
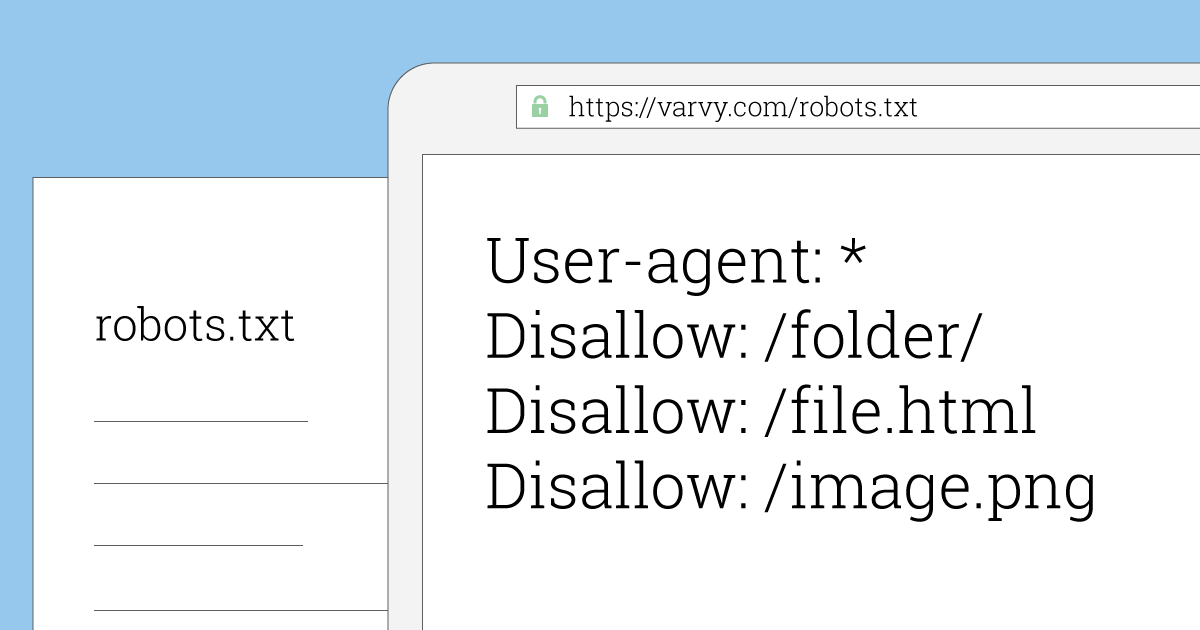
Что такое robots.txt?
robots.txt – это самый обыкновенный текстовый файл, который должен находиться в корне вашего сайта:
http://site-on.net/robots.txt
Главная цель его использования – указать в нём ваши рекомендации о том, как роботы должны сканировать (индексировать) ваш сайт. То есть это то же самое что и записка на холодильнике: мы её оставляем, её, скорее всего, найдут и прочтут (Яндекс и Гугл точно прочтут), а выполнять то, что там написано или не выполнять — это дело каждого.
Что же мы можем в него написать?
Самое главное – это запретить сканировать служебные файлы, например, XML данные, файлы конфигурации и другой мусор, который может хранится у вас на сервере. Для этого мы можем запрещать к индексированию целые папки, например, при разработке структуры данного блога, я заранее спланировал всё так, чтобы все служебные файлы находились в одной единственной папке, а уже внутри неё всё располагается как угодно. Для наглядности, вот структура моего сайта:
В корне лежат только самые главные файлы – это карта сайта (sitemap.xml), непосредственно сам robots.txt, главный файл (index.php), файл тонкой конфигурации веб-сервера (.htaccess) и иконка сайта (favicon.ico). Иконку сайта (фавикон) и карту сайта тоже можно было поместить в папку blog, но я за классику ![]()
Далее идут всего 2 папки – это папка blog, в которой я спрятал абсолютно все файлы блога от глаз роботов и рук злоумышленников, а также папка images, в которой хранятся все картинки моего сайта. Папку с картинками ни в коем случае нельзя запрещать индексировать, так как ваши картинки могут попасть в каталоги картинок Яндекса и Гугл, особенно если они уникальные, мало весят (быстро загружаются) и имеют атрибут alt в HTML теге img:
<img src="/images/screen4.png" alt="phpDesigner 8" width="778" height="472" />
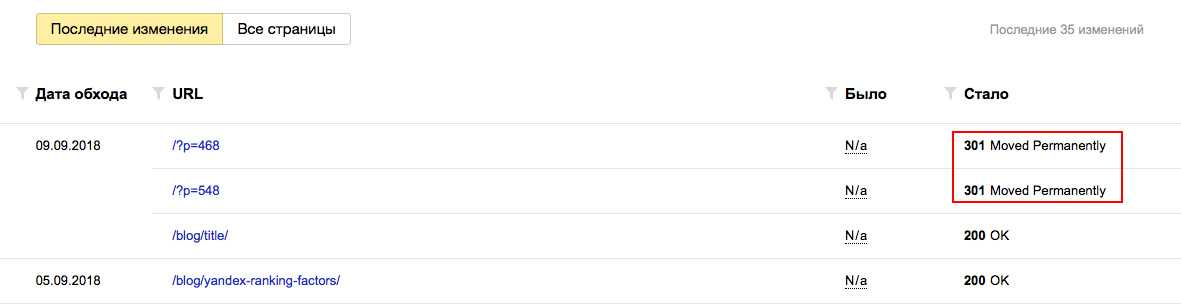
Картинки никогда не запрещаем к индексированию! С этим разобрались, но вот папку blog обязательно нужно.
