
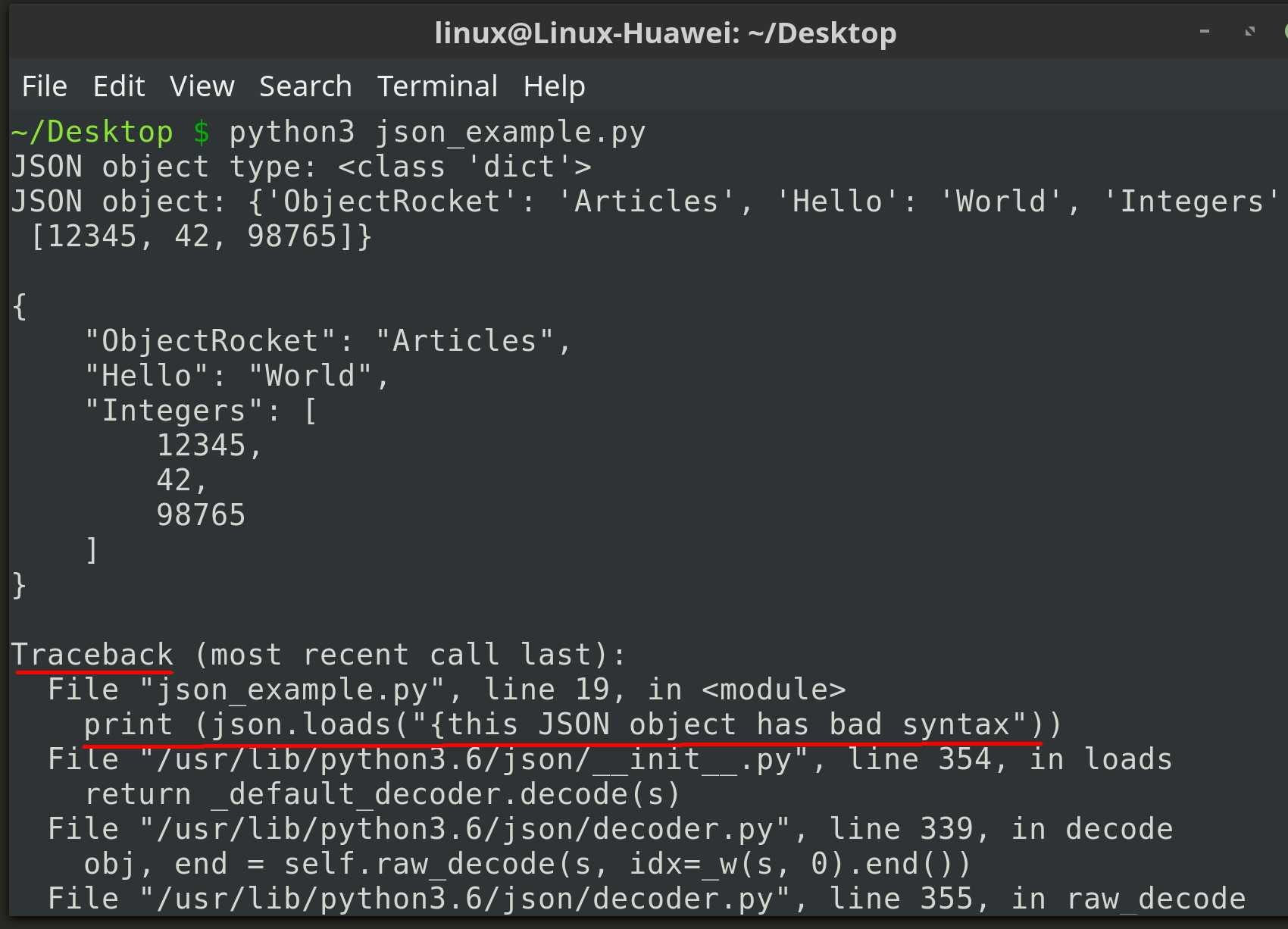
Command Line Interface¶
Source code: Lib/json/tool.py
The module provides a simple command line interface to validate
and pretty-print JSON objects.
If the optional and arguments are not
specified, and will be used respectively:
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
Changed in version 3.5: The output is now in the same order as the input. Use the
option to sort the output of dictionaries
alphabetically by key.
Command line options
-
The JSON file to be validated or pretty-printed:
$ python -m json.tool mp_films.json { "title": "And Now for Something Completely Different", "year": 1971 }, { "title": "Monty Python and the Holy Grail", "year": 1975 }If infile is not specified, read from .
-
Write the output of the infile to the given outfile. Otherwise, write it
to .
-
Sort the output of dictionaries alphabetically by key.
New in version 3.5.
-
Disable escaping of non-ascii characters, see for more information.
New in version 3.9.
-
Parse every input line as separate JSON object.
New in version 3.8.
-
Mutually exclusive options for whitespace control.
New in version 3.9.
-
Show the help message.
Footnotes
-
As noted in the errata for RFC 7159,
JSON permits literal U+2028 (LINE SEPARATOR) and
U+2029 (PARAGRAPH SEPARATOR) characters in strings, whereas JavaScript
(as of ECMAScript Edition 5.1) does not.
