
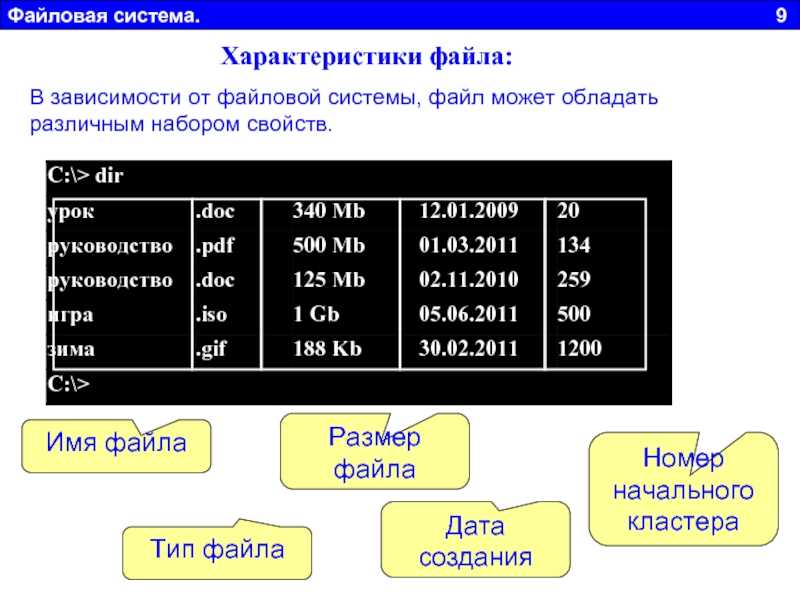
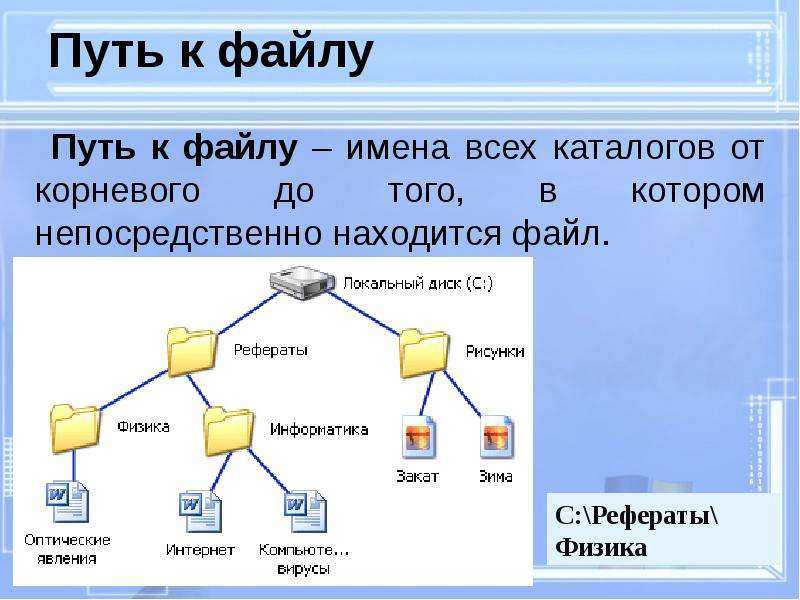
PHP syntax for file_get_contents()
We should use file_get_contents() in PHP scripts, with the syntax as shown in the following code block.
file_get_contents(string $file_name, bool $use_include_path = false, resource $context, int $start = -1, int $limit)
PHP file_get_contents() Parameters
Now, let us have a look into the details on PHP file_get_contents() parameters.
- $file_name – name or path of the file from which the file source is required.
- $use_include_path – This is a flag and will accept boolean values. If it is TRUE, then the value of FILE_USE_INCLUDE_PATH, PHP constant will be used while searching the file. In recent versions of PHP 5, we should specify FILE_USE_INCLUDE_PATH instead of boolean TRUE.
- $context – If we want to send some resource data to get file contents, we can use this parameter.
- $start – This parameter is used to set the starting offset of a file to read its content from some point in the middle of the file source.
- $limit – This offset is used to set end limit while getting file source.
Note:
- The $start and $limit offsets are used to get some portion of file content, instead of getting entire file source.
- The default value of start is the actual starting point of the file content and the limit will take the length of file source by default.
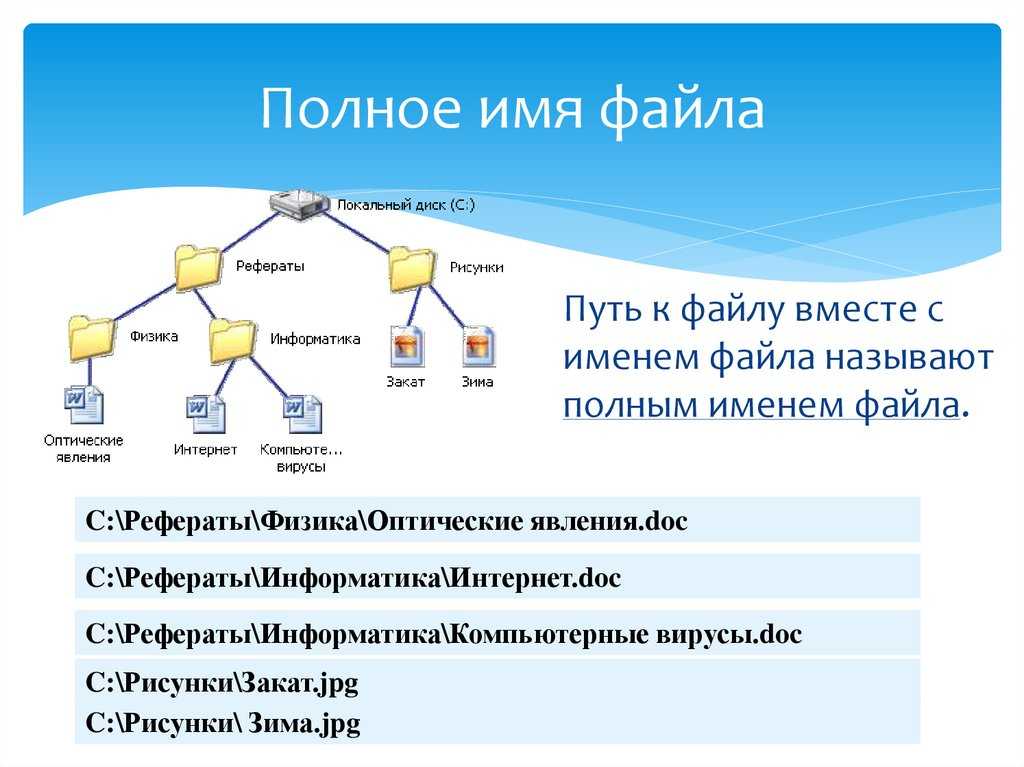
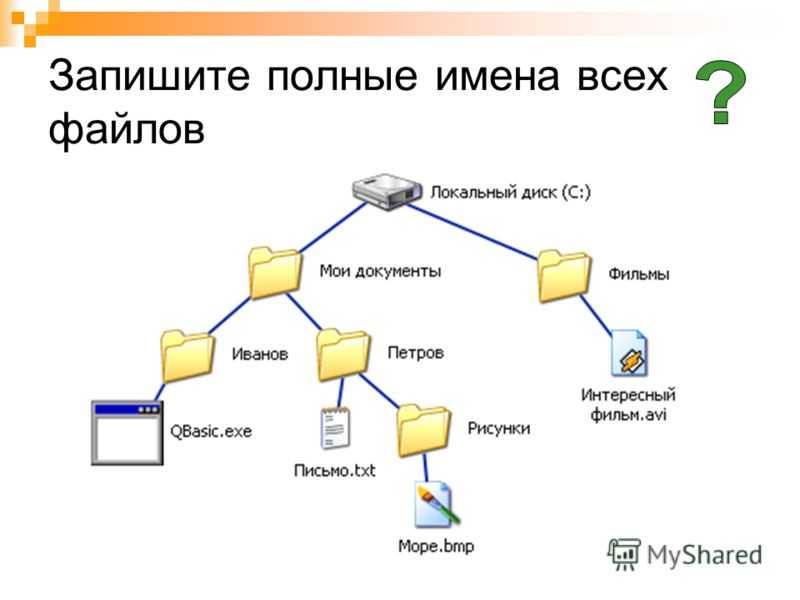
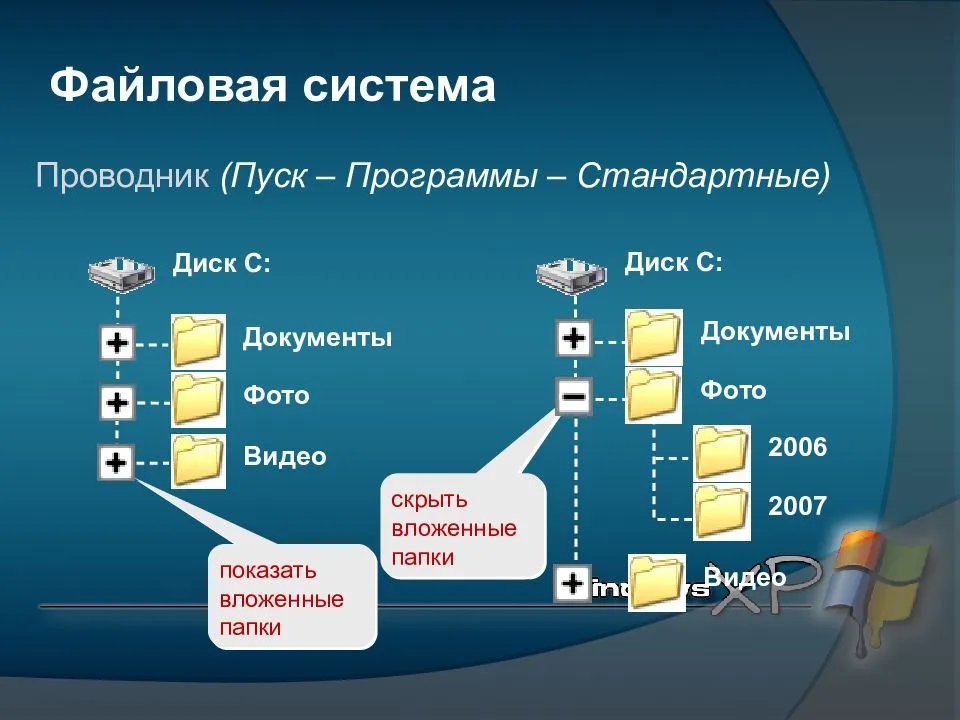
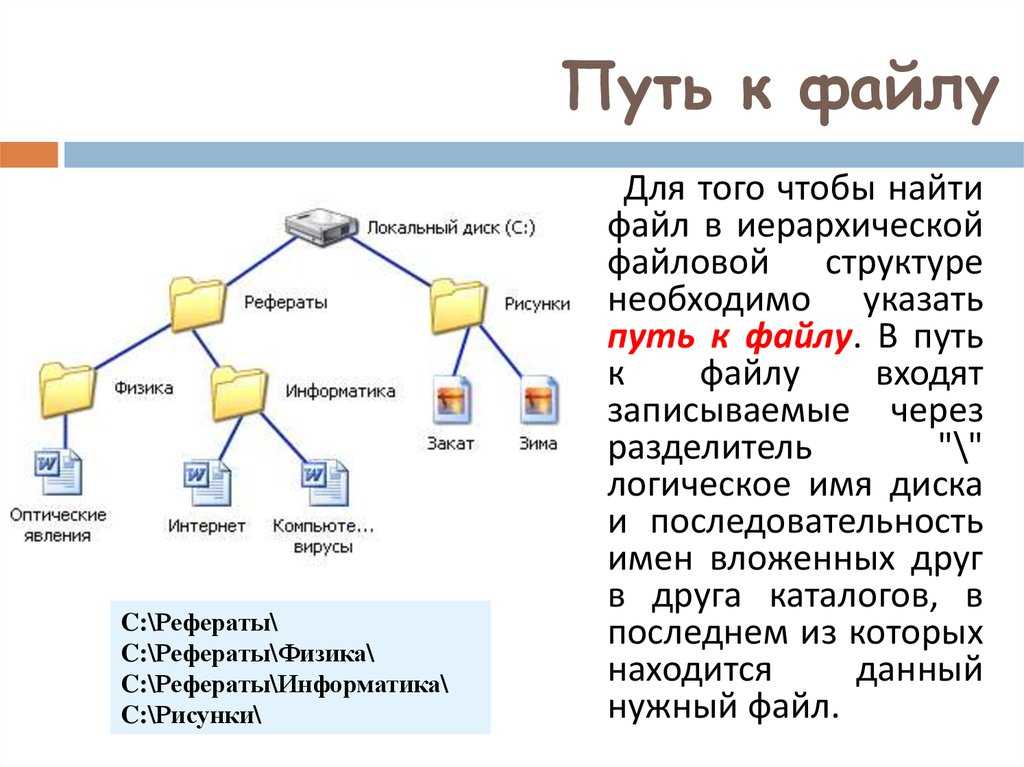
Чтение и запись текстовых файлов. StreamReader и StreamWriter
Последнее обновление: 20.02.2022
Для работы непосредственно с текстовыми файлами в пространстве System.IO определены специальные
классы: StreamReader и StreamWriter.
Запись в файл и StreamWriter
Для записи в текстовый файл используется класс StreamWriter. Некоторые из его конструкторов, которые могут применяться для создания объекта
StreamWriter:
-
: через параметр path передается путь к файлу, который будет связан с потоком
-
: параметр append указывает, надо ли добавлять в конец файла данные или же перезаписывать файл.
Если равно true, то новые данные добавляются в конец файла. Если равно false, то файл перезаписываетсяя заново -
: параметр encoding указывает на кодировку, которая будет
применяться при записи
Свою функциональность StreamWriter реализует через следующие методы:
: закрывает записываемый файл и освобождает все ресурсы
: записывает в файл оставшиеся в буфере данные и очищает буфер.
: асинхронная версия метода Flush
: записывает в файл данные простейших типов, как int, double, char, string и т.д. Соответственно имеет ряд перегруженных
версий для записи данных элементарных типов, например, , , и т.д.
: асинхронная версия метода Write
Обратите внимание, что асинхронные версии есть не для всех перегрузок метода Write.