Обновление 19.04.2015
Нельзя запрещать к индексации файлы стилей (css, js, шрифты), иначе поисковые системы не будут видеть дизайн вашего сайта, а это плохо, ведь они не смогут оценить его удобство. Вернее даже наоборот, они будут считать, что ваш сайт безобразен. Но это пол беды, хуже то, что если вы используете адаптивный дизайн, то Google не сможет об этом узнать и будет считать, что ваш сайт не адаптирован под мобильные устройства. А это влечёт за собой искусственное понижение позиций вашего сайта в выдаче на мобильных устройствах (смартфоны, планшеты).
Использование метатега robots для блокирования доступа к сайту
Данный метод запрета индексации страниц сайта встречается гораздо реже в повседневной жизни. Как следствие происходит это из-за что разработчики большинства CMS просто не обращают на это внимания/забывают/забивают. И тогда ответственность за поведение роботов на сайте полностью ложится на плечи вебмастеров, которые в свою очередь обходятся простейшим вариантом – robots.txt.
Но продвинутые вебмастера, которые в теме особенностей индексации сайтов и поведения роботов, используют метатег robots.
И снова небольшая выдержка из руководства от Google:
Внушает оптимизм, не правда ли? И еще:
Следовательно, все страницы, которые мы хотим запретить к индексации, а так же исключить их из индекса, если они уже проиндексированы (насколько я понял, это касается и доп. индекса Гугла), необходимо на всех таких страницах поместить метатег
Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Немного побуду кэпом и расскажу, какие еще значения (content=»…») может принимать мататег robots:
- noindex – запрещает индексацию страницы
- nofollow – запрещает роботу следовать по ссылкам на странице
- index, follow – разрешает роботу индексацию страницы и переход по ссылкам на этой странице
- all – аналогично предыдущему пункту. По большому счету, бесполезная директива, эквивалентна отсутствию самого метатега robots
- none – запрет на индексацию и следование по ссылкам, эквивалентно сочетанию noindex,nofollow
- noarchive – запрет поисковику выводить ссылку на кеш страницы (для Яндекса это «копия», для Google это «сохраненная копия»)
Так как в справке Яндекса нижеследующие параметры не описаны, то они, скорее всего, там и не сработают. Так что эти параметры только для Google:
- noimageindex – запрет на индексацию изображений на странице
- nosnippet – запрет на вывод сниппета в результатах поиска (при этом так же удаляется и сохраненная копия!)
- noodp – запрет для Google на вывод в качестве сниппета описания из каталога DMOZ
Вроде все, осталось только сказать, что количество пробелов, положение запятой и регистр внутри content=»…» здесь не играет никакой роли, но все же для красоты лучше писать как положено (с маленькой буквы, без пробелов и разделяя атрибуты запятой).
Короче говоря, чтобы полностью запретить индексацию ненужных страниц и появление их в поиске необходимо на всех этих страницах разместить метатег .
Так что если вам известны все страницы (наборы страниц, категории и т.д.), которые не должны попасть в индекс и есть доступ к редактированию их содержания (конкретно, содержания внутри тега ), то можно обойтись без запрещающих директив в файле robots.txt, но разместив на страницах метатег robots. Данный вариант, как вы понимаете, является эффективным и предпочтительным.
Рекомендую к прочтению:
- Мануал Google «Блокировка индексирования при помощи атрибута noindex»
- Мануал Яндекса «Как удалить страницы из поиска»
Итак, у нас остался последний нераскрытый вопрос, и он о внутренних ссылках.
Директивы метатега robots и X-Robots-Tag
Два метода управления индексацией отличаются синтаксисом и способом внедрения. Метатег robots размещают в html-коде страницы и заполняют его атрибуты — параметры с именем робота (name) и командами для него (content). Тег x-robots добавляют в файл конфигурации и атрибуты в этом случае не используют.
Запрет индексации контента роботом Google с помощью метатега robots выглядит так:
Запрет индексации контента роботом Google с помощью тега x-robots имеет такой вид:
При этом у метатегов robots и X-Robots-Tag общие директивы — команды для обращения к роботам поисковиков. Рассмотрим список актуальных директив для разных поисковых систем и их функции.