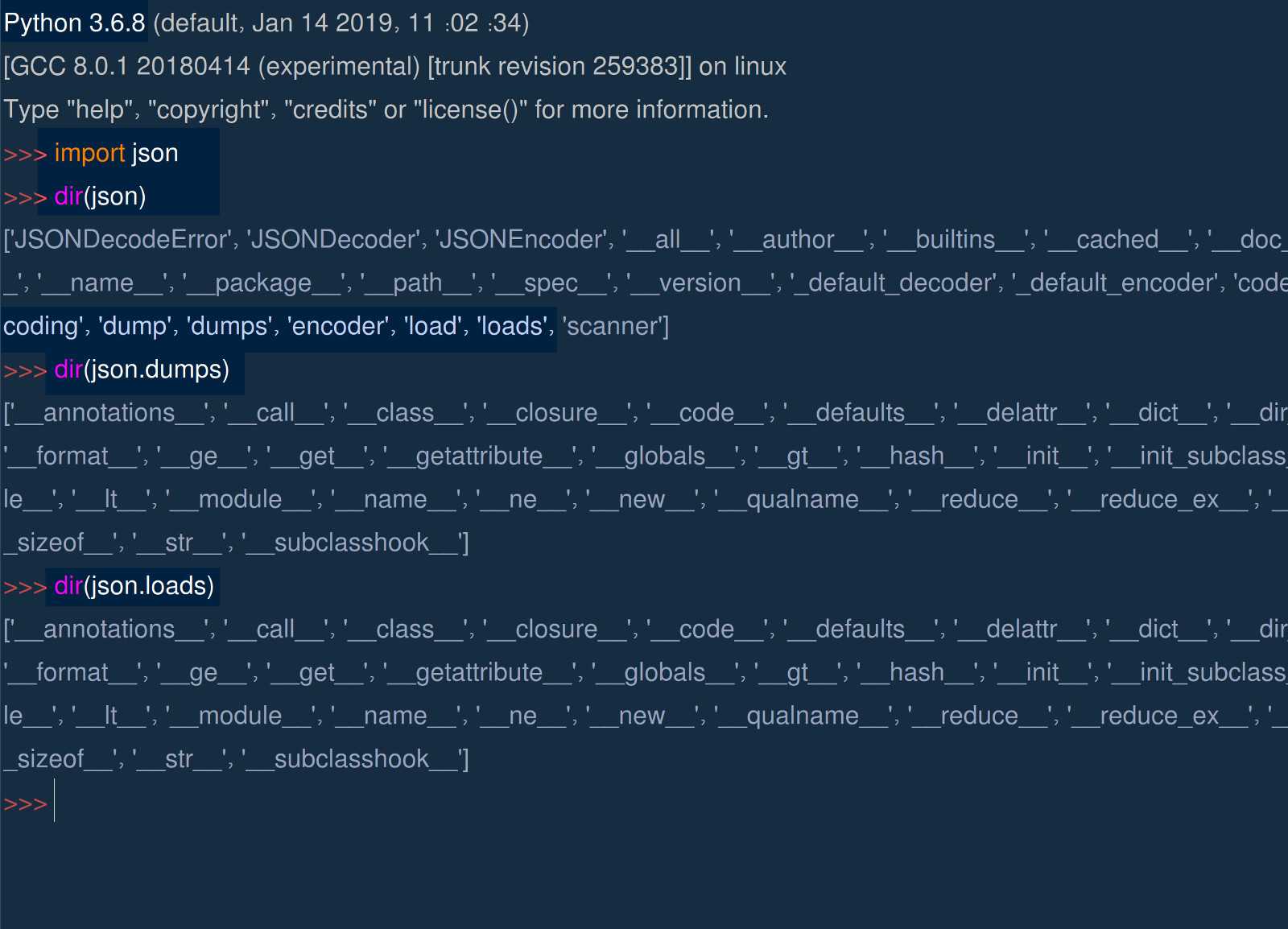
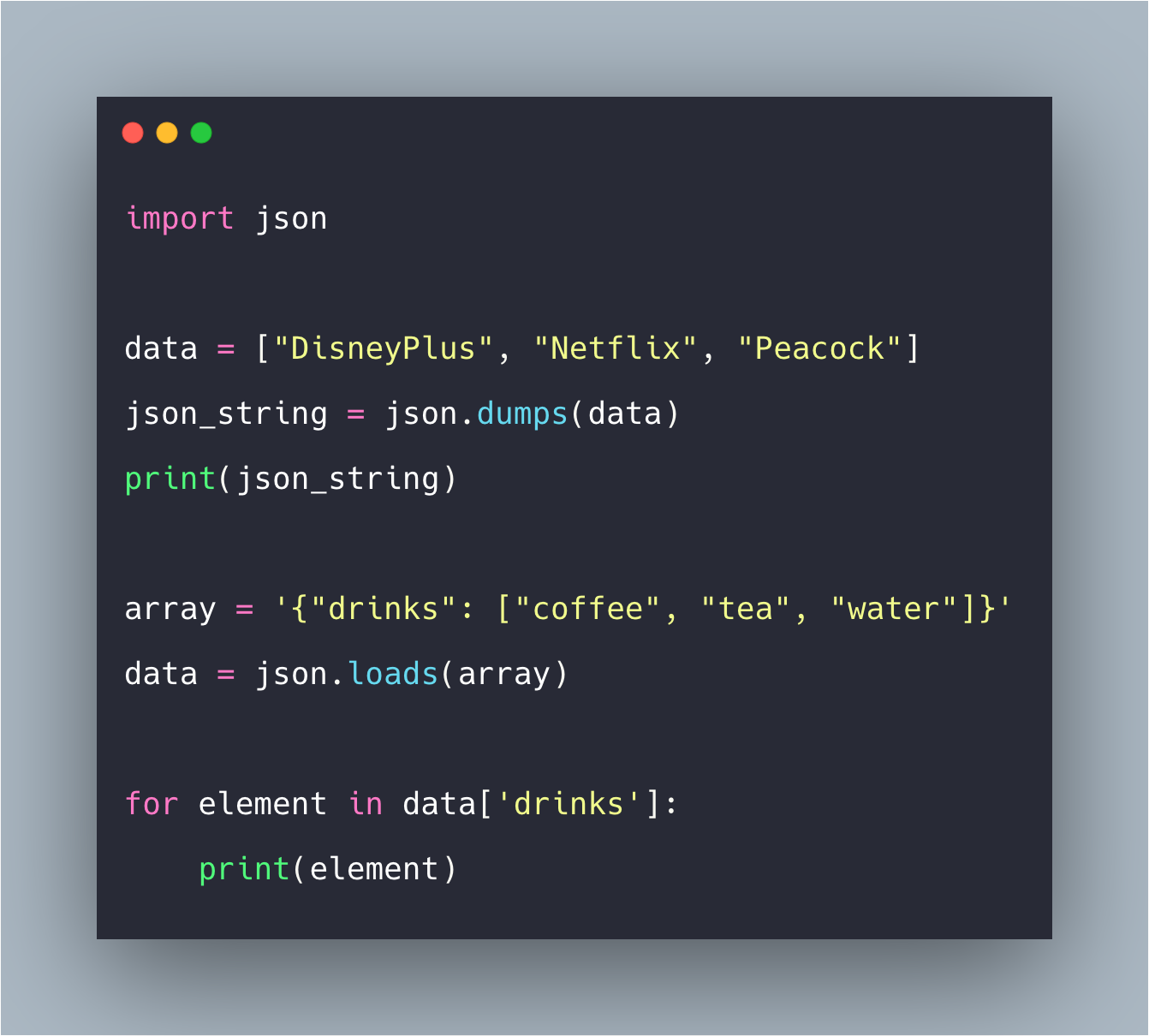
Работа с Python JSON
Python поддерживает стандартную библиотеку marshal и pickle module, а JSON API ведет себя аналогично этой библиотеке. Python изначально поддерживает функции JSON.
Кодирование данных JSON называется сериализацией. Сериализация – это метод, при котором данные преобразуются в последовательности байтов и передаются по сети. Десериализация – это процесс, обратный декодированию данных, преобразованных в формат JSON. Этот модуль включает в себя множество встроенных функций.
Давайте посмотрим на эти функции:
import json print(dir(json))
Выход:
В этом разделе мы изучим следующие методы:
- load()
- loads()
- dump()
- dumps()
Как создать DataFrame из списка словарей
Чтобы создать DataFrame из списка словарей, просто предоставьте список конструктору класса DataFrame следующим образом: DataFrame(list). Этот вызов возвращает объект DataFrame, содержащий данные списка с ключами в виде имен столбцов.
В данном случае пример выглядит следующим образом:
Результатом приведенного выше кода будет:
Основная проблема этого решения заключается в том, что вы должны убедиться, что ключи в каждом словаре корректны и согласованы друг с другом. В целевом DataFrame будет создано столько столбцов, сколько различных ключей в словарях. Если, например, ключ, связанный с именем, в одном словаре – Name, в другом – name, а в третьем – NAME, то в итоге мы получим три разных колонки (с учетом регистра) для данных об имени, что нам не нужно. Кроме того, у нас будет много значений None, потому что если в других словарях нет значений для определенного ключа, то по умолчанию у нас будет именно None.
