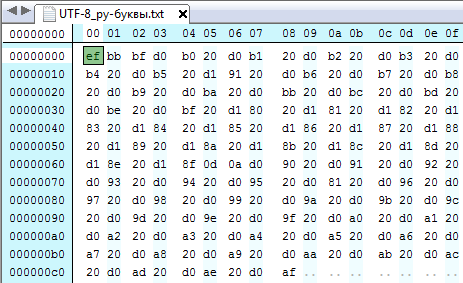

Метод Properties.save работает по разному в версиях JDK 1.1 и 1.2. В версиях
1.1 он просто отбрасывал старший байт, поэтому правильно работал только с
англицкими буквами. В 1.2 делается обратное преобразование в «uXXXX», так что
он работает зеркально к методу load.
Если файлы properties у Вас загружаются не как ресурсы, а как обычные файлы
конфигурации, и Вас не устраивает такое поведение — выход один, написать
собственный загрузчик.
Неправильная кодировка результатов из базы данных MySQL
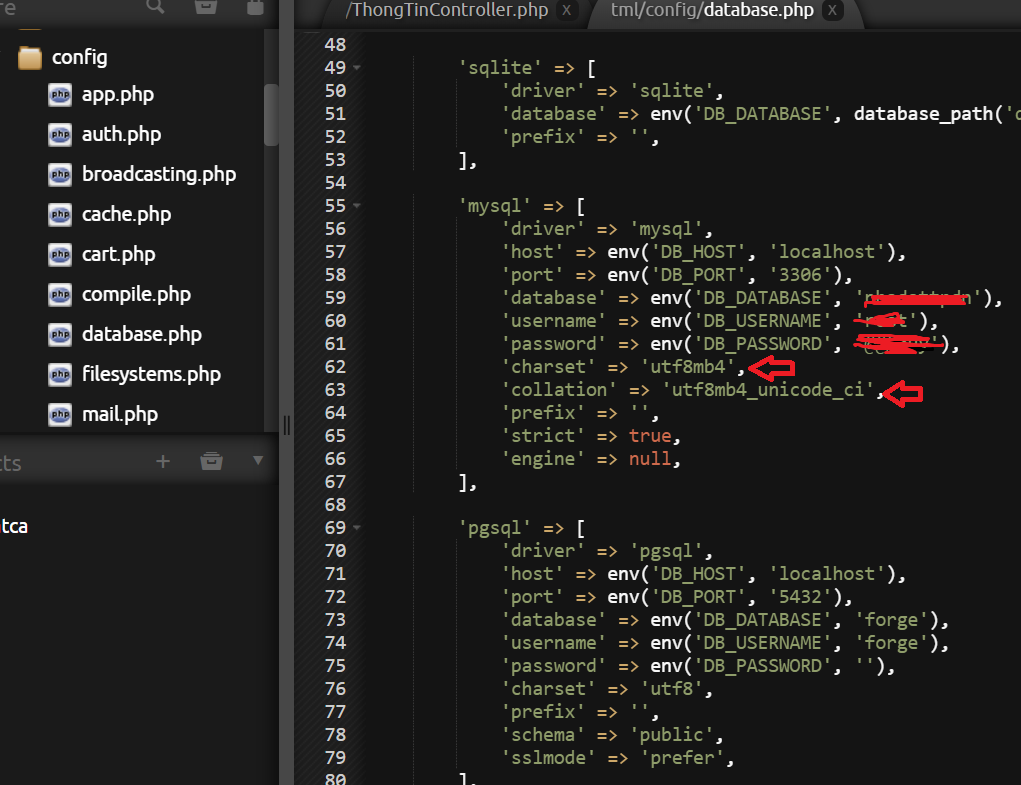
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8. Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin
Для этого:
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename); if ($this->mysqli->connect_error) { $this->errorHandler_c->logError(1, ‘Connect Error (‘ . $this->mysqli->connect_errno . ‘) ‘ . $this->mysqli->connect_error, $_SERVER ); } $this->mysqli->query(«SET NAMES UTF8»); $this->mysqli->query(«SET CHARACTER SET UTF8»); $this->mysqli->query(«SET character_set_client = UTF8»); $this->mysqli->query(«SET character_set_connection = UTF8»); $this->mysqli->query(«SET character_set_results = UTF8»);
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
Совместно с двумя российскими и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
![]()
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
GB2312、GBK、GB18030
Кривые орехи кажутся идеальными, этого достаточно! !
