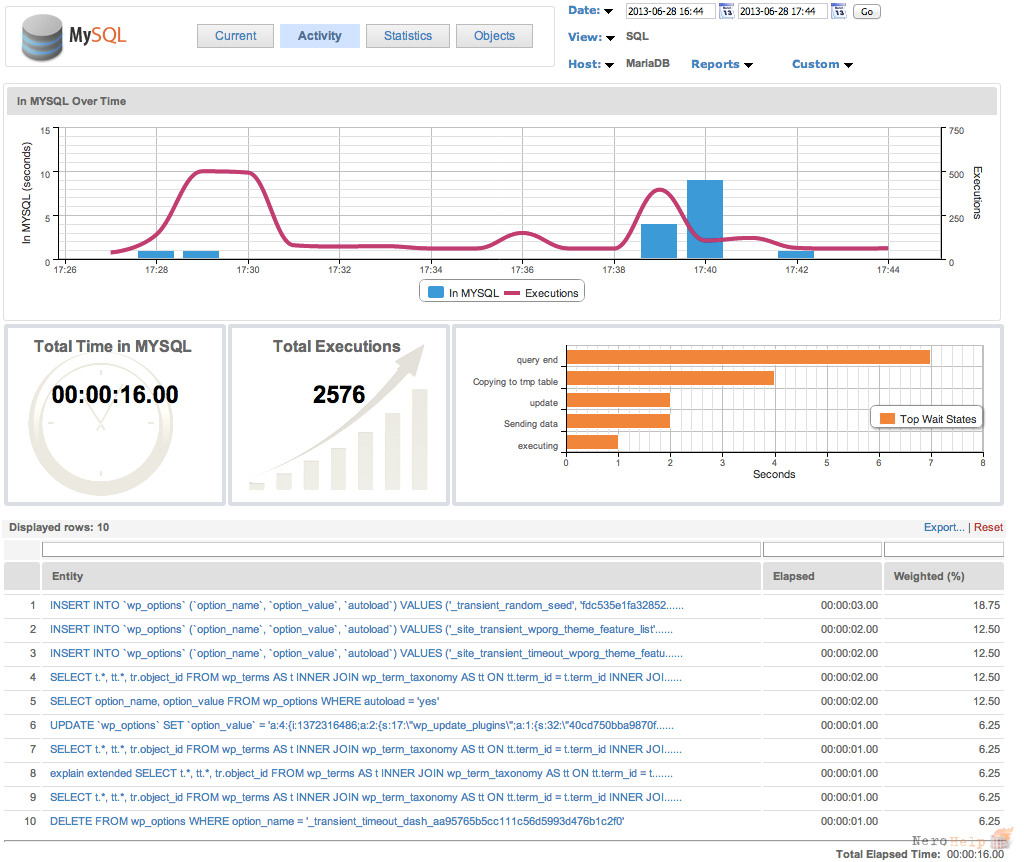
Журнал медленных запросов
Если определить тяжелые запросы «на глаз» не получается, нужно собрать более обширную статистику. В этом поможет журнал медленных запросов (slow query log).
Для включения журнала в MySQL, начиная с версии 5.1.29, задайте переменной slow_query_log значение 1 или ON; для отключения журнала — 0 или OFF. В более старых версиях используется log-slow-queries = /var/db/mysql/slow_queries.log (путь можно задать другой).
Вторая важная настройка — long_query_time — порог времени выполнения, при превышении которого запрос считается медленным и записывается в журнал. Начиная с MySQL 5.1.21 может задаваться в микросекундах и может быть равен нулю.
Пара полезных дополнительных настроек:
- log-queries-not-using-indexes – запись в журнал запросов, не использующих индексы.
- slow_query_log_file – имя файла журнала. По умолчанию host_name-slow.log
Пример для записи в журнал всех запросов, выполняющихся дольше 50 миллисекунд:
Пример для старых версий MySQL, все запросы дольше 1 секунды:
Для анализа журнала используются утилиты mysqldumpslow, mysqlsla и mysql_slow_log_filter. Они парсят журнал и выводят агрегированную информацию о медленных запросах.
mysqldumpslow – утилита из состава MySQL. Вызывается таким образом: . Пример:
Reading mysql slow query log from /usr/local/mysql/data/mysqld51-apple-slow.log
Count: 1 Time=4.32s (4s) Lock=0.00s (0s) Rows=0.0 (0), root@localhost
insert into t2 select * from t1
Count: 3 Time=2.53s (7s) Lock=0.00s (0s) Rows=0.0 (0), root@localhost
insert into t2 select * from t1 limit N
Count: 3 Time=2.13s (6s) Lock=0.00s (0s) Rows=0.0 (0), root@localhost
insert into t1 select * from t1
Count – сколько раз был выполнен запрос данного типа. Time – среднее время выполнения запроса, дальше в скобках – суммарное время выполнения всех запросов данного типа.