DataFrame: таблица данных с маркированными строками и столбцами
Прежде чем мы рассмотрим, как загружать различные источники данных в DataFrame, нам необходимо четко определить формат данных, который он представляет.
DataFrame представляет собой не что иное, как типичную двумерную таблицу данных со строками и столбцами. Кроме того, каждая строка и столбец могут иметь собственное имя или метку.


Так, например, мы можем сохранить в DataFrame расписание занятий, где столбцы – это дни, строки – часы, а значения – это каждый урок или предмет. Или мы можем также хранить список вылетов рейсов, где столбцы представляют номер рейса, время вылета и пункт назначения.
Обратите внимание, что таблица может иметь один столбец или одну строку, поэтому если вы встретите данные в таком формате, они также могут быть загружены в DataFrame. Они даже могут иметь одну строку и один столбец, т.е
одно значение!
Чтобы было понятнее, я приведу пример таблицы для наглядности моих слов:
| Имя | Возраст |
| Иван | 37 |
| Петр | 42 |
| Алексей | 40 |
Таблица 1: Пример таблицы, которая может быть загружена в DataFrame
Мы будем использовать таблицу, подобную этой, в некоторых примерах данной статьи.
Чтение¶
Файл sw_templates.json:
{
"access"
"switchport mode access",
"switchport access vlan",
"switchport nonegotiate",
"spanning-tree portfast",
"spanning-tree bpduguard enable"
],
"trunk"
"switchport trunk encapsulation dot1q",
"switchport mode trunk",
"switchport trunk native vlan 999",
"switchport trunk allowed vlan"
}
Для чтения в модуле json есть два метода:
- — метод считывает файл в формате JSON и возвращает объекты Python
- — метод считывает строку в формате JSON и возвращает объекты Python
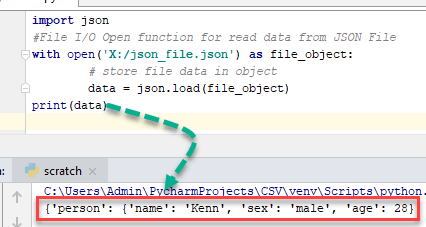
Чтение файла в формате JSON в объект Python (файл json_read_load.py):
import json
with open('sw_templates.json') as f
templates = json.load(f)
print(templates)
for section, commands in templates.items():
print(section)