: также записывает данные, только после записи добавляет в файл символ окончания строки
: асинхронная версия метода WriteLine
Рассмотрим запись в файл на примере:
string path = "note1.txt";
string text = "Hello World\nHello METANIT.COM";
// полная перезапись файла
using (StreamWriter writer = new StreamWriter(path, false))
{
await writer.WriteLineAsync(text);
}
// добавление в файл
using (StreamWriter writer = new StreamWriter(path, true))
{
await writer.WriteLineAsync("Addition");
await writer.WriteAsync("4,5");
}
В данном случае два раза создаем объект StreamWriter. В первом случае если файл существует, то он будет перезаписан. Если не существует, он будет создан.
И в нее будет записан текст из переменной text. Во втором случае файл открывается для дозаписи, и будут записаны атомарные данные — строка и число.
По завершении в папке программы мы сможем найти файл note.txt, который будет иметь следующие строки:
Hello World Hello METANIT.COM Addition 4,5
В пример выше будет использоваться кодировка по умолчанию. но также можно задать ее явным образом:
using (StreamWriter writer = new StreamWriter(path, true, System.Text.Encoding.Default))
{
// операции с writer
}
Чтение из файла и StreamReader
Класс StreamReader позволяет нам легко считывать весь текст или отдельные строки из текстового файла.
Некоторые из конструкторов класса StreamReader:
-
: через параметр path передается путь к считываемому файлу
-
: параметр encoding задает кодировку для чтения файла
Среди методов StreamReader можно выделить следующие:
-
: закрывает считываемый файл и освобождает все ресурсы
-
: возвращает следующий доступный символ, если символов больше нет, то возвращает -1
-
: считывает и возвращает следующий символ в численном представлении. Имеет перегруженную версию:
, где — массив, куда считываются символы, — индекс в массиве array,
начиная с которого записываются считываемые символы, и count — максимальное количество считываемых символов -
: асинхронная версия метода Read
-
: считывает одну строку в файле
-
: асинхронная версия метода ReadLine
-
: считывает весь текст из файла
-
: асинхронная версия метода ReadToEnd
Сначала считаем текст полностью из ранее записанного файла:
string path = "note1.txt";
// асинхронное чтение
using (StreamReader reader = new StreamReader(path))
{
string text = await reader.ReadToEndAsync();
Console.WriteLine(text);
}
Считаем текст из файла построчно:
string path = "/Users/eugene/Documents/app/note1.txt";
// асинхронное чтение
using (StreamReader reader = new StreamReader(path))
{
string? line;
while ((line = await reader.ReadLineAsync()) != null)
{
Console.WriteLine(line);
}
}
В данном случае считываем построчно через цикл while: — сначала присваиваем переменной line результат функции
, а затем проверяем, не равна ли она null. Когда объект sr дойдет до конца файла и больше строк не останется, то
метод будет возвращать null.