Некоторые параметры mysqldumpslow:
- -t N – отображать только первые N запросов.
- -g pattern — анализировать только запросы, которые соответствуют шаблону (как grep).
- -s sort_type — как сортировать вывод. Значения sort_type: t или at — сортировать по суммарному или среднему времени выполнения запросов, c — по количеству выполненных запросов данного типа.
mysqlsla – еще одна утилита для анализа логов MySQL с аналогичной функциональностью. Пример использования:
Подробности в документации.mysql_slow_log_filter — perl-скрипт с похожей функциональностью. Пример использования:
Эта команда в реальном времени покажет запросы, выполняющиеся дольше 0,5 секунды или сканирующие больше 1000 строк.
Выявленные медленные запросы дальше можно оптимизировать, используя .
Вторая часть статьи будет посвящена тонкой настройке MySQL. Материал находится в разработке.
Используйте NOT NULL, если это возможно
Если есть особые причины использовать NULL — используйте его. Но перед этим спросите себя — есть ли разница между пустой строкой и NULL (для INT — 0 или NULL). Если таких причин нет, используйте NOT NULL.NULL занимает больше места и, к тому же, усложняет сравнения с таким полем. Избегайте его, если это возможно. Тем не менее, бывают веские причины использовать NULL, это не всегда плохо.Из документации MySQL:«Столбцы NULL занимают больше места в записи, из-за необходимости отмечать, что это NULL значение. Для таблиц MyISAM, каждое поле с NULL занимает 1 дополнительный бит, который округляется до ближайшего байта».
Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE.
![]()
Рассмотрим запрос из примера:
Нам необходимо создать индекс на колонку age:
После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
Для запросов такого вида:
действует такое же правило — создаем индекс на колонку, по которой происходит сортировка:
Внутренности хранения индексов
Представим, что наша таблица выглядит так:
id | name | age
1 | Den | 29 2 | Alyona | 15 3 | Putin | 89 4 | Petro | 12
После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
age index
12 15 29 89
Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
age index и связь с записями
12: 4 15: 2 29: 1 89: 3
Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
OPTIMIZE TABLE
The basic syntax for this command is as follows.
OPTIMIZE TABLE myTable1, myTable2; OPTIMIZE NO_WRITE_TO_BINLOG TABLE myTable1, myTable2;
The option can be used if you don’t want the operation to be pushed to replication slaves.
The following is a quote from the documentation for this command.
This is an over simplistic view of the operation. In the case of a table with a primary key index, the optimize operation will compact the data and may improve performance. For tables with secondary indexes, the optimize operation may adversely affect performance by causing index fragmentation in the secondary indexes. You can read more about this here.
There is no hard and fast rule for when to issue an command, although some would say never! If you do decide it is necessary, it may be sensible to drop and secondary indexes, perform the command, then recreate the secondary indexes.
Предложения
Will you explain it in plain English?Ты объяснишь это человеческим языком?
Explain to me why Tom isn’t here.Объясните мне, почему нет Тома.


I’ll explain it to her.Я объясню ей это.
I have to explain this to her.Я должен ей это объяснить.
Can you explain why you were late?Вы можете объяснить причину своего опоздания?
Explain to me in detail how it happened.Объясни мне подробно, как это случилось.
Tom couldn’t explain why.Том не смог объяснить почему.
I’d explain it to you, but your brain would explode.Я бы объяснил тебе, но у тебя башка взорвётся.
I’ll explain it to him.Я объясню ему это.
I can’t explain the reason for his conduct.Я не могу объяснить причину его поведения.
One explains the other.Одно объясняет другое.
There any many answers to this questions, and many legends are created about the Devil’s stone by the people: human mind cannot calm down until it explains to itself the dark, the unknows, the vague.Много ответов есть на этот вопрос, много легенд сложено людьми про Чёртов камень: разум человеческий не может успокоиться, пока не разъяснит себе тёмное, неизвестное, неясное.
That explains everything.Это всё объясняет.
That explains why the door is open.Этим объясняется, почему дверь открыта.
Oh, that. That explains it.А, вот как. Это объясняет дело.
Oh, that explains everything!О, это всё объясняет!
Science explains many things that religion never could explain.Наука объясняет множество вещей, которые религия не могла объяснить никогда.
That explains it.Это все объясняет.
That explains a lot.Это многое объясняет.