Функции директив и их поддержка разными поисковиками
| НАЗВАНИЕ | ФУНКЦИЯ ДИРЕКТИВЫ | YANDEX | BING | YAHOO! | |
| index/noindex | Разрешение/запрет индексации текста. Чаще всего используют noindex, чтобы скрыть страницу из результатов выдачи. | + | + | + | + |
| follow/nofollow | Разрешение/запрет перехода роботом по ссылкам на странице. | + | + | + | + |
| archive/noarchive | Разрешение/запрет показа в поиске кэшированной версии страницы. | + | + | + | + |
| all/none | Сочетает в себе две директивы, отвечающие за индексацию текста и ссылок. all — эквивалент index, follow (используется по умолчанию). none — эквивалент noindex, nofollow. | + | + | – | + |
| nosnippet | Запрет отображения сниппета (фрагмента текста) или видео в результатах поиска. | + | – | + | – |
| max-snippet | Ограничивает размер сниппета. Формат директивы: max-snippet:, где number — количество символов. | + | – | – | + |
| max-image-preview | Задает максимальный размер изображений для показа страницы в поиске. Формат директивы: max-image-preview:, где setting может иметь значение none, standard или large. | + | – | – | + |
| max-video-preview | Ограничение длительности видео, которые отображаются в поиске. Значение указывают в секундах. Также можно задавать статическое изображение (0) или снимать ограничения (-1). Формат директивы: max-video-preview: | + | – | – | + |
| notranslate | Запрет перевода страницы в выдаче. | + | – | – | – |
| noimageindex | Запрет индексации изображений страницы. | + | – | – | – |
| unavailable_after | Запрет показа страницы в поиске после определенной даты. Директиву указывают в формате unavailable_after: [дата/время]. | + | – | – | – |
| noyaca | Запрет применения описания из Яндекс.Каталога в сниппете. | – | + | – | – |
В таблице приведены как запрещающие, так и разрешающие команды. Однако индексация открытого» содержимого сайта происходит по умолчанию и директивы вроде index и follow можно не прописывать.
Сравнение директив Google и Яндекс
Как видно в таблице выше, у Google и Яндекса есть как общие, так и уникальные команды. В Google это nosnippet, max-snippet, max-image-preview, max-video-preview, notranslate, noimageindex, unavailable_after. В Яндексе — noyaca.
Теперь рассмотрим, какие из директив можно использовать в метатеге robots, а какие — в теге X-Robots, чтобы их понимали боты Яндекса и Google.
| Директива | Метатег robots Google | Заголовок X-Robots-Tag Google | Метатег robots Yandex | Заголовок X-Robots-Tag Yandex |
| noindex | + | + | + | + |
| nofollow | + | + | + | + |
| noarchive | + | + | + | + |
| index/ follow/ archive | + | + | + | – |
| none | + | + | + | + |
| all | + | + | + | – |
| nosnippet | + | + | – | – |
| max-snippet | + | + | – | – |
| max-snippet | + | + | – | – |
| max-image-preview | + | + | – | – |
| max-video-preview | + | + | – | – |
| notranslate | + | + | – | – |
| noimageindex | + | + | – | – |
| unavailable_after | + | + | – | – |
| noyaca | – | – | + | – |
robots.txt в WordPress
В WordPress запрос на страницу обрабатывается отдельно и для него «налету» через PHP создается контент файла robots.txt. Поэтому не рекомендуется физически создавать файл robots.txt в корне сайта! Потому что при таком подходе никакой плагин или код не сможет нормально изменить этот файл, а вот динамическое создание контента для страницы позволит гибко его изменять.
Изменить содержание robots.txt можно через:
- Хук robots_txt.
- Хук do_robotstxt.
Рассмотрим как использовать оба хука.
По умолчанию WP 5.5 создает следующий контент для страницы :
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: http://example.com/wp-sitemap.xml
Смотрите do_robots() — как работает динамическое создание файла robots.txt.
Этот хук позволяет дополнить уже имеющиеся данные файла robots.txt. Код можно вставить в файл темы functions.php.
// Дополним базовый robots.txt
// -1 before wp-sitemap.xml
add_action( 'robots_txt', 'wp_kama_robots_txt_append', -1 );
function wp_kama_robots_txt_append( $output ){
$str = '
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
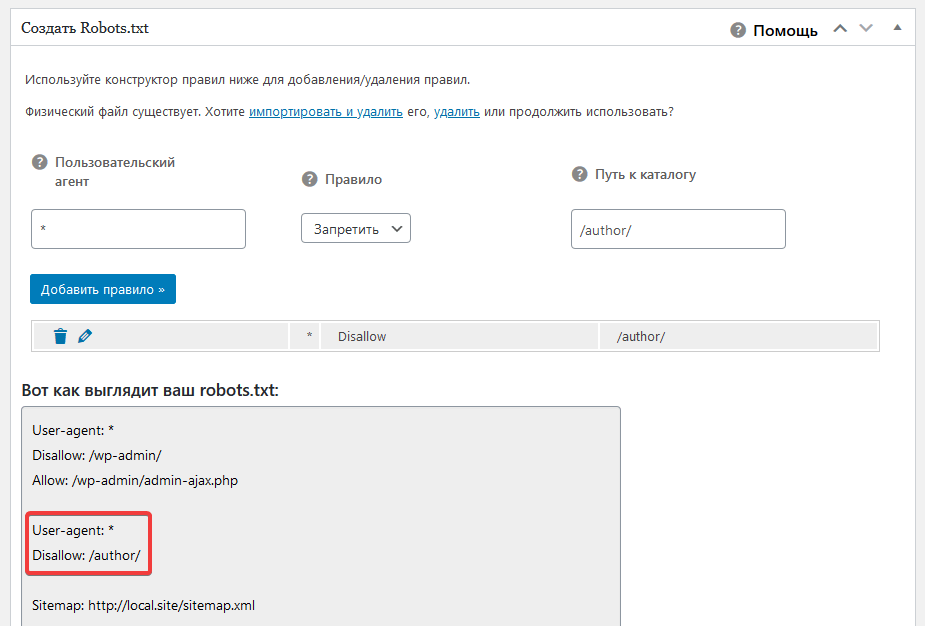
Disallow: /author/ # Архив автора.