print('\n'.join(commands))
Вывод будет таким:
$ python json_read_load.py
{'access': , 'trunk': }
access
switchport mode access
switchport access vlan
switchport nonegotiate
spanning-tree portfast
spanning-tree bpduguard enable
trunk
switchport trunk encapsulation dot1q
switchport mode trunk
switchport trunk native vlan 999
switchport trunk allowed vlan
Как создать DataFrame из файла Excel
Другим распространенным случаем является наличие данных в файле Microsoft Excel или в совместимой электронной таблице, например, в таблицах открытого формата из пакета LibreOffice.
Чтобы создать DataFrame из электронной таблицы или файла Excel, вы можете использовать функцию pandas read_excel, указав ей имя файла. Эта функция открывает и считывает файл и создает DataFrame с его содержимым, готовый к использованию.
На изображении ниже показаны данные, содержащиеся в электронной таблице, в данном случае созданной с помощью Google Drive и сохраненной в формате xlsx с именем data.xlsx.
![]() Электронная таблица для загрузки в pandas DataFrame
Электронная таблица для загрузки в pandas DataFrame
Для загрузки данных из файла и создания DataFrame мы будем использовать функцию read_excel. Эта функция выполняет чтение данных из исходного файла с помощью другой библиотеки. Так как в данном случае формат файла – Excel, используемая библиотека – openpyxl, которую необходимо установить с помощью команды pip install openpyxl. Если нам нужно прочитать файл в формате Open Document Format (например, в LibreOffice), то библиотека для установки – odf.
После установки необходимой библиотеки мы можем использовать функцию read_excel следующим простым способом:
Легко, не так ли? Результат на экране будет выглядеть следующим образом:
Может случиться так, что таблица, которую мы хотим прочитать, находится в определенной строке и столбце файла. В этом случае нам придется указать ему, какие строки игнорировать с помощью параметра skiprows и какие столбцы читать с помощью параметра usecols.