НазадВперед
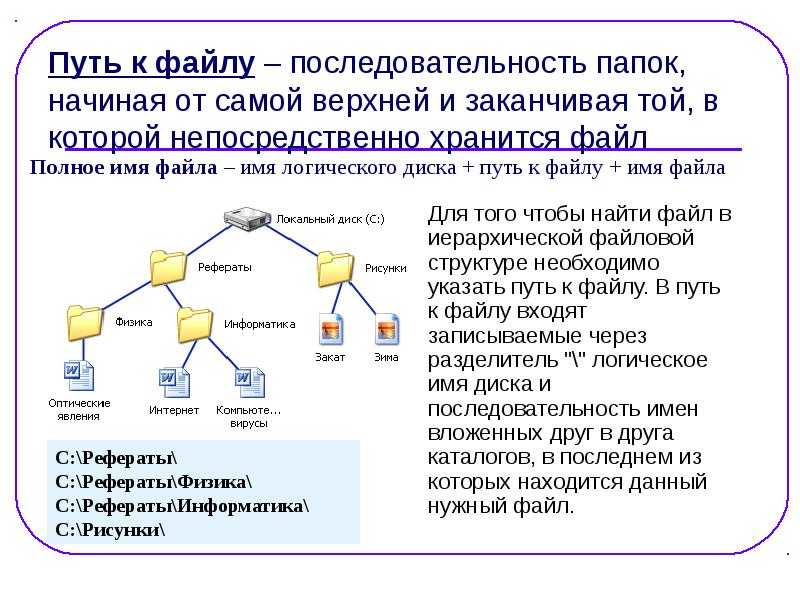
Суть работы
![]() Отображение файла в память
Отображение файла в память
Это механизм, который позволяет отображать файлы на участок памяти. Таким образом, при чтении данных из неё, производится считывание соответствующих байт из файла. С записью аналогично.
Пояснение на примере.
Допустим, перед нами стоит задача обработки большого файла(несколько десятков или даже сотен мегабайт). Казалось бы, задача тривиальна — открываем файл, поблочно копируем из него в память, обрабатываем. Что при этом происходит. Каждый блок копируется во временный кэш, затем из него в нашу память. И так с каждым блоком. Налицо неоптимальное расходование памяти под кэш + куча операций копирования. Что же делать?
Тут-то нам на помощь и приходит механизм MMF. Когда мы обращаемся к памяти, в которую отображен файл, данные загружаются с диска в кэш(если их там ещё нет), затем делается отображение кэша в адресное пространство нашей программы. Если эти данные удаляются — отображение отменяется. Таким образом, мы избавляемся от операции копирования из кэша в буфер. Кроме того, нам не нужно париться по поводу оптимизации работы с диском — всю грязную работу берёт на себя ядро ОС.
В своё время я проводил эксперимент. Замерял с помощью quantify скорость работы программы, которая буферизировано копирует большой файл размером 500 мб в другой файл. И скорость работы программы, которая делает то же, но с помощью MMF. Так вот вторая работает быстрее почти на 30% (в Solaris, в других ОС результат может отличаться). Согласитесь, неплохо.
Чтобы воспользоваться этой возможностью, мы должны сообщить ядру о нашем желании отобразить файл в память. Делается это с помощью функции mmap().
#include<sys/mman.h> void *mmap(void *addr, size_t len, int prot, int flag, int filedes, off_t off);
Она возвращает адрес начала участка отображаемой памяти или MAP_FAILED в случае неудачи.
Первый аргумент — желаемый адрес начала участка отображенной памяти. Не знаю, когда это может пригодится. Передаём 0 — тогда ядро само выберет этот адрес.len — количество байт, которое нужно отобразить в память.prot — число, определяющее степень защищённости отображенного участка памяти(только чтение, только запись, исполнение, область недоступна). Обычные значения — PROT_READ, PROT_WRITE (можно комбинировать через ИЛИ). Защищённость памяти не установится ниже, чем права, с которыми открыт файл.flag — описывает атрибуты области. Обычное значение — MAP_SHARED. Использование MAP_FIXED понижает переносимость приложения, т. к. его поддержка является необязательной в POSIX-системах.filedes — дескриптор файла, который нужно отобразить.off — смещение отображенного участка от начала файла.
Ниже приведен пример программы, которая копирует файл с использованием MMF.
#include <fcntl.h>
#include <sys/mman.h>
int main(int argc, char *argv[])
{
int fdin, fdout;
void *src, *dst;
struct stat statbuf;
if (argc != 3)
err_quit("Использование: %s <fromfile> <tofile>", argv]);
if ( (fdin = open(argv1], O_RDONLY)) < )
err_sys("невозможно открыть %s для чтения", argv1]);
if ( (fdout = open(argv2], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < )
err_sys("невозможно создать %s для записи", argv2]);
if ( fstat(fdin, &statbuf) < ) /* определить размер входного файла */
err_sys("fstat error");
/* установить размер выходного файла */
if ( lseek(fdout, statbuf.st_size - 1, SEEK_SET) == -1 )
err_sys("ошибка вызова функции lseek");
if ( write(fdout, "", 1) != 1 )
err_sys("ошибка вызова функции write");
if ( (src = mmap(, statbuf.st_size, PROT_READ, MAP_SHARED, fdin, )) == MAP_FAILED )
err_sys("ошибка вызова функции mmap для входного файла");
if ( (dst = mmap(, statbuf.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fdout, )) == MAP_FAILED )
err_sys("ошибка вызова функции mmap для выходного файла");
memcpy(dst, src, statbuf.st_size); /* сделать копию файла */
exit();
}
Проблемы кодировки и спецсимволов
Если чтение сложных файлов не вызывает проблем, то проблемы вызывает работа с простыми файлами. Изначально следует принять за аксиому: конструкция file get content PHP читает правильно. Даже если не использовать те или иные параметры, самый простой вариант ее применения всегда сработает как надо.

Сложности вызывают угловые скобки и кодировка файла. Следует отличать работу внутри алгоритма от отображения результата в окне браузера. На рисунке с примером вордовского файла строка (1) — $cLine = scChangeLTGT($cLine) — вызывает функцию преобразования пары угловых скобок в спецсимволы «<» и «>» иначе просто прочитанный файл не всегда можно отобразить в окне браузера
Как писать эту функцию — не суть важно, но существенно не забывать от том, что прочитанная информация может содержать теги XML и HTML, и это требует особого внимания
![]()
Следующий момент: кодировка файла. Далеко не всегда простой текстовый файл не создает проблем. Если читается текстовая информация, то наличие русских букв может создать определенные трудности (2).
$cLine = iconv(‘UTF-8’, ‘CP1251’, $cLine). В этом контексте использование функции iconv() с правильным направлением преобразования актуально не только в отношении PHP «file get contents http://» для чтения страницы сайта, но и когда читается обыкновенный локальный файл.
Если результат чтения «не виден», первое дело — проверить кодировку символов.