Disallow: */embed # Все встраивания.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat
';
$str = trim( $str );
$str = preg_replace( '/^+(?!#)/mU', '', $str );
$output .= "$str\n";
return $output;
}
В результате перейдем на страницу и видим:
User-agent: * Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed # Все встраивания. Disallow: */page/ # Все виды пагинации. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat Sitemap: http://wptest.ru/wp-sitemap.xml
Обратите внимание, что мы дополнили родные данные ВП, а не заменили их. Этот хук позволяет полностью заменить контент страницы
Этот хук позволяет полностью заменить контент страницы .
add_action( 'do_robotstxt', 'wp_kama_robots_txt' );
function wp_kama_robots_txt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "\r\n", $lines );
die; // обрываем работу PHP
}
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.


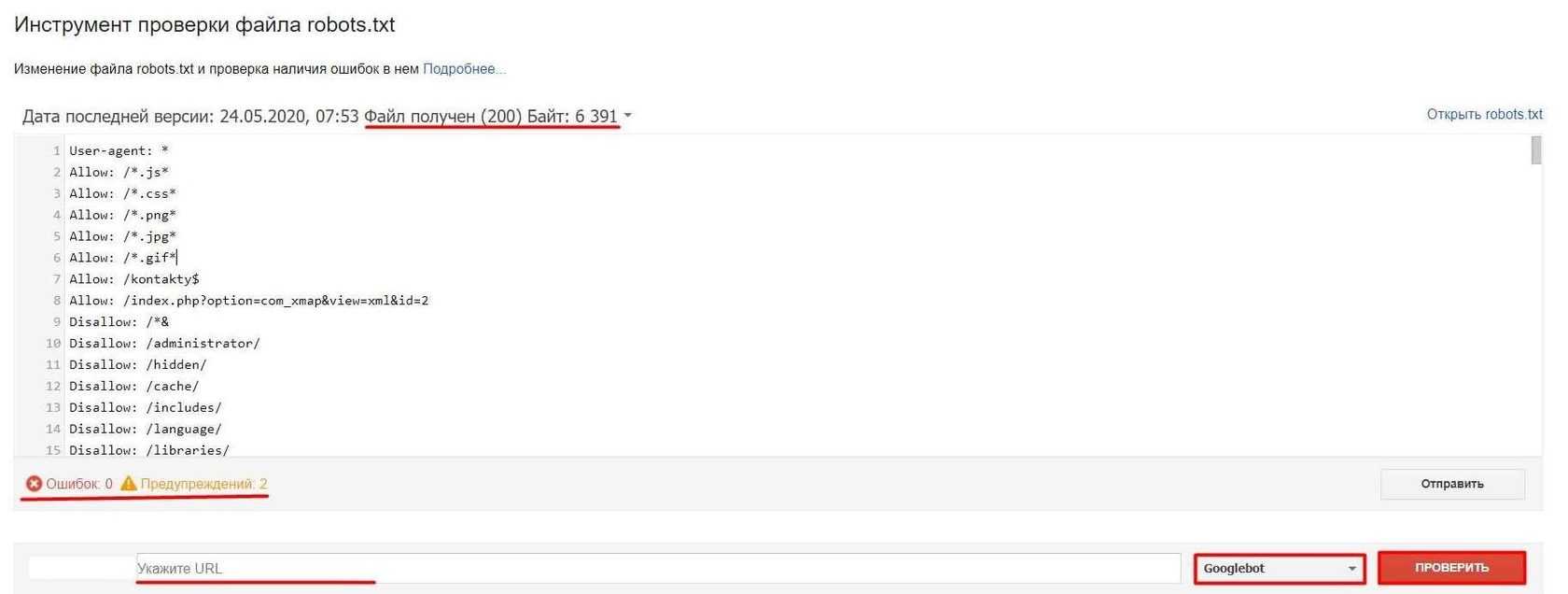


![]() Проверка документа в yandex
Проверка документа в yandex
Ниже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
![]() Отсутствие ошибок в валидаторе
Отсутствие ошибок в валидаторе
Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
![]() Проверка папок и страниц в яндексе
Проверка папок и страниц в яндексе
Проверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
https://youtube.com/watch?v=X49aL38kp28
Разрешить индексацию robots.txt — Allow
Allow — это директива разрешающая поисковому роботу обход страниц. Она является противоположностью директиве Disallow. В ней, как и в Disallow возможно использование спецсимволов * и $.
Давайте рассмотрим пример использования директивы Allow:
User-agent: * Disallow: / Allow: /blog
Данные инструкции разрешают обход раздела /blog, при этом весь остальной сайт остается недоступен для индексирования.
Пустой «Disallow: » = «Allow: /». Обе директивы разрешают полный обход сайтаПустой «Allow: » = «Disallow: /». Обе директивы полностью запрещают обход сайта.