Также возможно, что таблица, которую нам нужно загрузить, находится не на первом листе документа. Мы можем использовать параметр sheet_name для указания листа, на котором он должен искать данные. Мы можем указать номер листа, учитывая, что первый из них – 0, или название листа.
Например, если таблица данных начинается со строки 3 и столбца B листа с названием Employees в файле data.xlsx, мы можем загрузить данные следующим образом: df = pd.read_excel(‘data.xlsx’, sheet_name=’Employees’, usecols=’B:D’, skiprows=2).
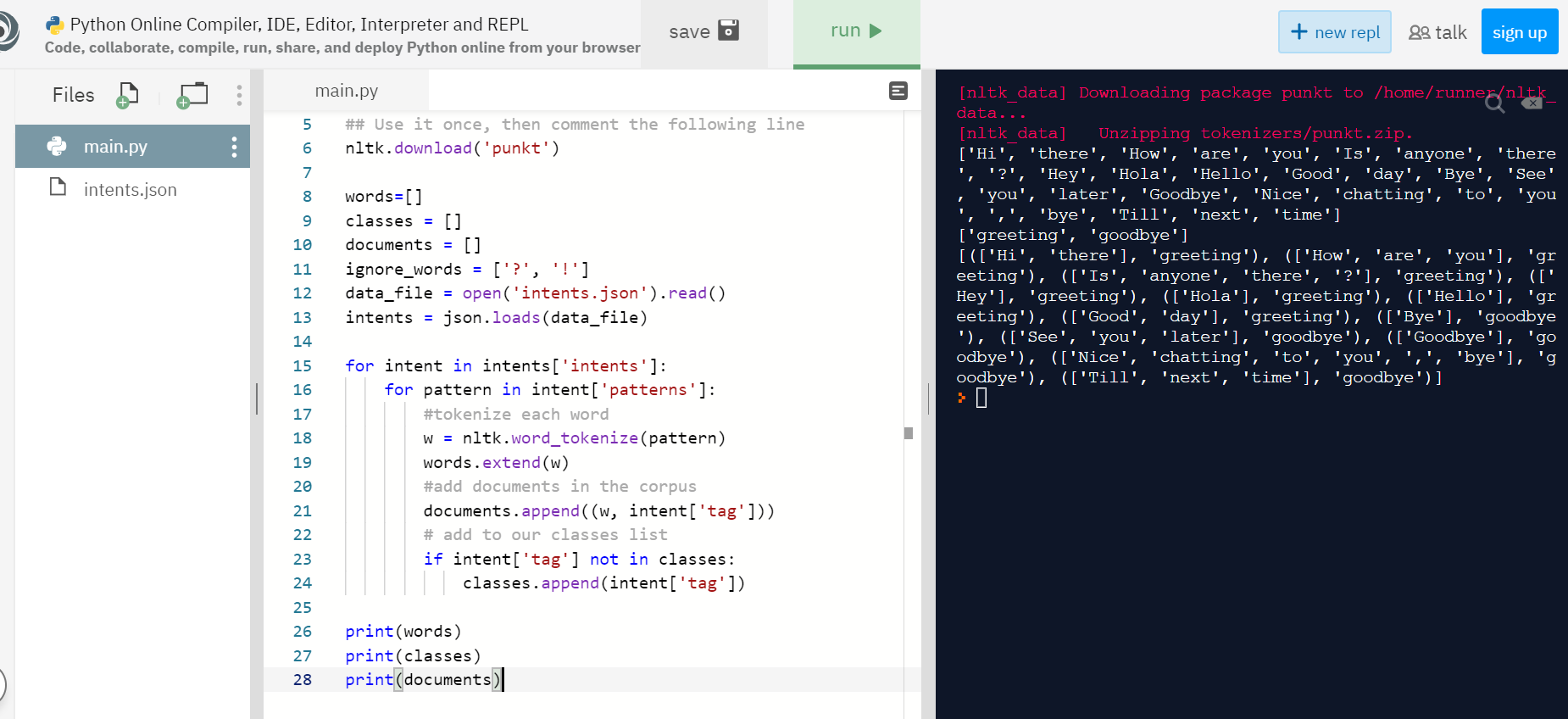
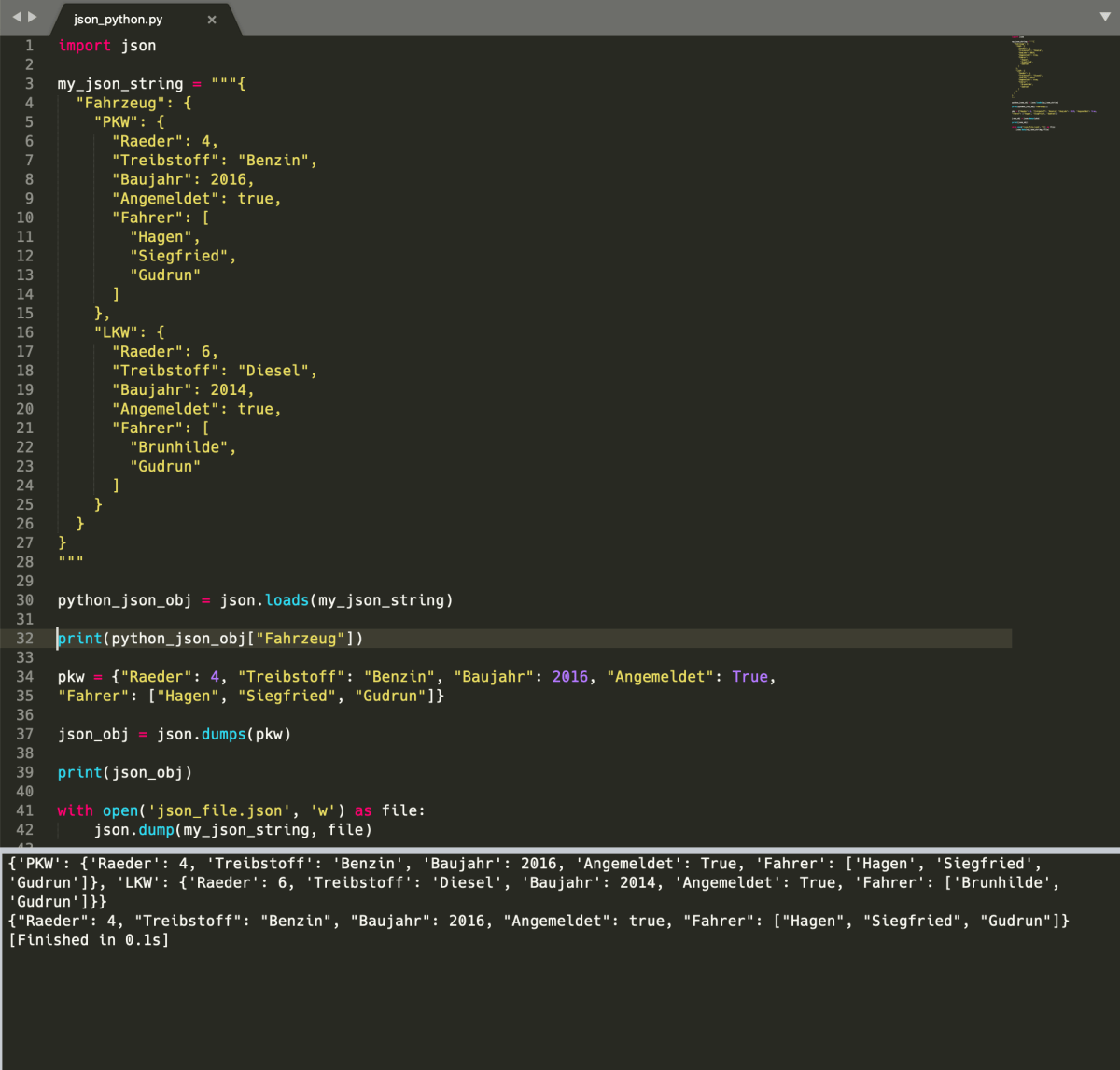
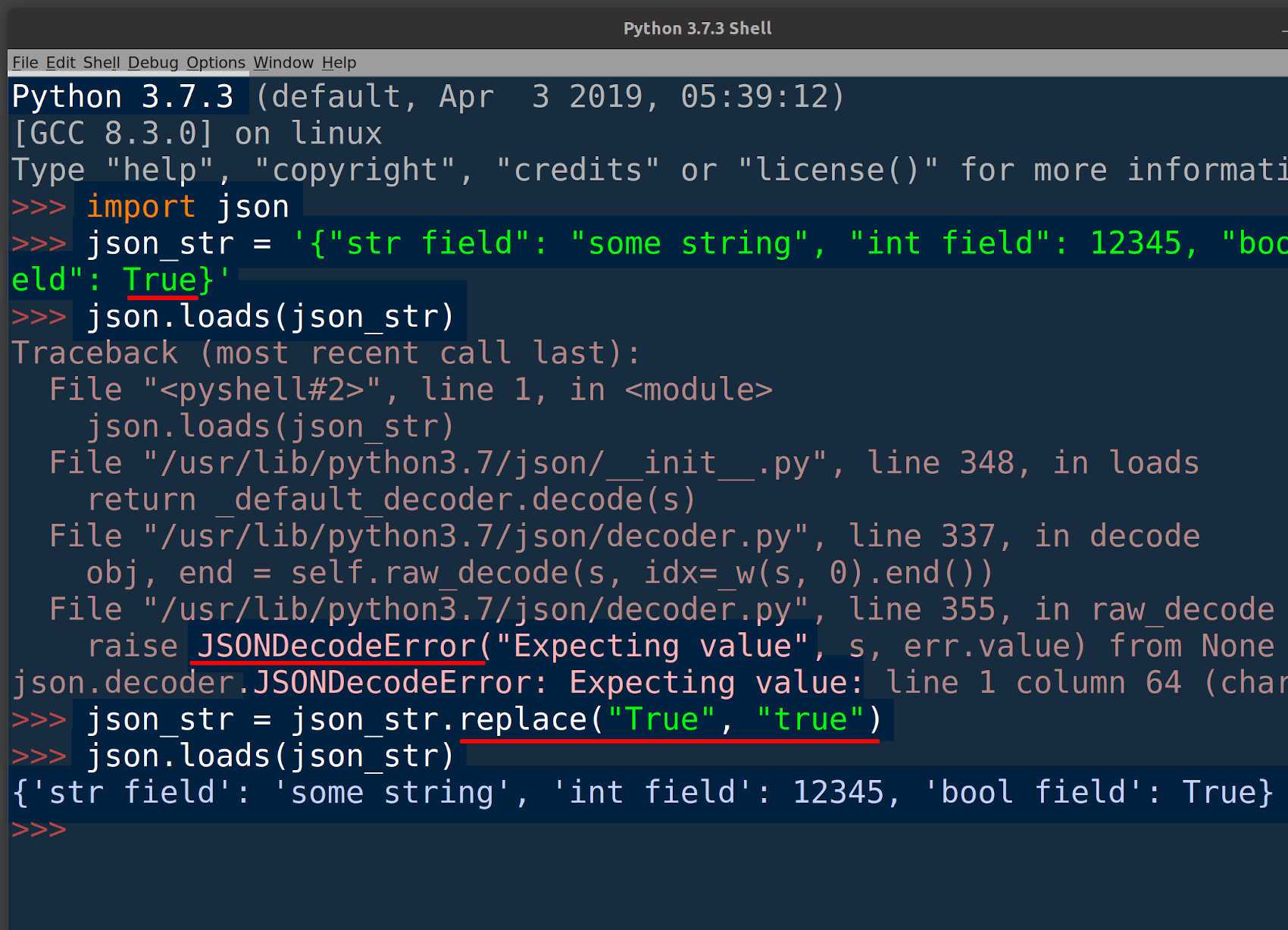
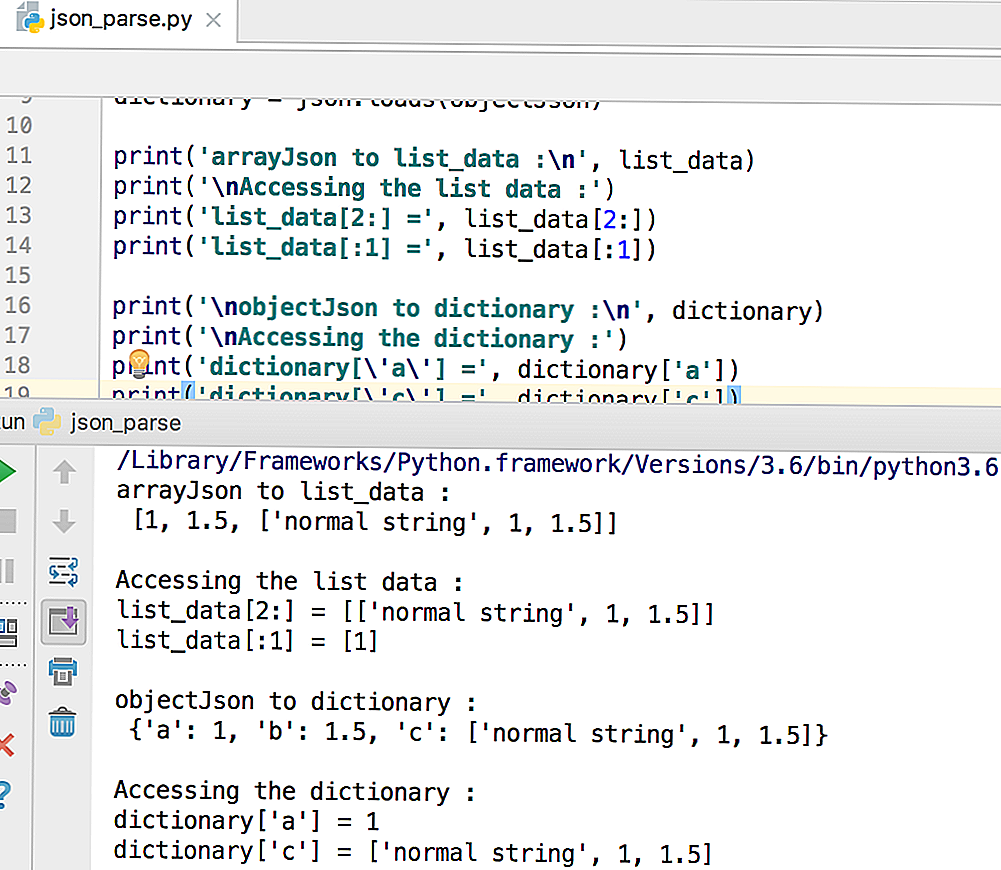
Разбираем JSON-данные в Python
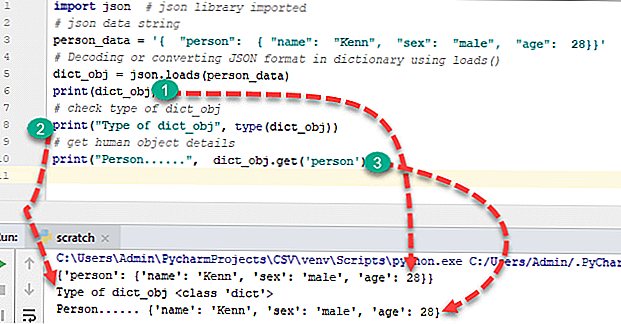
Если мы хотим выполнить обратную операцию и быстро раскодировать формат JSON средствами языка Python, нам поможет метод loads. Он позволяет без труда преобразовать JSON в объект, и с этим объектом мы сможем легко взаимодействовать в программе.
import json
jsonData = """ {
"ID" : 310450,
"login" : "admin",
"name" : "James Bond",
"password" : "root",
"phone" : 3330303,
"email" : " ",
"online" : true
} """
dictData = json.loads(jsonData)
print(dictData"name"])
print(dictData"phone"])
print(dictData"email"])
print(dictData"online"])
James Bond
3330303
bond@mail.com
True
Мы видим, что произошло обратное, а литерал true автоматически преобразовался в True. Это произошло, чтобы была возможность работать с ним средствами Python.
P.S. Итак, мы выполнили кодирование и декодирование информации в JSON-формате с помощью встроенных средств Python. Благодаря наличию удобных методов из модуля json (dumps и loads), эти операции были осуществлены довольно просто. Остаётся добавить, что функции loads и dumps способны взаимодействовать и с другими видами объектов, включая более сложные (например, со вложенными разновидностями словарей со множеством строковых значений).