Но когда дело дошло до Китая, китайцы увидели достаточно шаров. В Великом Китае около 80 000 человек. Эти 255 находятся далеко.
Поэтому китайцы изобрели свой собственный набор символов GB2312, который был выпущен Национальным управлением стандартов Китая в 1980 году и начал применяться 1 мая 1981 года. Стандартный номер — GB2312-1980. Это код, который может быть распознан компьютером и подходит для обмена информацией между системой обработки китайских символов и системами связи китайских символов. Стандарт GB 2312 содержит в общей сложности 6763 китайских иероглифа, в том числе 3755 китайских символов первого уровня и 3008 китайских символов второго уровня. В то же время GB 2312 включает латинские буквы, греческие буквы, японские буквы хирагана и катакана и русские буквы кириллицы. 682 символа полной ширины. Появление GB 2312 в основном отвечает потребностям китайских иероглифов в компьютерной обработке. Содержащиеся в нем китайские иероглифы покрывают 99,75% частоты использования в материковом Китае.
Таким образом, китайский народ самостоятельно исследовал и разработал и отменил странные символы после 127-го. Правило: значение символа меньше 127 совпадает с оригиналом, но когда два символа больше 127 объединены, это означает китайский символ. Первый байт (он назвал его старшим байтом) используется от 0xA1 до 0xF7, за которым следует Один байт (младший байт) имеет значение от 0xA1 до 0xFE, поэтому мы можем комбинировать более 7000 упрощенных китайских символов. В этих кодах мы также скомпилировали математические символы, латинские греческие буквы и японские псевдонимы. Даже исходные числа, знаки препинания и буквы в ASCII были перекодированы с помощью двухбайтовых кодов. Это то, что часто называют символом «полной ширины», а символы ниже 127 называются символами «полуширины».
Однако GB 2312 не может обрабатывать редкие символы, встречающиеся в именах древних китайцев и т. Д., Что привело к появлению китайского набора символов GBK и GB 18030.
GBK — это стандарт расширения внутреннего кода китайского иероглифа, K — начальная часть «расширения» в расширенном китайском пиньине. Английское полное название — китайская спецификация внутреннего кода. Стандарт кодирования GBK совместим с GB2312, который содержит в общей сложности 21 003 китайских и 883 символов и обеспечивает 1894 кодовых пункта для создания символов. Упрощенные и традиционные символы объединяются в одну библиотеку.
GBK больше не требует, чтобы младший байт был кодом после 127. Пока первый байт больше 127, он фиксируется, чтобы указывать, что это начало китайского символа, независимо от того, следует ли за ним содержимое расширенного набора символов.
Набор символовКомпьютерная системаМинистерство информационной индустрииГосударственное бюро качества и технического надзораИнформационные технологиихарактерМонголияКореяУйгурскийхарактерОбязательные стандарты
Вышеуказанные кодыСовместим с существующими кодами ANSI (не включая коды расширения)В противном случае китайцы используют GBK, американцы используют ANSI, а китайцы вынуждены переключаться назад на коды ANSI, чтобы увидеть американские вещи.
Символы UTF-8 в веб-разработке
UTF-8 – наиболее распространенный метод кодирования символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5. Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их. В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
Универсальные кодировки
Первой версией универсальной кодировки, разработанной в рамках консорциума Юникод, была кодировка UTF 32. Для кодирования каждого символа использовалось 32 бита. Теперь была реализована возможность кодирования огромного количества знаков, но появилась другая проблема –большинству европейских стран такое число лишних символов было совершенно не нужно. Ведь документы получались очень тяжелыми. Поэтому на смену UTF 32 пришла UTF 16, ставшая базовой для всех символов, используемых в нашей стране и не только.
![]()
Но все равно оставалось достаточно много недовольных. Например, те, кто общался только на английском языке, так как при переходе с ASCII на UTF 16 их документы все равно увеличивались в размерах, причем существенно, практически в 2 раза.В результате появилась кодировка переменной длинны UTF 8, что позволило не увеличивать вес текста.



Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
header('Content-Type: charset=utf-8');
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
header('Content-Type: text/html; charset=utf-8');
Ещё один вариант для RSS ленты:
header('Content-type: text/xml; charset=utf-8');
Помните, что функция header должна быть вызвана перед любым выводом в браузер. В противном случае (если вывод в браузер уже был сделан), то уже были отправлены и заголовки. Очевидно, что в этом случае их уже невозможно поменять. Если в браузер было выведено сообщение об ошибке, то заголовки также уже были отправлены и использование header вызовет ошибку. Для проверки, были ли уже отправлены заголовки, используйте headers_sent.
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8
Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Важность кодирования символов
Нам часто приходится иметь дело с текстами, принадлежащими к нескольким языкам с различными письменными знаками, такими как латинский или арабский. Каждый символ в каждом языке должен быть каким-то образом сопоставлен с набором единиц и нулей. Действительно, удивительно, что компьютеры могут правильно обрабатывать все наши языки.
Чтобы сделать это правильно, нам нужно подумать о кодировке символов. Невыполнение этого требования часто может привести к потере данных и даже уязвимостям безопасности.
Чтобы лучше понять это, давайте определим метод декодирования текста на Java:
String decodeText(String input, String encoding) throws IOException {
return
new BufferedReader(
new InputStreamReader(
new ByteArrayInputStream(input.getBytes()),
Charset.forName(encoding)))
.readLine();
}
Обратите внимание, что вводимый здесь текст использует кодировку платформы по умолчанию. Если мы запустим этот метод с input как “Шаблон фасада-это шаблоны проектирования программного обеспечения.” и кодировка как “US-ASCII” , он выведет:
Если мы запустим этот метод с input как “Шаблон фасада-это шаблоны проектирования программного обеспечения.” и кодировка как “US-ASCII” , он выведет:
The fa��ade pattern is a software design pattern.
Ну, не совсем то, что мы ожидали.
Что могло пойти не так? Мы постараемся понять и исправить это в оставшейся части этого урока.
Расширения ASCII для России
На сегодняшний день для российских пользователей приоритетными являютсякодировка Windows1251 и кодировка юникод, а также UTF 8, которые произошли от ASCII.
Собственно говоря, у кого-то может возникнуть весьма справедливый вопрос: «А зачем вообще нужны эти кодировки текстов?»Стоит помнить, что компьютер – это всего-навсего машина, которая должна действовать четко по инструкциям. Чтобы было понятно, что нужно делать с каждым символом написанного, его представляют в виде набора векторных форм, каждый набор которых отправляет в нужное место, чтобы на экране появлялось то или иное обозначение.
За формирование векторных форм отвечают шрифты, а сам процесс кодирования зависит от операционной системы, а также используемых в ней программ. Таким образом, каждый текст по своей сути – это некоторый набор байтов, в каждом из них представлена кодировка одного написанногосимвола. А программа, занимающаяся отображением напечатанной информации на экране (это может быть браузер или текстовый процессор), разбирает код, находит подходящее отображение по его коду в таблице кодировок, преобразует в необходимую векторную форму и отображает в текстовом файле.
Кодировка CP866 и KOI8-R широко применялись до появления графической операционной системы, завоевавшей популярность во всем мире, — Windows. Теперь самой популярной кодировкой, поддерживающей русский, стала Windows1251.
![]()
Однако, она не единственная, поэтому у производителей шрифтов для русского, используемых в программном обеспечении, периодически даже до сих пор появляются затруднения, связанные с неверным отображением символов и появлением так называемой кракозябры. Эти несуразные иероглифы являются результатом некорректного использования таблиц кодировок, то есть при кодировании и декодировании использовались разные таблицы.
Такая же ситуация имеет место и на сайтах, блогах и прочих ресурсах, где есть информация на русском и прочих иностранных символах, отличных от английских. Данная ситуация определила основную предпосылкой создания универсальной кодировки, позволяющей кодировать текст на любом языке, даже китайском, где символов значительно больше, чем 256.
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
-
Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
-
В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.