Эта информация дана для справки. Широкого практического применения она не получает.
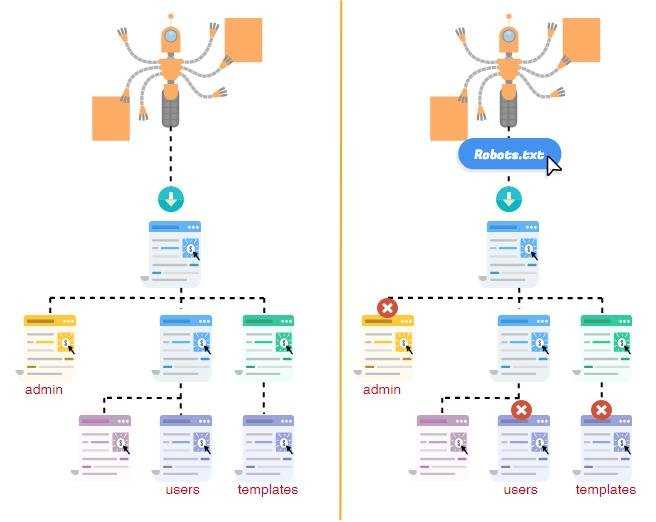
Что такое файл Robots.txt?
![]()
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Чем полезен файл Robots.txt?
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
Как создать файл Robots.txt?
По умолчанию файл robots.txt выглядит следующим образом:
![]()
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
Директивы для сканирования поисковыми системами
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
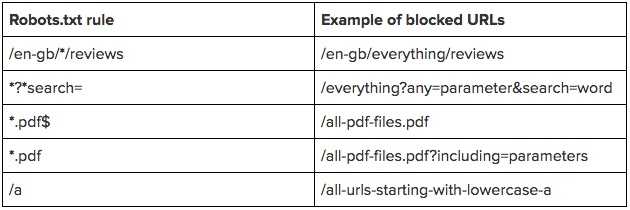
Правильное использование универсальных символов
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
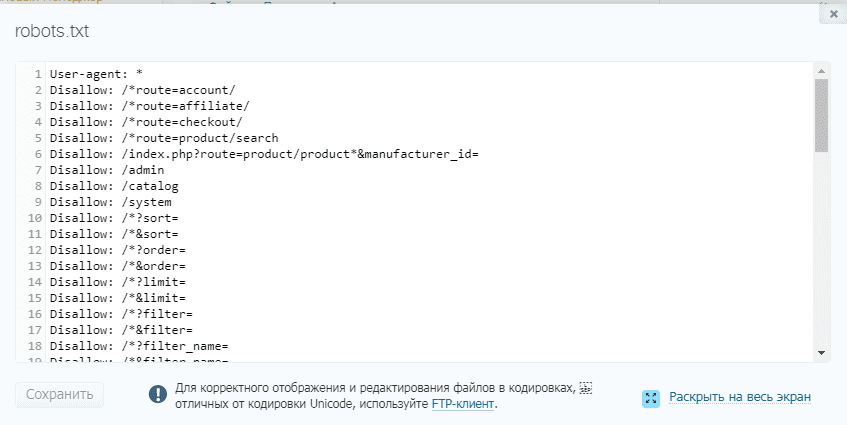
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Долгий ответ сервера
Время ответа сервера ― это время, за которое запрос клиента в браузере доходит до сервера и клиент получает ответ сервера. Время отклика измеряется в TTFB (Time To First Byte) ― время до первого байта, или сколько миллисекунд прошло между вашим запросом и ответом сервера. Google рекомендует стремиться к тому, чтобы время отклика было менее 200 миллисекунд. TTFB больше 500 мс уже является проблемой.
Если при обращении поискового робота к серверу, он получает долгий ответ, то робот может не просканировать часть страниц..
Как проверить время ответа сервера
Проверить время ответа сервера можно с помощью сервисов:
- webpagetest.org
- loading.express. Есть плагин для Chrome.
- webmaster.yandex.ru
- sitespeed.me
- gtmetrix.com
- dotcom-tools.com
Возможные причины долгого ответа сервера
Среди возможных причин можно выделить следующие:
- недостаточный объем ресурсов сервера (слабый процессор, недостаточно памяти);
- не оптимизирована работа сервера;
- отсутствие оптимизации скорости загрузки сайта. Не минимизированы файлы CSS/JS, не сжаты изображения и т.д.
- отсутствие кэширования.
Если вы оптимизировали скорость загрузки сайта, но у вас остались проблемы с долгим ответом сервера, стоит попробовать другие хостинги. Например, мы предлагаем виртуальный хостинг с серверами в Украине, Нидерландах и США . Ваш сайт более требовательный и нужно больше мощностей? Не проблема. У нас есть VIP пакеты с большим объемом ресурсов или можно взять VPS.
Возьмите хостинг на тест и проверьте сами. 30 дней бесплатно!