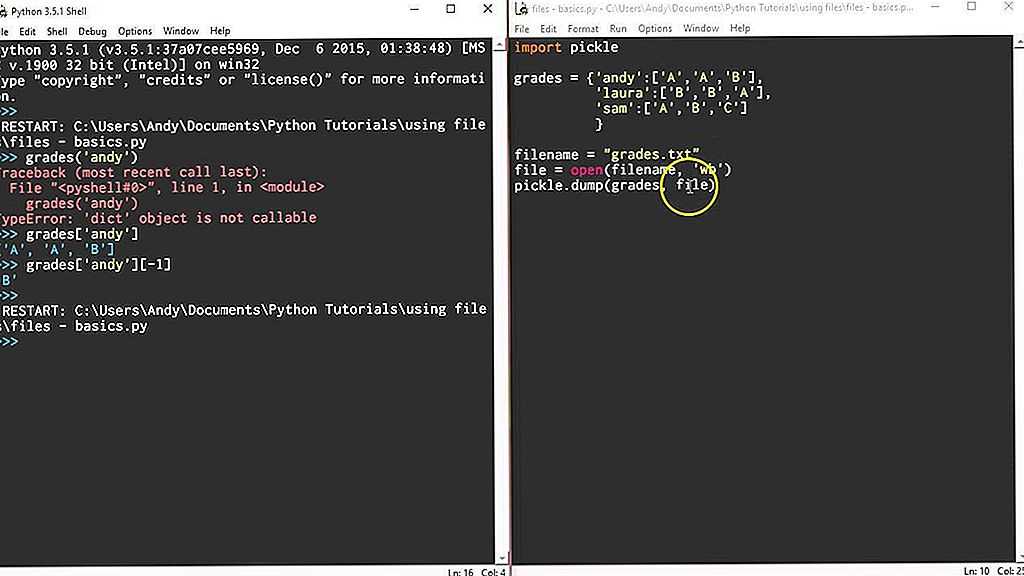
Закрытие файла в Python
После того, как мы открыли файл, и выполнили все нужные операции, нам необходимо его закрыть. Для закрытия файла используется функция close().
file = open("text.txt", "r", encoding = "utf-8" )
file.close()
Вышеописанный код, это всего лишь пример работы с файлами, мы не должны забывать, что в ходе работы нашей программы, может произойти что то непредвиденное. Для таких случаев мы используем блок try…finally, о котором мы говорим чуть позже. Ниже пример, с блоком исключений:
try:
file = open("text.txt", "r", encoding = "utf-8" )
finally:
file.close()
Данная конструкция, гарантирует нам правильное закрытие файла, даже если произойдет ошибка в ходе работы нашей программы.
Лучшим же методом правильного закрытия файла, является конструкция with. Данная конструкция гарантирует нам правильное закрытие файла.
with open("text.txt", "r", encoding = "utf-8" ) as file:
Чтение файлов JSON с помощью Pandas
Чтобы прочитать файл JSON с помощью Pandas, вызовем метод read_json() и передадим ему путь к файлу, который нужно прочитать. Метод возвращает DataFrame, который хранит данные в виде столбцов и строк.

Но сначала нужно установить библиотеку Pandas:
$ pip install pandas
Чтение JSON из локальных файлов
Приведенный ниже скрипт считывает файл patients.json из локальной системной директории и сохраняет результат во фрейме данных patients_df. Затем заголовок фрейма выводится с помощью метода head():
import pandas as pd
patients_df = pd.read_json('E:/datasets/patients.json')
patients_df.head()
Запуск этого кода должен дать следующий результат:
Следующий скрипт считает файл cars.json из локальной системы и затем вызовет метод head()cars_df для вывода заголовка:
cars_df = pd.read_json('E:/datasets/cars.json')
cars_df.head()
Результат запуска этого кода:
Чтение JSON из удаленных файлов
С помощью метода read_json() также можно считывать файлы JSON, расположенные на удаленных серверах. Для этого нужно передать в вызов функции путь удаленного файла JSON.
Давайте прочитаем и выведем заголовок из Iris Dataset:
import pandas as pd
iris_data = pd.read_json("https://raw.githubusercontent.com/domoritz/maps/master/data/iris.json")
iris_data.head()
Результат запуска этого кода:
![]()
Как создать DataFrame из файла JSON
Другой вариант – хранить данные в файле JSON, что очень популярно в настоящее время.
Для создания DataFrame из файла JSON можно использовать функцию pandas read_json, задав ей имя файла следующим образом pandas.read_jason(‘data.json’). Эта функция создает новый DataFrame с данными, содержащимися в предоставленном файле.
Создадим DataFrame с теми же данными, что и в предыдущих примерах, только в этом случае исходный файл будет в формате JSON:
Теперь вам остается только использовать функцию read_json, которая будет считывать данные из файла и создавать DataFrame:
И чтобы не повторяться, результат будет таким же, как и в предыдущих случаях.
Построение задачи
Перед нами стоит задача — сохранить данные из датасета «Ирис» в обычный текстовый документ и в .csv файл (сам датасет предоставит нам sklearn), а также сохранить все параметры модели в json и pickle файлы.
Начало работы
Сегодня в качестве среды разработки я буду использовать IntelJ IDEA со стандартным расширением для Python от JetBrains.
Импортируем все модули:
![]()
Согласно РЕР8, в начале файла мы импортируем только модули стандартной библиотеки. NumPy, Pandas и SkLearn вам придется установить с помощью пакетного менеджера pip/pip3.
Из подмодуля sklearn.datasets мы импортируем сам датасет, функцию разделения тренировочные/тестовые данные, а также сам класс модели логистической регрессии.
Чтение и запись файлов
Python предлагает различные методы для чтения и записи файлов, где каждая функция ведет себя по-разному. Следует отметить один важный момент – режим работы с файлами. Чтобы прочитать файл, вам нужно открыть файл в режиме чтения или записи. В то время, как для записи в файл на Python вам нужно, чтобы файл был открыт в режиме записи.
Вот некоторые функции Python, которые позволяют читать и записывать файлы:
- read() – эта функция читает весь файл и возвращает строку;
- readline() – эта функция считывает строки из этого файла и возвращает их в виде строки. Он выбирает строку n, если она вызывается n-й раз.
- readlines() – эта функция возвращает список, в котором каждый элемент представляет собой одну строку этого файла.
- readlines() – эта функция возвращает список, в котором каждый элемент представляет собой одну строку этого файла.
- write() – эта функция записывает фиксированную последовательность символов в файл.
- Writelines() – эта функция записывает список строк.
- append() – эта функция добавляет строку в файл вместо перезаписи файла.
Возьмем пример файла «abc.txt» и прочитаем отдельные строки из файла с помощью цикла for:
#open the file
text_file = open('/Users/pankaj/abc.txt','r')
#get the list of line
line_list = text_file.readlines();
#for each line from the list, print the line
for line in line_list:
print(line)
text_file.close() #don't forget to close the file
Вывод:
Теперь, когда мы знаем, как читать файл в Python, давайте продвинемся вперед и выполним здесь операцию записи с помощью функции Writelines().
#open the file
text_file = open('/Users/pankaj/file.txt','w')
#initialize an empty list
word_list= []
#iterate 4 times
for i in range (1, 5):
print("Please enter data: ")
line = input() #take input
word_list.append(line) #append to the list
text_file.writelines(word_list) #write 4 words to the file
text_file.close() #don’t forget to close the file
Вывод
Краткий обзор запросов HTTP
Запросы HTTP лежат в основе всемирной сети. Каждый раз, когда вы открываете веб-страницу, ваш браузер направляет множество запросов на сервер этой веб-страницы. Сервер отвечает на них, пересылая все необходимые данные для вывода страницы, и ваш браузер отображает страницу, чтобы вы могли увидеть ее.