It is a fine hypothesis; it explains many things.Это хорошая гипотеза, она объясняет много вещей.
Tom explained how he lost his money.Том объяснил, как он потерял свои деньги.
He explained it in detail.Он объяснил это в деталях.
Max explained to Julie why he could not go to her farewell party.Макс объяснил Джули, почему он не мог прийти на её прощальную вечеринку.
We explained the situation.Мы объяснили ситуацию.
I’ve explained the problem to Tom.Я объяснил проблему Тому.
He explained the process of building a boat.Он объяснил процесс построения лодки.
The lawyer explained the new law to us.Адвокат объяснил нам новый закон.
He explained his position to me.Он объяснил мне свою позицию.
My neighbours have already explained to me who Björk is.Мои соседи уже объяснили мне, кто такая Бьорк.
Tom explained it.Том объяснил это.
◆ check_acl_for_explain()
|
static |
Check that we are allowed to explain all views in list.
Because this function is called only when we have a complete plan, we know that:
- views contained in merge-able views have been merged and brought up in the top list of tables, so we only need to scan this list
- table_list is not changing while we are reading it. If we don’t have a complete plan, EXPLAIN output does not contain table names, so we don’t need to check views.
- Parameters
-
table_list table to start with, usually lex->query_tables
- Returns
- true Caller can’t EXPLAIN query due to lack of rights on a view in the query false Caller can EXPLAIN query
Общие настройки
max_connections=64 — устанавливаем параметр минимальным возможным при необходимости экономить ресурсы сервера, при возникновении в логе записей вида «Too many connections…» увеличиваем значение. Не следует изменять значение этого параметра на старте. 4000 клиентов является максимумом. Можно довести максимальное количество клиентов до 7000, но для стандартных сборок 4000 является пределом.
open_files_limit = 2048 Устанавливать значение стоит опираясь на существующее количество открытых файлов MySQL:
В конфигурационном файле задается большее значение.
connect_timeout (MySQL pre-5.1.23: default 5, MySQL 5.1.23+: default 10) — количество секунд по прошествии которых сервер баз данных будет выдавать ошибку, при активном веб-сервере значение можно уменьшать чтобы увеличить скорость работы, на медленной машине — можно увеличивать. max_connect_errors (default 10) — максимальное количество единовременных соединений с сервером баз данных с хоста запрос блокируется если он прерывается запросами с того же хоста до момента окончания обработки запроса) блокируются навсегда, очистить можно только из командной оболочки MySQL:
В случае атаки на сервер нужно уменьшать (5) чтобы отсекать попытки соединения, при большой активности веб-сервера можно увеличивать max_allowed_packet (default 1M) — максимальный для буфера соединений и буфера результата при исполнении SQL инструкций. Каждый тред имеет свой буфер. Хорошим значением для начала будет 16М. tmp_table_size (system-specific default) — максимальный размер памяти выделяемой под хранение временных таблиц. 16М — довольно много.
Примеры готовых конфигураций для разных объёмов памяти можно посмотреть здесь.
Чтобы посомореть значения переменных можно воспользоваться SQL запросом:
или для конкретных переменных:
Чтобы проверить мониториг InnoDB, используте:
Чтобы узнать, не свопается ли память, используйте команду и смотрите строку swap:
Рекомендации по проектированию индексов с целью оптимизации запросов
Некластеризованные индексы необходимо создавать для всех столбцов, которые часто используются в условиях (WHERE) и в объединениях (JOIN);
По возможности не стоит создавать индексы, в которых очень много ключевых столбцов, так как это влияет на размер индекса и на ресурсы его поддержания;
Эффективно использовать покрывающие индексы, т.е. индексы которые включают все столбцы, используемые в запросе (это называется «Покрытием запроса»). Благодаря этому оптимизатор запросов может найти все значения столбцов в индексе, при этом не обращаясь к данным таблиц, что приводит к меньшему числу дисковых операций ввода-вывода





Это можно достичь с помощью включения в индекс неключевых столбцов (включенные столбцы), но также следует принять во внимание, что это влечет за собой увеличение размера индекса;
Если есть возможность, то рекомендовано заменять неуникальный индекс уникальным для той же комбинации столбцов, это обеспечивает оптимизатору запросов дополнительные сведения, что может сделать индекс более эффективным;
При создании индекса учитывайте порядок ключевых столбцов, это повышает производительность индекса. Например, столбцы, которые используются в предложении WHERE в условиях поиска равно (=), больше (>), меньше (
Если таких несколько, то упорядочивайте их по уровню различности, т.е. от наиболее четкого к наименее четкому;
Попробуйте применить отфильтрованные индексы для столбцов, имеющих точно определенные подмножества, так как в некоторых случаях такие индексы могут увеличить скорость выполнения запроса по сравнению с обычными (полнотабличными) индексами;
Также рекомендуется проектировать запросы на изменение данных так, чтобы они вставляли или изменяли как можно больше строк одной инструкцией, т.е. не используйте для тех же операций несколько запросов.