Пробуйте надежный хостинг с аптаймом 99,5%! Наша теплая поддержка на связи 24/7
Тестировать 30 дней бесплатно
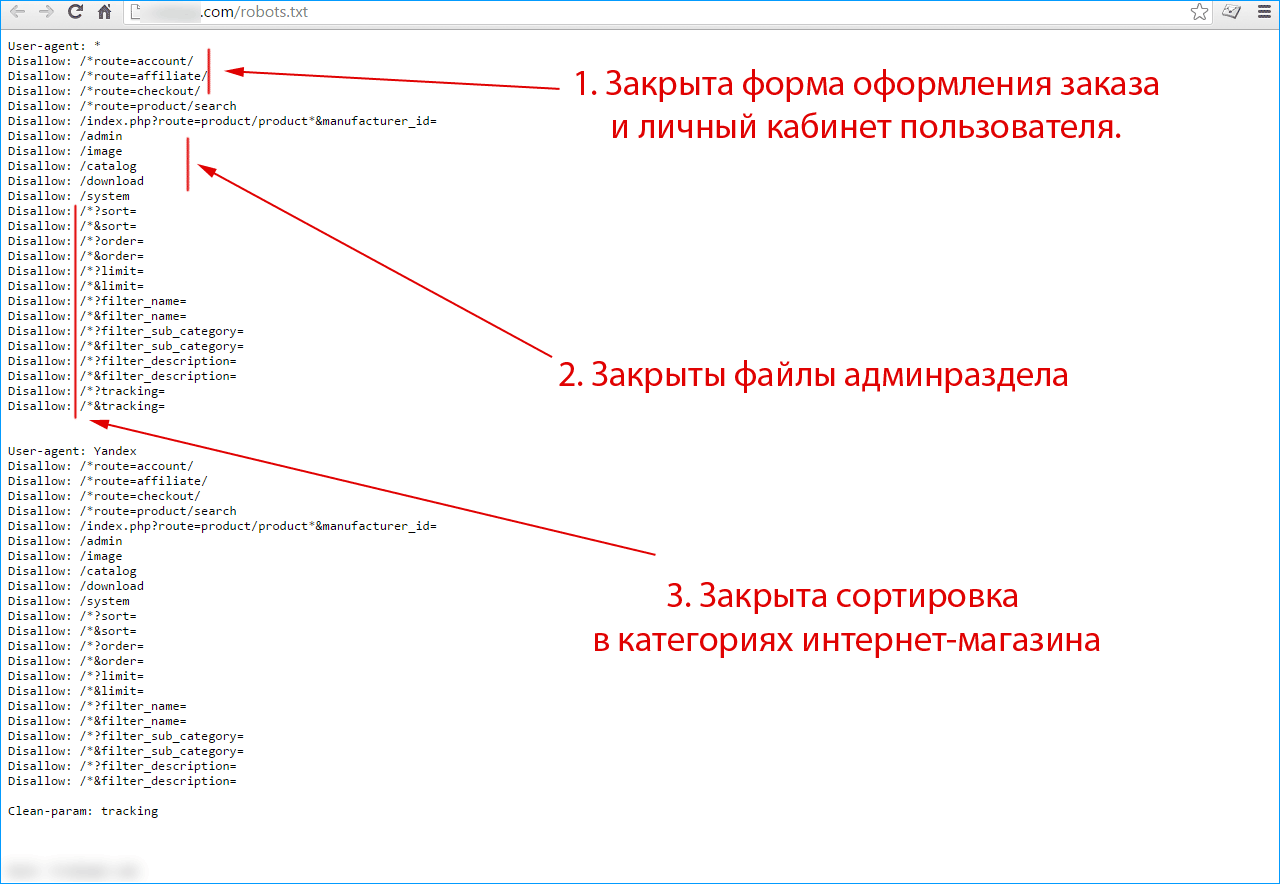
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.




В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
![]() Доступная для пользователей ссылка
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
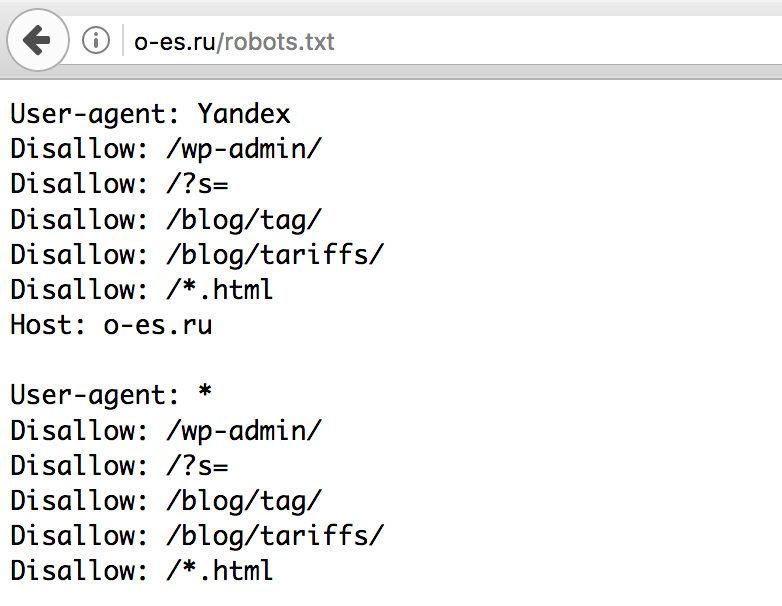
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Роль файла robots.txt для индексации поисковыми машинами
При корректной настройке robots.txt Google и Yandex будут учитывать ее в поиске. Существует вероятность, что на индексацию в других поисковиках файл не сможет повлиять.