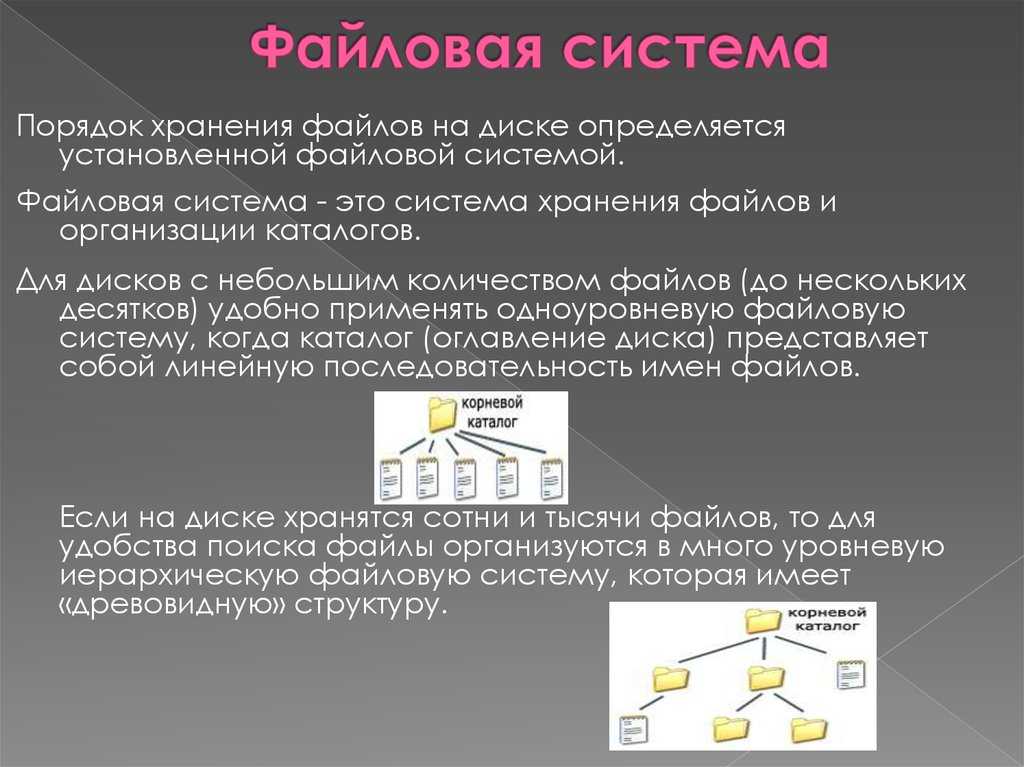
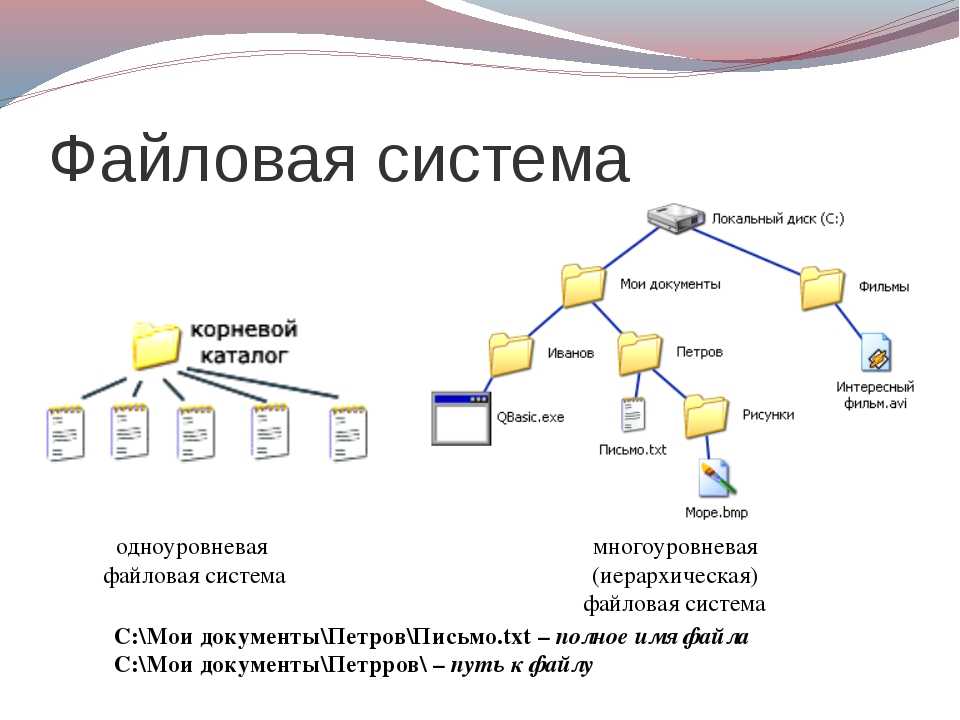
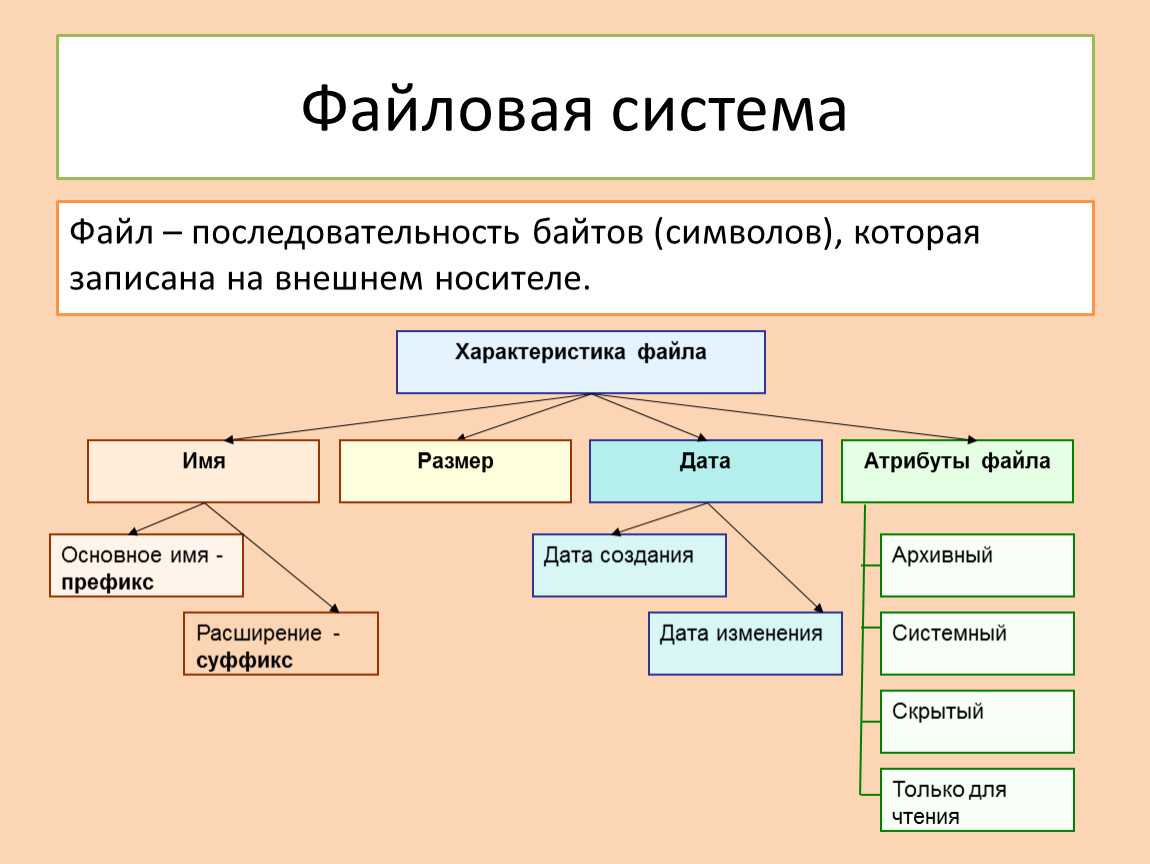
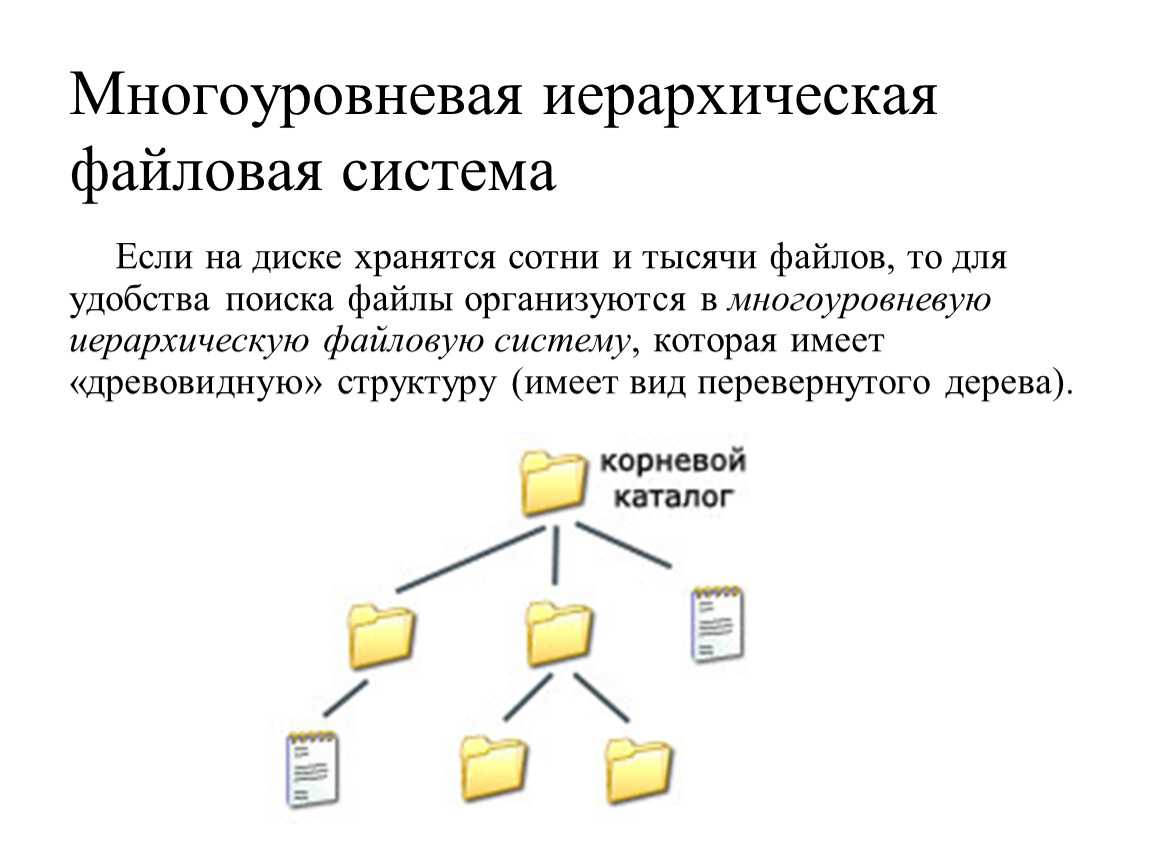
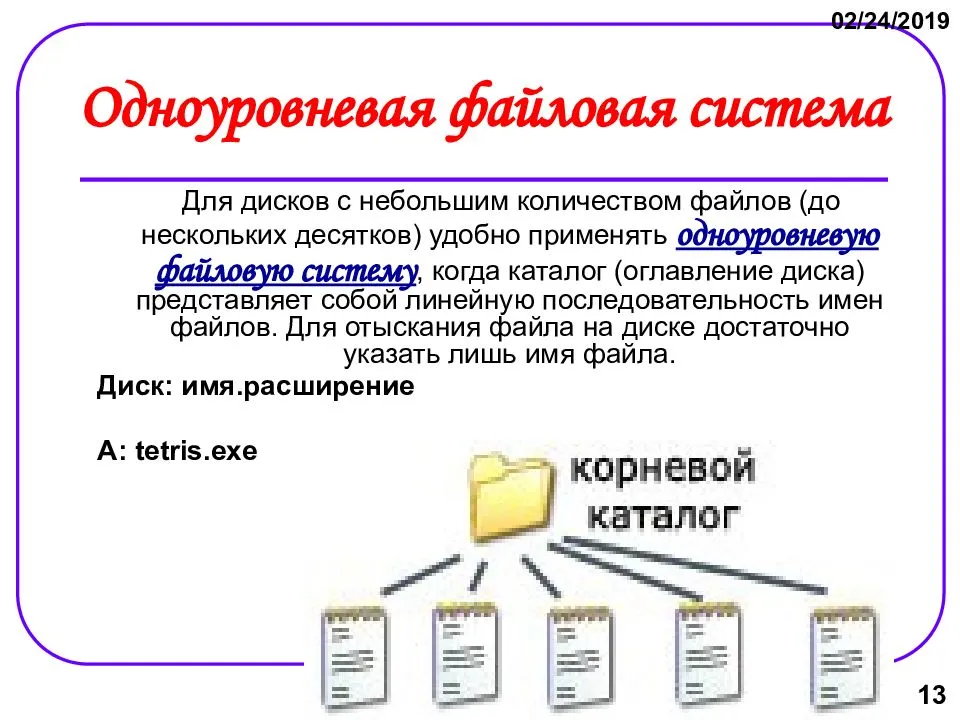
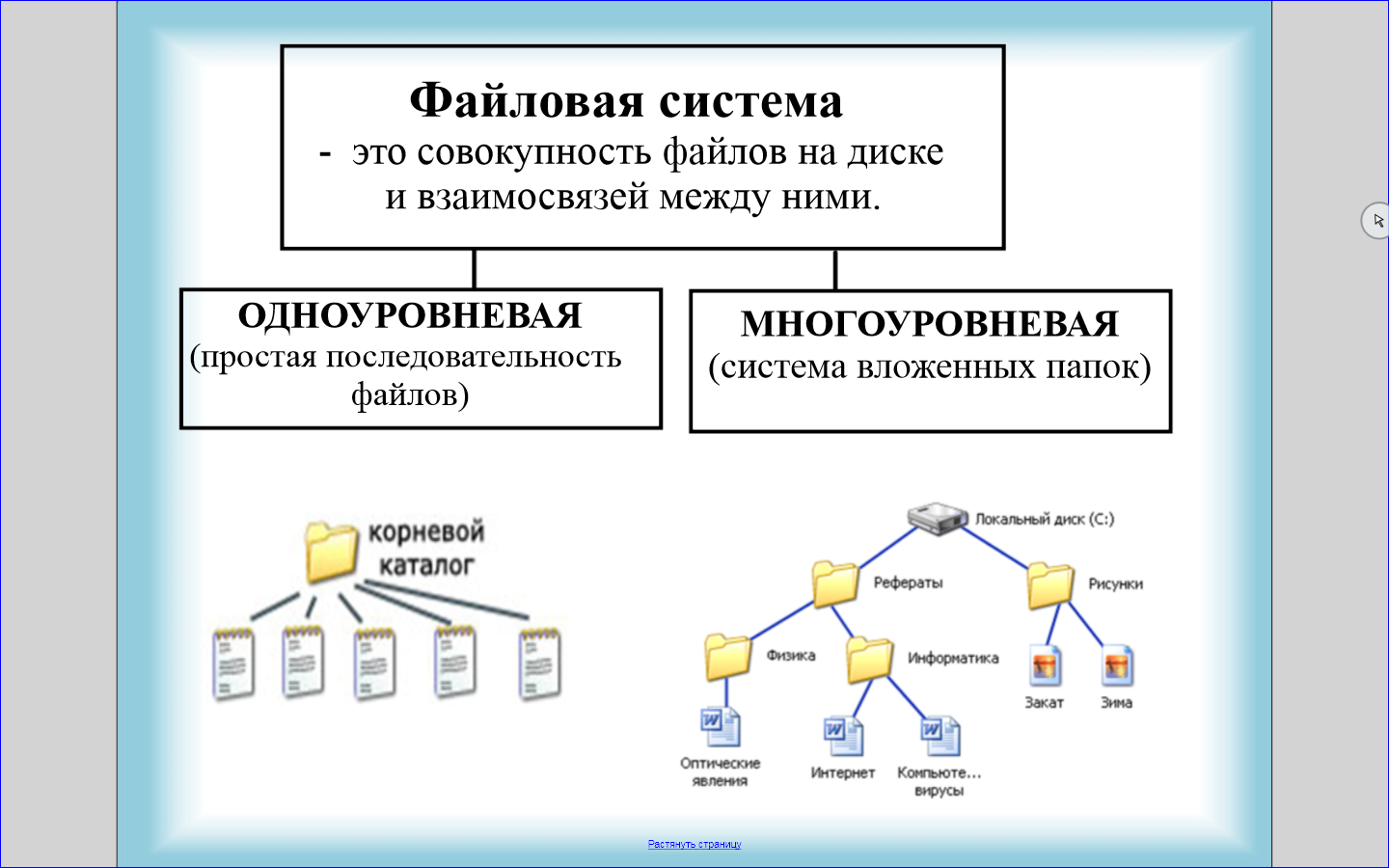
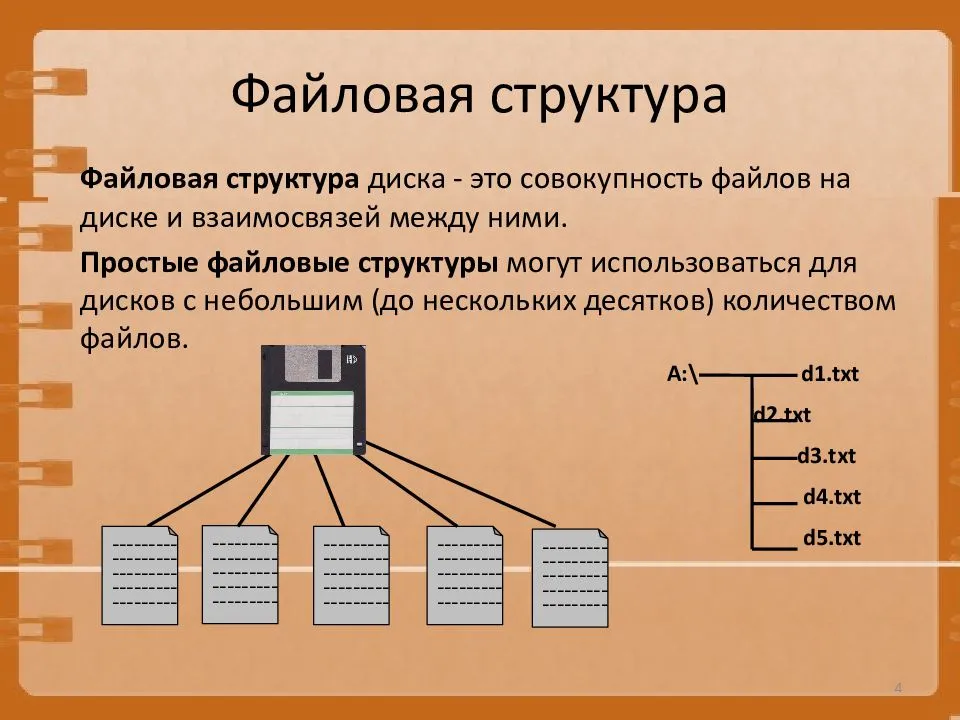
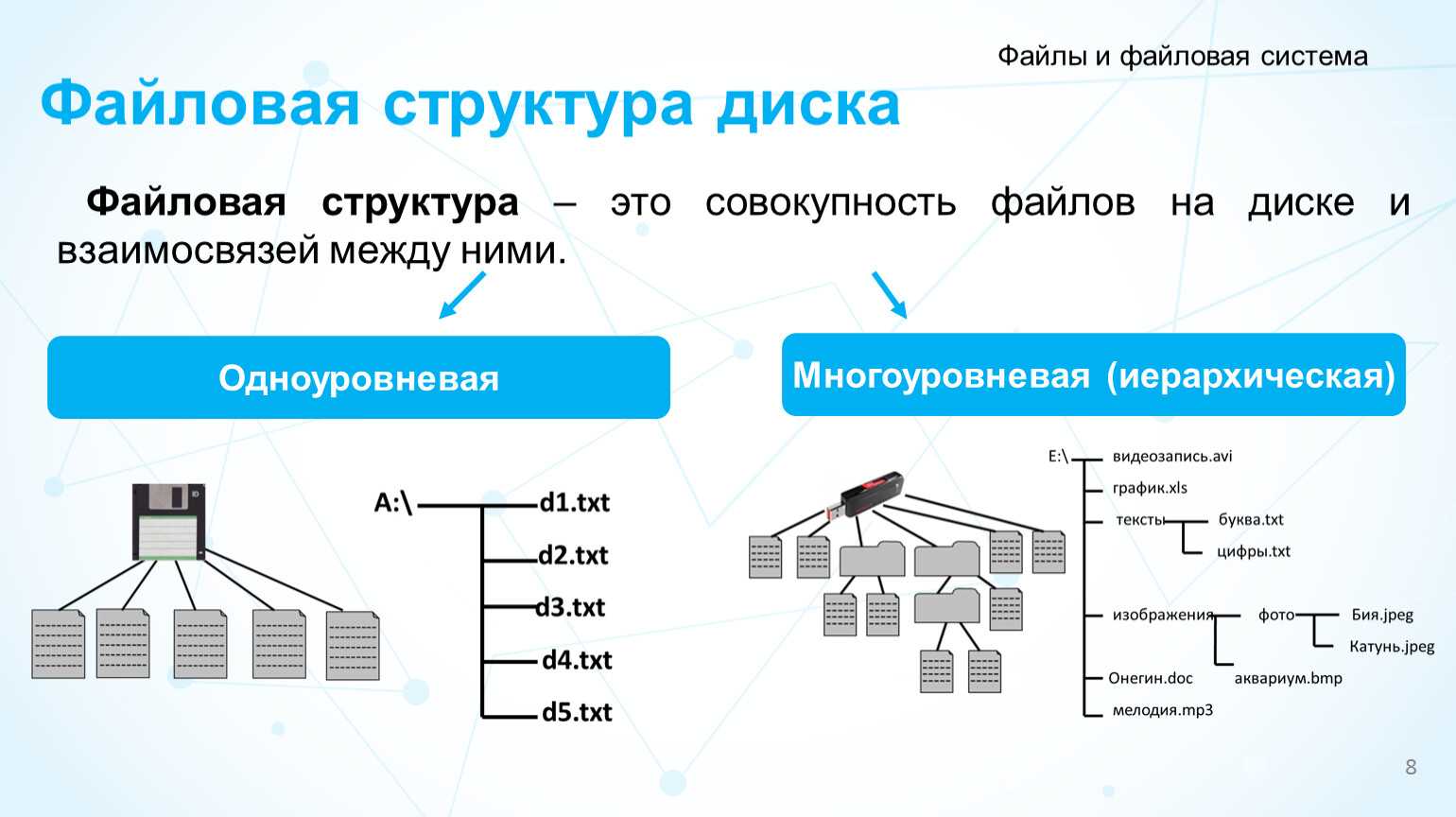
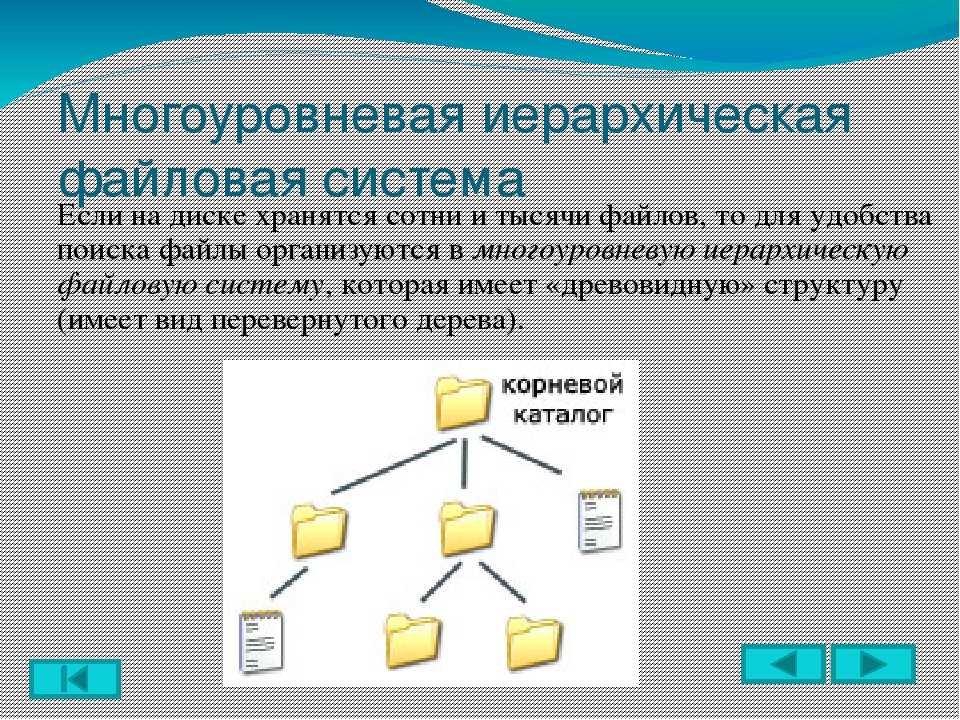
Файловая структура FAT32
Устройства внешней памяти в системе FAT32 имеют не байтовую, а блочную адресацию. Запись информации в устройство внешней памяти осуществляется блоками или секторами. Сектор – минимальная адресуемая единица хранения информации на внешних запоминающих устройствах. Как правило, размер сектора фиксирован и составляет 512 байт. Для увеличения адресного пространства устройств внешней памяти сектора