На этом у меня все, надеюсь, материал был Вам полезен и интересен, пока!
Нравится4Не нравится
Общие рекомендации по проектированию индексов в Microsoft SQL Server
- Одним из самых эффективных индексов является индекс для целочисленных столбцов, которые имеют уникальные значения, поэтому по возможности создавайте индексы для таких столбцов;
- Если таблица очень интенсивно обновляется, то не рекомендуется создавать большое количество индексов, так как это снижает производительность инструкций INSERT, UPDATE, DELETE и MERGE. Потому что после изменений данных в таблице SQL сервер автоматически вносит соответствующие изменения во все индексы;
- Если таблица с большим объемом данных обновляется редко, при этом она активно используется в инструкциях SELECT, т.е. на выборку данных, то большое количество индексов может улучшить производительность, так как у оптимизатора запросов будет больший выбор индексов при определении наиболее эффективного и быстрого способа доступа к данным;
- Если создавать некластеризованный индекс в файловой группе, которая расположена не на том диске, на котором расположены файловые группы таблицы, то это может повысить производительность для больших таблиц и индексов, так как это позволяет одновременно обращаться к нескольким дискам;
- Для таблиц с небольшим объемом данных создание индексов в частности некластеризованных индексов с целью повышения производительности может оказаться абсолютно бесполезно, да еще и затратами на их поддержание. Так как оптимизатору может потребоваться больше времени на поиск данных в индексе, чем просмотр данных в самой таблице. Поэтому не создавайте индексы для таблиц, в которых очень мало данных;
- Кластеризованный индекс необходимо создавать для столбца, который является уникальным и не принимает значения NULL, также длина ключа должна быть небольшой, другими словами ключ индекса не нужно составлять из нескольких столбцов;
- Если представление содержит агрегаты и объединения таблиц, то индексы для таких представлений могут дать неплохое улучшение производительности.
◆ explain_query()
| explain_query | ( | THD * | explain_thd, |
| const THD * | query_thd, | ||
| SELECT_LEX_UNIT * | unit | ||
| ) |
EXPLAIN handling for SELECT, INSERT/REPLACE SELECT, and multi-table UPDATE/DELETE queries.
Send to the client a QEP data set for any DML statement that has a QEP represented completely by JOIN object(s).
This function uses a specific Query_result object for sending explain output to the client.
When explaining own query, the existing Query_result object (found in outermost SELECT_LEX_UNIT or SELECT_LEX) is used. However, if the Query_result is unsuitable for explanation (need_explain_interceptor() returns true), wrap the Query_result inside an Query_result_explain object.
When explaining other query, create a Query_result_send object and prepare it as if it was a regular SELECT query.
- Note
- see explain_single_table_modification() for single-table UPDATE/DELETE EXPLAIN handling.
- Unlike handle_query(), explain_query() calls abort_result_set() itself in the case of failure (OOM etc.) since it may use an internally created Query_result object that has to be deleted before exiting the function.
- Parameters
-
explain_thd thread handle for the connection doing explain query_thd thread handle for the connection being explained unit query tree to explain
- Returns
- false if success, true if error
For DML statements use QT_NO_DATA_EXPANSION to avoid over-simplification.