В целом этот процесс выглядит так: клиент (например браузер или скрипт Python, использующий библиотеку Requests) отправляет данные на URL, а сервер с этим URL считывает данные, решает, что с ними делать, и отправляет клиенту ответ. После этого клиент может решить, что делать с полученными в ответе данными.
В составе запроса клиент отправляет данные по методу запроса. Наиболее распространенными методами запроса являются GET, POST и PUT. Запросы GET обычно предназначены только для чтения данных без их изменения, а запросы POST и PUT обычно предназначаются для изменения данных на сервере. Например, Stripe API позволяет использовать запросы POST для тарификации, чтобы пользователь мог купить что-нибудь в вашем приложении.
Примечание. В этой статье рассказывается о запросах GET, поскольку мы не собираемся изменять никакие данные на сервере.
При отправке запроса из скрипта Python или веб-приложения вы как разработчик решаете, что отправлять в каждом запросе и что делать с полученными ответами. Для начала отправим запрос на Scotch.io и используем API для перевода.
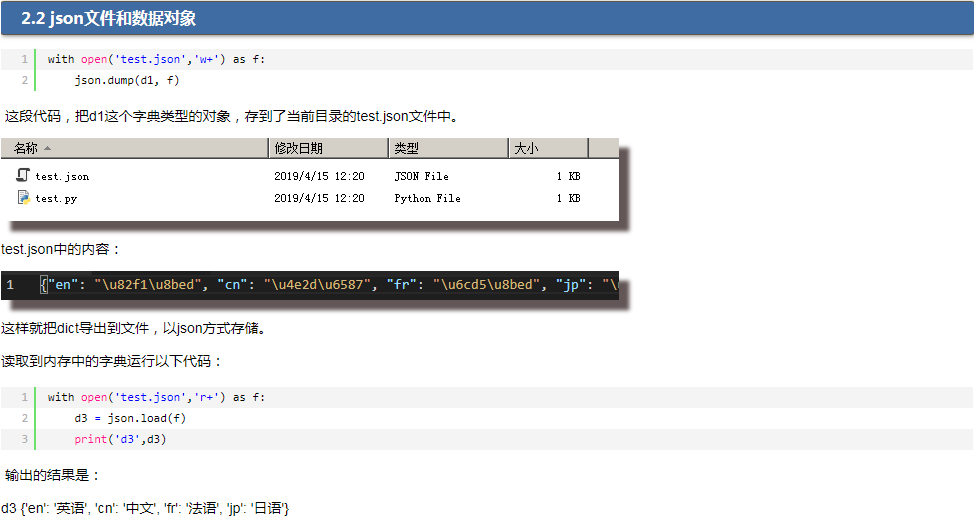
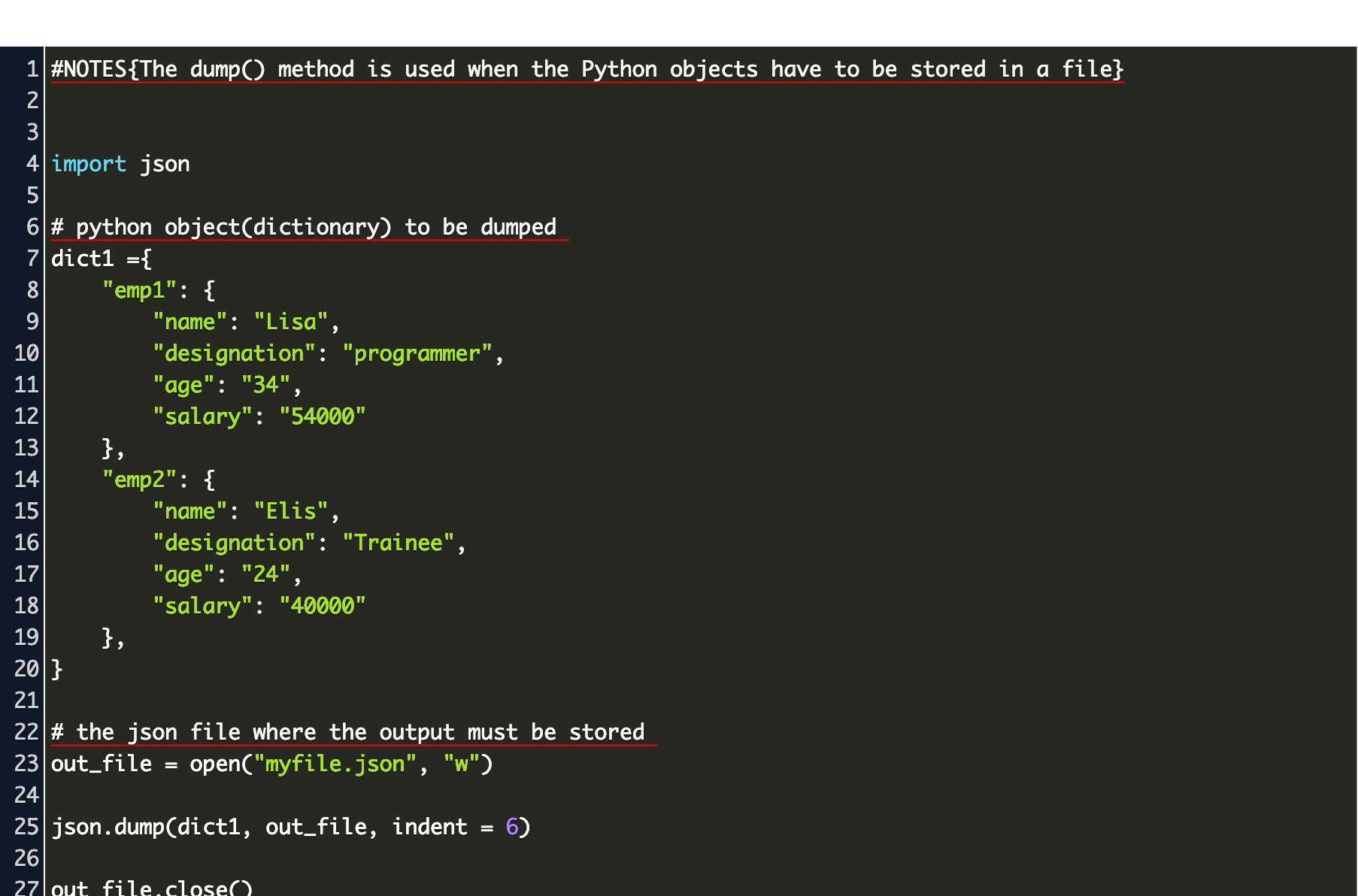
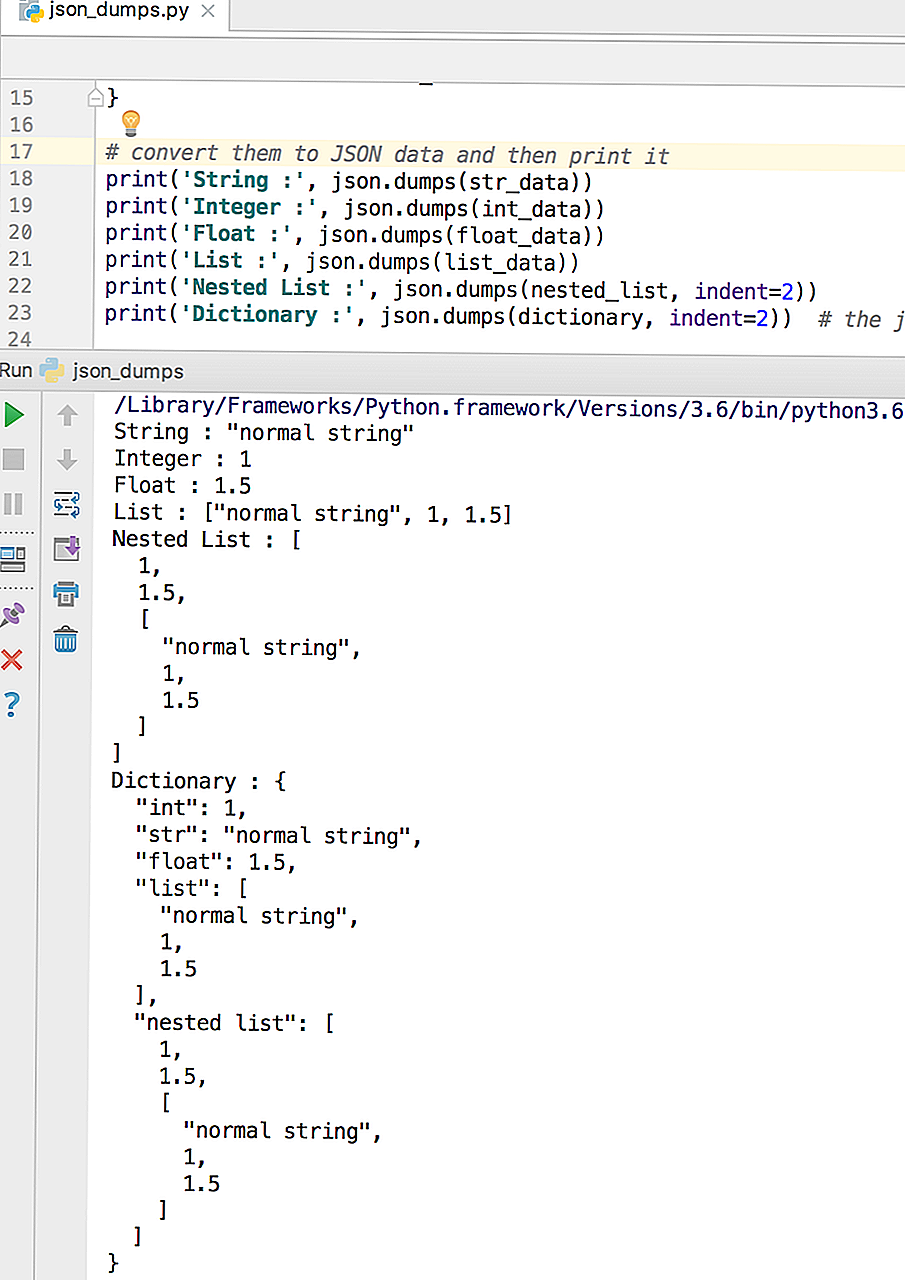
Сохраняем данные в JSON в Python
Если мы хотим записать информацию в JSON-формате, используя средства языка программирования Python, для начала надо подключить соответствующий json-модуль. Для этого нам пригодиться команда import json в самом начале кода.
Также стоит упомянуть метод dumps — он отвечает за автоматическую упаковку информации в JSON и принимает переменную, содержащую все необходимые данные.
import json
dictData = { "ID" 310450,
"login" "admin",
"name" "James Bond",
"password" "root",
"phone" 3330303,
"email" " ",
"online" True }
jsonData = json.dumps(dictData)
print(jsonData)
{"ID" 310450, "login" "admin", "name" "James Bond", "password" "root", "phone" 3330303, "email" " ", "online" true}
Выполнив метод dumps, мы получим результат, который передастся в переменную с названием jsonData. То есть мы видим, что словарь dictData преобразовался в формат JSON всего лишь одной строчкой. А за счёт функции print вся информация была закодирована в изначальном виде. Также следует добавить, что сведения из поля online преобразовались из литерала True в true.
Теперь, используя Python, выполним запись json в файл. Чтобы это сделать, дополним предыдущий код:
with open("data.json", "w") as file
file.write(jsonData)
Статистический анализ в Pandas
Модуль Python Pandas предлагает большое количество встроенных методов, помогающих пользователям проводить статистический анализ данных.