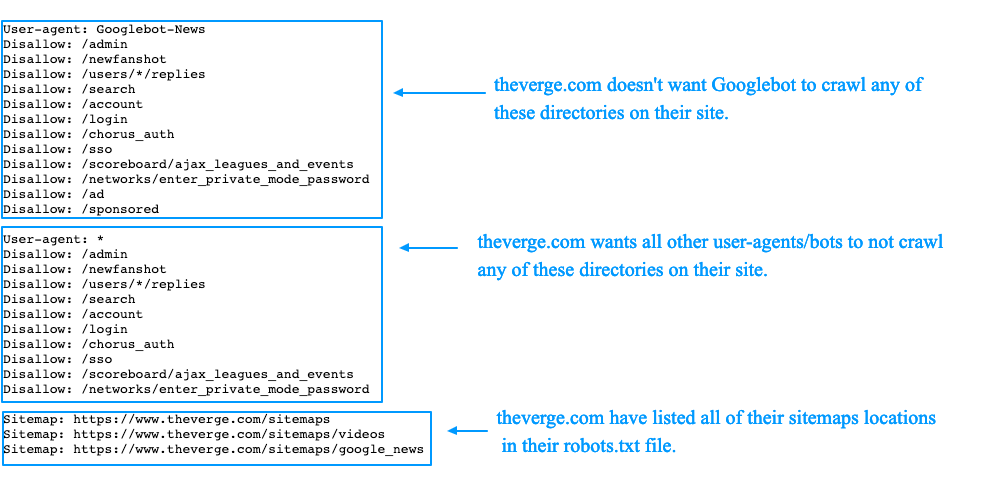
Первоначально необходимо настроить директиву User-agent. Она определяет, для какой поисковой системы предназначен файл.
User-agent: Yandex — для всех поисковых роботов Yandex.
User-agent: YandexBot определяет правила для поисковой машины индексации от “Яндекса”.
Все роботы “Гугл” реагируют на директиву User-agent: Googlebot.
Директива, прописывающаяся для для всех роботов, кроме Google и Yandex, выглядит так: User-agent: *. User-agent говорит роботу, что нужно совершить действие. после нее в коде должна отображаться информация о том, какое именно действие требуется от робота.
Директивы для отдельных сервисов “Яндекса”:
- YandexMedia отвечает за данные мультимедиа;
- YandexAddurl обращается к web-документу, который загрузили, используя форму “добавить URL”;
- YandexMetrika для робота “Яндекс. Метрики”;
- YandexImageResizer используется для мобильных сервисов;
- YandexImages отвечает за картинки “Яндекса”;
- YandexVideo — для робота, оценивающего видео на “Яндексе”;
- YandexBlogs нужен для поиска по блогам;
- YandexFavicons отвечает за индексацию пиктограмм интернет-ресурсов;
- YandexDirect — робот для “Яндекс. Директа”;
- YandexNews, соответственно, для новостей на “Яндексе”;
Для сервисов Google файл robots.txt имеет другие директивы:
- AdsBot-Google проверяет характеристики целевого web-документа;
- Googlebot-News предназначен для новостей;
- Googlebot-Image — работает с картинками “Гугла”;
- AdsBot-Google-Mobile-Apps нужен для приложений смартфонов;
- Googlebot-Video — директива для видеохостингов.
Другие поисковые системы применяют свои директивы. Mail.ru для поиска в Mail.ru, sturp для Yahoo, bingbot для Bing.
SEO best practices with robots meta directives
-
All meta directives (robots or otherwise) are discovered when a URL is crawled. This means that if a robots.txt file disallows the URL from crawling, any meta directive on a page (either in the HTML or the HTTP header) will not be seen and will, effectively, be ignored.
-
In most cases, using a meta robots tag with parameters «noindex, follow» should be employed as a way to to restrict crawling or indexation instead of using robots.txt file disallows.
-
It is important to note that malicious crawlers are likely to completely ignore meta directives and as such, this protocol does not make a good security mechanism. If you have private information that you don’t want to make publicly searchable, choose a more secure approach, such as password protection, to keep visitors from viewing confidential pages.
-
You do not need to use both meta robots and the x-robots-tag on the same page – doing so would be redundant.