объединяют в группы, называемые кластерами. Кластер – объединение нескольких секторов, которое может рассматриваться как самостоятельная единица, обладающая определёнными свойствами. Основным свойством кластера является его размер, измеряемый в количестве секторов или количестве байт.
Файловая система FAT32 имеет следующую структуру.![]()
Нумерация кластеров, используемых для записи файлов, ведется с 2. Как правило, кластер №2 используется корневым каталогом, а начиная с кластера №3 хранится массив данных. Сектора, используемые для хранения информации, представленной выше корневого каталога, в кластеры не объединяются.
Минимальный размер файла, занимаемый на диске, соответствует 1 кластеру.
Загрузочный сектор начинается следующей информацией:
- EB 58 90 – безусловный переход и сигнатура;
- 4D 53 44 4F 53 35 2E 30 MSDOS5.0;
- 00 02 – количество байт в секторе (обычно 512);
- 1 байт – количество секторов в кластере;
- 2 байта – количество резервных секторов.
Кроме того, загрузочный сектор содержит следующую важную информацию:
- 0x10 (1 байт) – количество таблиц FAT (обычно 2);
- 0x20 (4 байта) – количество секторов на диске;
- 0x2С (4 байта) – номер кластера корневого каталога;
- 0x47 (11 байт) – метка тома;
- 0x1FE (2 байта) – сигнатура загрузочного сектора (55 AA).
Сектор информации файловой системы содержит:
- 0x00 (4 байта) – сигнатура (52 52 61 41);
- 0x1E4 (4 байта) – сигнатура (72 72 41 61);
- 0x1E8 (4 байта) – количество свободных кластеров, -1 если не известно;
- 0x1EС (4 байта) – номер последнего записанного кластера;
- 0x1FE (2 байта) – сигнатура (55 AA).