Ниже приводится список некоторых наиболее часто используемых функций для статистического анализа:
| Метод | Description |
|---|---|
| count() | Подсчитывает количество всех непустых наблюдений |
| sum() | Возвращает сумму элементов данных. |
| mean() | Возвращает среднее значение всех элементов данных. |
| median() | Возвращает медианное значение всех элементов данных. |
| mode() | Возвращает режим всех элементов данных |
| std() | Возвращает стандартное отклонение всех элементов данных. |
| min() | Возвращает минимальный элемент данных среди всех входных элементов. |
| max() | Возвращает максимальный элемент данных среди всех входных элементов. |
| abs() | Возвращает абсолютное значение. |
| prod() | Возвращает произведение значений данных. |
| cumsum() | Возвращает кумулятивную сумму значений данных. |
| cumprod() | Возвращает совокупное произведение значений данных. |
| describe() | Он отображает статистическую сводку всех записей за один снимок, т.е. (сумма, количество, мин, среднее и т. Д.) |
Для начала давайте создадим DataFrame, который мы будем использовать в этом разделе для понимания различных функций, предоставляемых для статистического анализа.
import pandas
import numpy
input = {'Name':pandas.Series(),
'Marks':pandas.Series(),
'Roll_num':pandas.Series()
}
#Creating a DataFrame
data_frame = pandas.DataFrame(input)
print(data_frame)
Выход:
Name Marks Roll_num 0 John 44 1 1 Bran 48 2 2 Caret 75 3 3 Joha 33 4 4 Sam 99 5
Итоговая таблица
Мы рассмотрели несколько способов создания DataFrame с помощью pandas и Python. Если вы прочитали всю статью, то увидели, что все способы очень похожи, хотя каждый из них имеет свои особенности. Идея здесь в том, что пандас хочет сделать нашу жизнь проще, как вы видите.
В качестве резюме я привожу здесь таблицу со всеми рассмотренными нами способами и функциями для создания DataFrame.
| Источник данных | Пример |
| Данные отсутствуют | |
| Список списков,список словарей | df = pd.DataFrame(list) |
| Словарь списков | df = pd.DataFrame(dictionary) |
| Массив NumPy | df = pd.DataFrame(array) |
| Формат CSV | |
| Файл с полямиполя фиксированной ширины | df = pd.read_fwf(‘data.fwf’) |
| Данные в буфере обмена | df = pd.read_clipboard() |
| Веб-файлы или файлы HTML | |
| Электронная таблица | df = pd.read_excel(‘data.xlsx’) |
| JSON-файл | df = pd.read_json(‘data.json’) |
| База данных SQL | |
| Другие форматы | См. таблицу 2 |
Таблица 3: Сводка создания DataFrames из различных форматов исходных данных