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
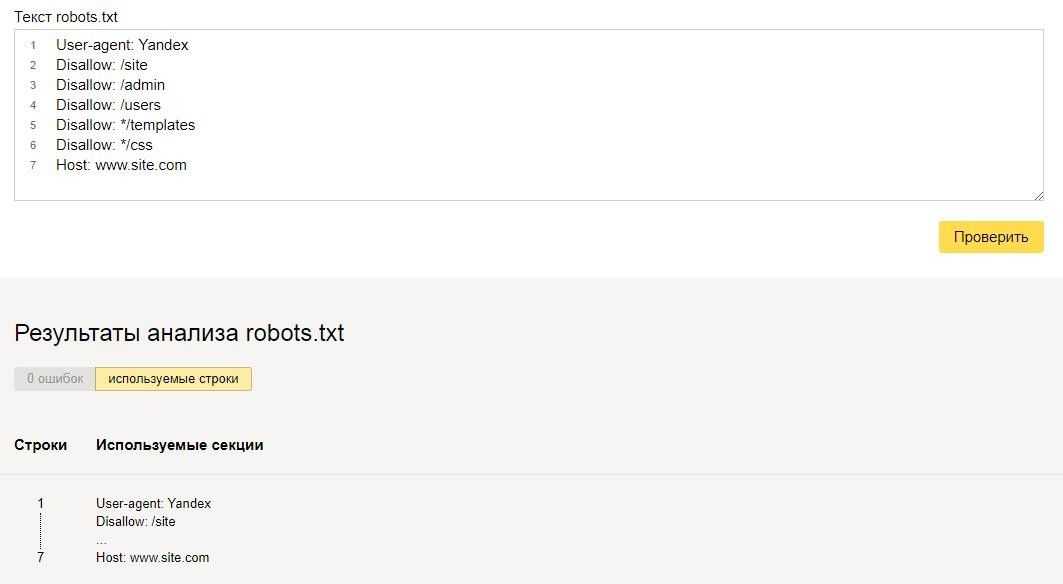
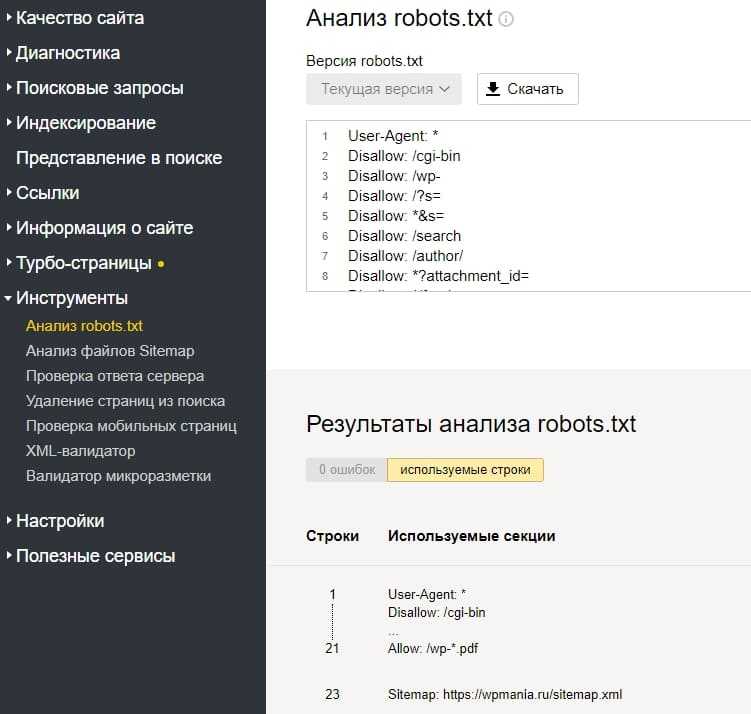
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
![]()
Также можно скачать другие версии файла или просто ознакомиться с ними.
![]()
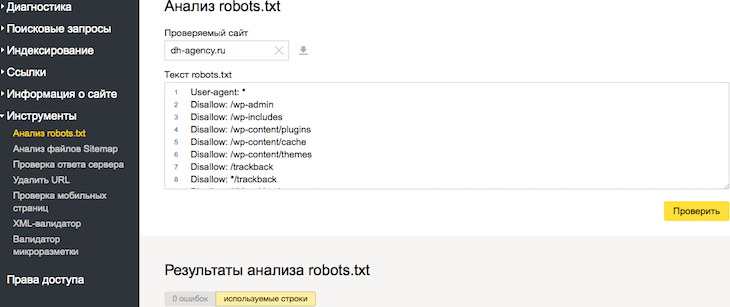
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
![]()
Как видим из примера все работает нормально.
![]()
![]()
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
![]()
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.


![]()
Важно! Ресурсы-домены в этом случае выбирать нельзя. Теперь мы видим:
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
![]()
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
![]()
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
![]()
Подписывайтесь на наши социальные сети
Заключение
Конечно, не стоит закрывать все ссылки на сайте, обязательно ссылайтесь на полезные ресурсы для посетителя и никаких nofollow, noindex вам не понадобится. Потому что роль данных тегов важна с точки зрения индексации, но не с точки зрения продвижения вашего сайта. Ну к примеру, я не использовал данный тег и мои сайты ранжировались нормально. Это скорее некая дополнительная фича к robots.txt.
Не злоупотребляйте спамными техниками и прочими черными методами продвижения сайтов и старайтесь не слушать биржи о покупке ссылок и волшебном продвижении в ТОП 10, и ничего за это вам не будет. Поймите – их цель продать вам продукт и они будут вливать вам как можно больше воды. Можно продвигать сайт без них, есть конкретные кейсы и примеры (точнее без покупки ссылок), ну а в сегодняшней статье всё.
Как вы используете meta-robots name?
Используете ли вы различных ботов (googlebot, googlebotnews) для запрета индексации той или иной страницы?