Таблица FAT содержит информацию о состоянии каждого кластера на диске. Младшие 2 байт таблицы FAT хранят F8 FF FF 0F FF FF FF FF (что соответствует состоянию кластеров 0 и 1, физически отсутствующих). Далее состояние каждого кластера содержит номер кластера, в котором продолжается текущий файл или следующую информацию:
- 00 00 00 00 – кластер свободен;
- FF FF FF 0F – конец текущего файла.
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
- 8 байт – имя файла;
- 3 байта – расширение файла;
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
- 8 байт – имя файла;
- 3 байта – расширение файла;
- 1 байт – атрибут файла:
- 1 байт – зарезервирован;
- 1 байт – время создания (миллисекунды) (число от 0 до 199);
- 2 байта – время создания (с точностью до 2с):
- 2 байта – дата создания:
- 2 байта – дата последнего доступа;
- 2 байта – старшие 2 байта начального кластера;
- 2 байта – время последней модификации;
- 2 байта – дата последней модификации;
- 2 байта – младшие 2 байта начального кластера;
- 4 байта – размер файла (в байтах).
В случае работы с длинными именами файлов (включая русские имена) кодировка имени файла производится в системе кодировки UTF-16. При этого для кодирования каждого символа отводится 2 байта. При этом имя файла записывается в виде следующей структуры:
- 1 байт последовательности;
- 10 байт содержат младшие 5 символов имени файла;
- 1 байт атрибут;
- 1 байт резервный;
- 1 байт – контрольная сумма имени DOS;
- 12 байт содержат младшие 3 символа имени файла;
- 2 байта – номер первого кластера;
- остальные символы длинного имени.
Далее следует запись, включающая имя файла в формате 8.3 в обычном формате.
Традиционные методы fopen
Методы fopen , возможно, лучше других знакомы программистам C и C++ былых времен, поскольку в большей или меньшей степени являются именно теми инструментами, которые на протяжении долгих лет были всегда у вас под рукой, если вы работали с этими языками программирования. Для любого из этих методов вы выполняете стандартную процедуру, используя fopen для открытия файла, функцию для чтения данных, а затем fclose для закрытия файла, как показано в Листинге 1.
Листинг 1. Открытие и чтение файла с помощью fgets
Хотя эти функции знакомы большинству опытных программистов, позвольте мне проанализировать их работу. В действительности вы выполняете следующие шаги:
- Открываете файл. $file_handle хранит ссылку на сам файл.
- Проверяете, не достигли ли вы конца файла.
- Продолжаете считывание файла, пока не достигнете конца, печатая каждую строку, которую читаете.
- Закрываете файл.
Помня об этом, я рассмотрю каждую использованную здесь функцию для работы с файлами.
Функция fopen
Функция fopen устанавливает связь с файлом. Я говорю «устанавливает связь, » поскольку, кроме открытия файла, fopen может открыть и URL:
Это строка программы создает связь с вышеуказанной страницей и позволяет вам начать ее чтение как локального файла.
Примечание: Параметр «r» , использованный в fopen , указывает на то, что файл открыт только для чтения. Поскольку запись в файл не входит в круг вопросов, рассматриваемых в данной статье, я не стану перечислять все возможные значения параметра. Тем не менее, вам необходимо изменить «r» на «rb» если вы производите чтение из двоичных файлов для межплатформенной совместимости. Ниже будет приведен пример данного типа.
Функция feof
Команда feof определяет, произведено ли чтение до конца файла, и возвращает значение True (Истина) или False (Ложь)
Цикл, приведенный в Листинге 1 продолжается, пока не будет достигнут конец файла «myfile.» Обратите внимание, что feof также возвращает False, если вы читаете URL и произошло превышение времени ожидания подключения, поскольку не имеется более данных для считывания
Функция fclose
Пропустим середину Листинга 1 и перейдем в конец; fclose выполняет задачу, противоположную fopen : она закрывает подключение к файлу или URL. После выполнения данной функции вы больше не сможете выполнять чтение из файла или сокета.
Функция fgets
Возвращаясь на несколько строк назад в Листинге 1, вы попадаете в самый центр процесса обработки файлов: непосредственно чтение файла. Функция fgets — это выбранное вами «оружие» для первого примера. Она захватывает строчку данных из файла и возвращает ее как строку. Оттуда вы можете выводить данные или обрабатывать их иным образом. В примере, приведенном в Листинге 1, распечатывается весь файл целиком.
Если вы решите ограничить размер порции данных, с которой работаете, можно добавить fgets аргумент для ограничения максимальной длины строки захватываемых данных. Например, используйте следующий программный код для ограничения длины строки в 80 символов:
Вспомните «
Чтение и запись файлов
Открытие и закрытие файлов
Для открытия файлов в PHP определена функция fopen() . Она имеет следующее определение: resource fopen(string $filename, string $mode) . Первый параметр $filename представляет путь к файлу, а второй — режим открытия. В зависимости от цели открытия и типа файла данный параметр может принимать следующие значения:
‘r’ : файл открывается только для чтения. Если файла не существует, возвращает false
‘r+’ : файл открывается только для чтения с возможностью записи. Если файла не существует, возвращает false
‘w’ : файл открывается для записи. Если такой файл уже существует, то он перезаписывается, если нет — то он создается
‘w+’ : файл открывается для записи с возможностью чтения. Если такой файл уже существует, то он перезаписывается, если нет — то он создается
‘a’ : файл открывается для записи. Если такой файл уже существует, то данные записываются в конец файла, а старые данные остаются. Если файл не существует, то он создается
‘a+’ : файл открывается для чтения и записи. Если файл уже существует, то данные дозаписываются в конец файла. Если файла нет, то он создается
Результатом функции fopen будет дескриптор файла. Этот дескриптор используется для операций с файлом и для его закрытия.
После окончания работы файл надо закрыть с помощью функции fclose() , которая принимает в качестве параметра дескриптор файла. Например, откроем и закроем файл:
Конструкция or die(«текст ошибки») позволяет прекратить работу скрипта и вывесте некоторое сообщение об ошибке, если функция fopen не смогла открыть файл.
Чтение файла
Для чтения файла можно использовать несколько функций. Для построчного чтения используется функция fgets() , которая получает дескриптор файла и возвращает одну считанную строку. Пройдем построчно по всему файлу:


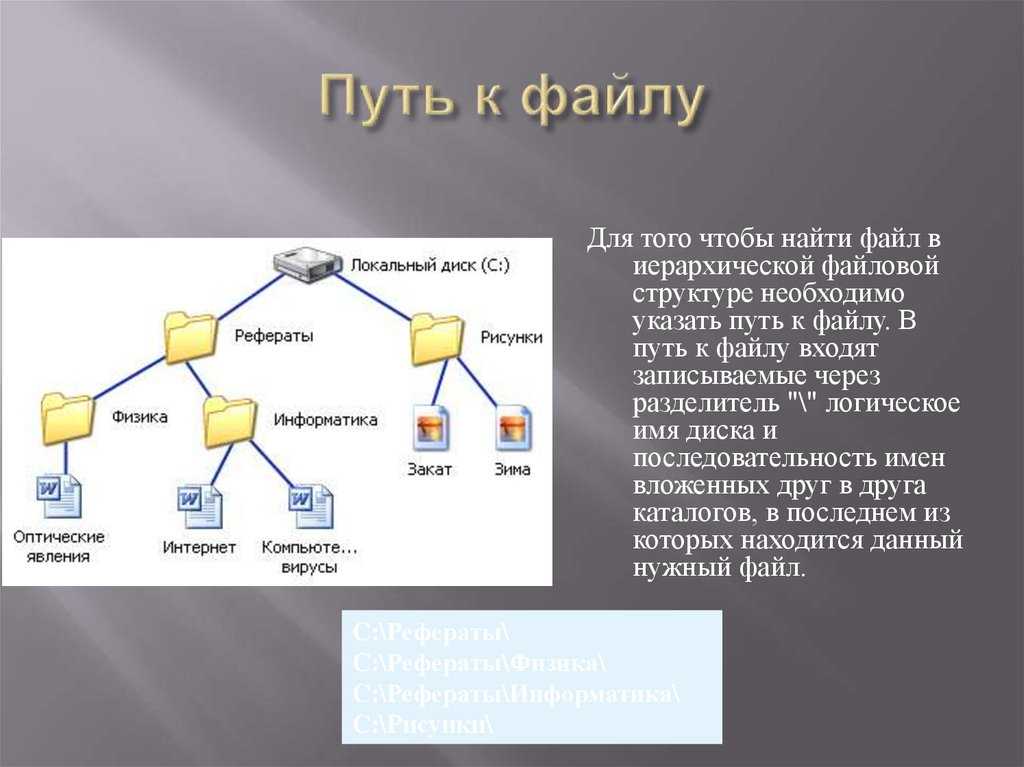
При каждом вызове fgets() PHP будет помещать указатель в конец считанной строки. Чтобы проследить окончание файла, используется функция feof() , которая возвращает true при завершении файла. И пока не будет достигнут конец файла, мы можем применять функцию fgets().
Чтение файла полностью
Если нам надо прочитать файл полностью, то мы можем облегчить себе жизнь, применив функцию file_get_contents() :
При этом нам не надо открывать явно файл, получать дескриптор, а затем закрывать файл.
Поблочное считывание
Также можно провести поблочное считывание, то есть считывать определенное количество байт из файла с помощью функции fread() :
Функция fread() принимает два параметра: дескриптор считываемого файла и количество считываемых байтов. При считывании блока указатель в файле становится в конец этого блока. И также с помощью функции feof() можно отследить завершение файла.
Запись файла
Для записи файла применяется функция fwrite() , которая записывает в файл строку:
Аналогично работает другая функция fputs() :
Работа с указателем файла
При открытии файла для чтения или записи в режиме ‘w’, указатель в файле помещается в начало. При считывании данных PHP перемещает указатель в файле в конец блока считанных данных. Однако мы также вручную можем управлять указателем в файле и устанавливать его в произвольное место. Для этого надо использовать функцию fseek, которая имеет следующее формальное определение:
Параметр $handle представляет дескриптор файла. Параметр $offset — смещение в байтах относительно начала файла, с которого начнется считывание/запись. Третий необязательный параметр задает способ установки смещения. Он может принимать три значения:
SEEK_SET : значение по умолчанию, устанавливает смещение в offset байт относительно начала файла
SEEK_CUR : устанавливает смещение в offset байт относительно начала текущей позиции в файле
SEEK_END : устанавливает смещение в offset байт от конца файла
В случае удачной установки указателя функция fseek() возвращает 0, а при неудачной установке возвращает -1.
На самом деле, чем открыть php файл, не является большой проблемой. Бывает труднее открыть бутылку пива, когда находишься посреди леса. Но так думают лишь заядлые программисты. А для новичков поведаем обо всех возможностях php для работы с файлами:
![]()
Встроенные средства Python
Основа для работы с файлами — built-in функция
Эта функция имеет два аргумента. Аргумент принимает строку, в которой содержится путь к файлу. Второй аргумент, , позволяет указать режим, в котором необходимо работать с файлом. По умолчанию этот аргумент принимает значение rt», с которым, и с некоторыми другими, можно ознакомиться в таблице ниже
Эти режимы могут быть скомбинированы. Например, «rb открывает двоичный файл для чтения. Комбинируя «r+» или «w+» можно добиться открытия файла в режиме и чтения, и записи одновременно с одним отличием — первый режим вызовет исключение, если файла не существует, а работа во втором режиме в таком случае создаст его.
Начать саму работу с файлом можно с помощью объекта класса , который возвращается функцией . У этого объекта есть несколько атрибутов, через которые можно получить информацию
- — название файла;
- — режим, в котором этот файл открыт;
- — возвращает , если файл был закрыт.
По завершении работы с файлом его необходимо закрыть при помощи метода
Однако более pythonic way стиль работы с файлом встроенными средствами заключается в использовании конструкции , которая работает как менеджер создания контекста. Написанный выше пример можно переписать с ее помощью
Главное отличие заключается в том, что python самостоятельно закрывает файл, и разработчику нет необходимости помнить об этом. И бонусом к этому не будут вызваны исключения при открытии файла (например, если файл не существует).
Обработка строк
В библиотеке string.h содержаться функции для различных действий над строками. Функция вычисления длины строки:size_t strlen(const char *string);
Пример:
char str[] = «1234»; int n = strlen(str); //n == 4
Функции копирования строк:
char * strcpy(char * restrict dst, const char * restrict src); char * strncpy(char * restrict dst, const char * restrict src, size_t num);
Функции сравнения строк:
int strcmp(const char *string1, const char *string2); int strncmp(const char *string1, const char *string2,size_t num);
Функции осуществляют сравнение строк по алфавиту и возвращают:
положительное значение – если string1 больше string2; отрицательное значение – если string1 меньше string2; нулевое значение – если string1 совпадает с string2;
Функции объединения (конкатенации) строк:
char * strcat(char * restrict dst, const char * restrict src); char * strncat(char * restrict dst, const char * restrict src, size_t num);
Функции поиска символа в строке:
char * strchr(const char *string, int c); char * strrchr(const char *string, int c);
Функция поиска строки в строке:char * strstr(const char *str, const char *substr);
Пример:
char str[] = «Строка для поиска»; char *str1 = strstr(str,»для»); //str1 == «для поиска»
Функция поиска первого символа в строке из заданного набора символов:size_t strcspn(const char *str, const char *charset);
Функции поиска первого символа в строке не принадлежащему заданному набору символов:size_t strspn(const char *str, const char *charset);
Функции поиска первого символа в строке из заданного набора символов:char * strpbrk(const char *str, const char *charset);
Функция поиска следующего литерала в строке:char * strtok(char * restrict string, const char * restrict charset);
Как вывести на главный экран контакты для быстрого вызова
В встроенном приложении Звонки на смартфонах Realme есть возможность добавления иконки контакта на рабочий стол:
- Включаем системное приложение «Вызовы», заходим во вкладку «Контакты».
- Теперь нужно выбрать 3 избранных контакта. Для этого зажимаем нужный номер и нажимаем на пункт «Добавить в избранное».
- Вверху списка всех контактов будут помечены желтой звездочкой выбранные вами контакты.
- Закрываем приложение, очищаем недавние приложения (оперативную память).
- После на главном экране зажимаем иконку приложения Звонки (трубка) и перед нами появится окно с быстрыми действиями.
- Зажимаем нужный контакт и перетаскиваем его на рабочий стол.
С помощью этой инструкции за один раз можно добавить до 3 избранных контактов. Первые три контакта нужно просто убрать из группы и добавить следующие, и так по кругу.



Что такое метод read() в Python?
Метод будет считывать все содержимое файла как одну строку. Это хороший метод, если в вашем текстовом файле мало содержимого .
В этом примере давайте используем метод для вывода на экран списка имен из файла demo.txt:
file = open("demo.txt")
print(file.read())
Запустим этот код и получим следующий вывод:
# Output: # This is a list of names: # Jessica # James # Nick # Sara
Этот метод может принимать необязательный параметр, называемый размером. Вместо чтения всего файла будет прочитана только его часть.
Если мы изменим предыдущий пример, мы сможем вывести только первое слово, добавив число 4 в качестве аргумента для .
file = open("demo.txt")
print(file.read(4))
# Output:
# This
Если аргумент размера опущен или число отрицательное, то будет прочитан весь файл.
Позиции указателя файла
Python предоставляет метод tell(), который используется для печати номера байта, в котором в настоящее время существует указатель файла. Рассмотрим следующий пример.
# open the file file2.txt in read mode
fileptr = open("file2.txt","r")
#initially the filepointer is at 0
print("The filepointer is at byte :",fileptr.tell())
#reading the content of the file
content = fileptr.read();
#after the read operation file pointer modifies. tell() returns the location of the fileptr.
print("After reading, the filepointer is at:",fileptr.tell())
Выход:
The filepointer is at byte : 0 After reading, the filepointer is at: 117
Как откалибровать датчика приближения
Если например, при звонке экран не гаснет, или наоборот не включается когда телефон убирается от уха – то скорее всего датчик приближения работает не правильно.
Проверяем как он работает через инженерное меню
- Заходим в приложение «Звонки» — вводим код *#899#.
- Выбираем пункт «Manual test».
- Листаем до вкладки «Device debugging» и выбираем пункт «Proximity sensor test».
- Здесь проверяем как работает датчик, закрываем рукой верхнюю часть телефона, и если экран становится зеленым и значения света меняются – датчик приближения на Realme работает нормально.
- Если тест не пройдет – возвращаемся назад и выбираем пункт «Калибровка».
Еще датчик можно проверить через приложение Sensor Box For Android. Выбираем «Proximity Sensor» и опять закрывает верхнюю часть телефона рукой. Значение должно быть равно 5 — это норма.
Также можно попробовать просто перезагрузить телефон, в большинстве случаев это помогает. Еще важный момент, если наклеено защитное стекло (особенно с цветной рамкой) или пленка — то в таком случае это может мешать датчикам и влиять на их работу
Обратите на это внимание