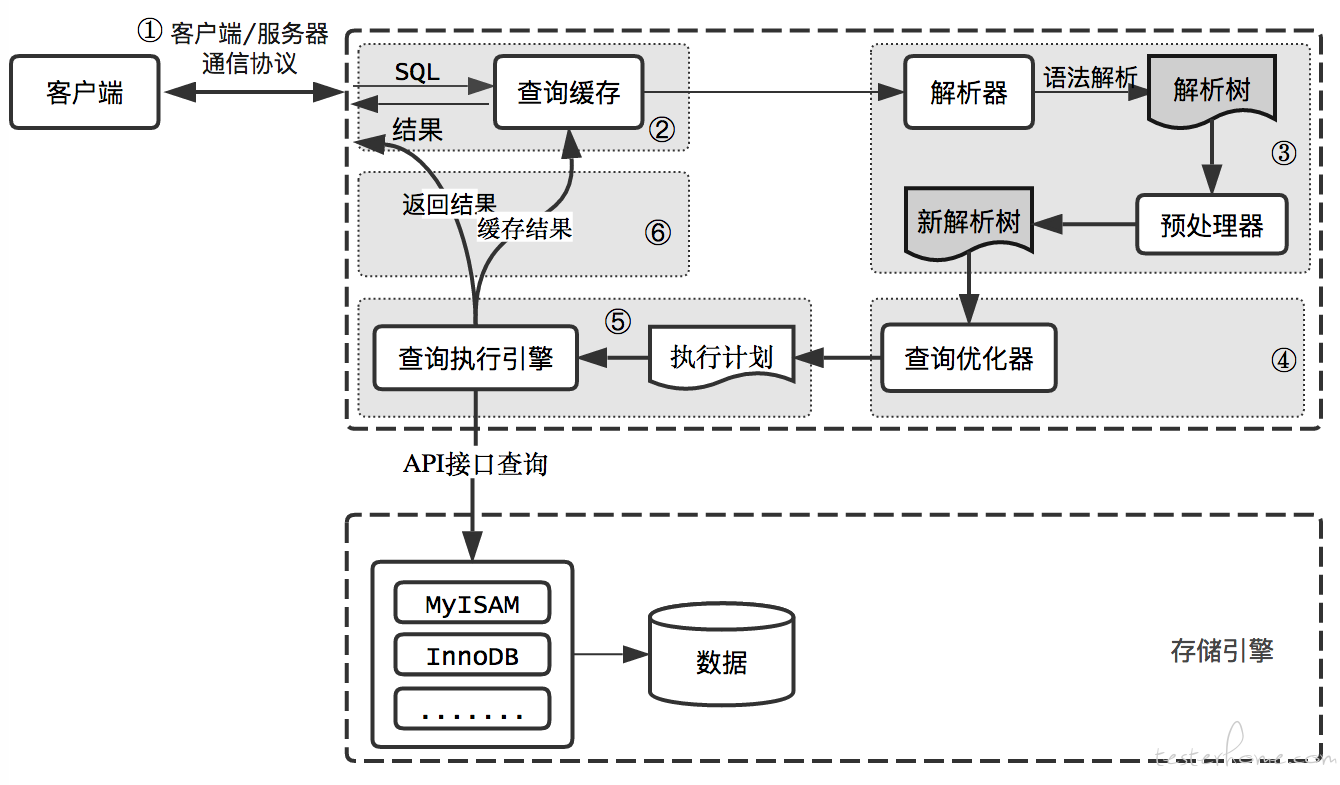
Инструментарий
Запросы
Сервер поддерживает ряд запросов, предназначеных для управления индексами и анализа эффективности их использования.
Самый главный помошник — выводит план выполнения запроса.
Cправочное руководство: EXPLAIN.
Выводит информацию о существующих индексах в конкретной таблице.
Cправочное руководство:
- SHOW
- SHOW INDEX
Создание/удаление индексов.
Cправочное руководство:
- CREATE INDEX
- DROP INDEX
SELECT STRAIGHT_JOIN
Позволяет жестко определить порядок объединения таблиц. В рабочих системах не рекомендовано к использованию, но при исследовании запросов можно проанализировать различные последовательности объединения.
Cправочное руководство: …
Позволяет выбрать индексы, которые сервер может/должен использовать.
Cправочное руководство: …
Справочное руководство: OPTIMIZE TABLE
Статистика
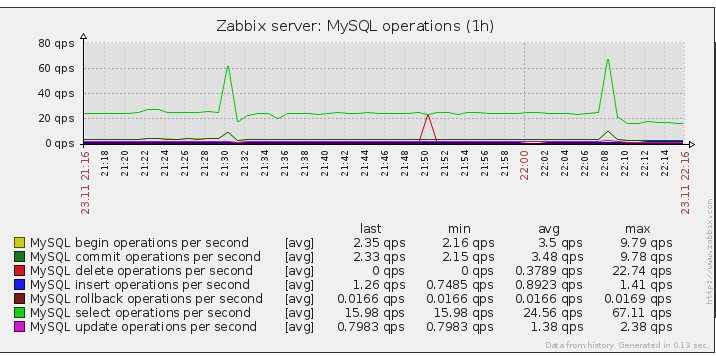
Журнал регистрации(log) медленных запросов
MySQL позволяет настроить запись запросов, время выполнения которых превысило определенный предел, в отдельный файл.
Оценки могут показаться достаточно грубыми — нельзя установить время меньше секунды, но и этого вполне достаточно для выделения самых проблемных запросов. Для более точного протоколирования запросов можно использовать патч, который увеличивает точность до микросекунд. Более подробно про патч можно прочитать здесь.
Очень важно не забывать, что считается время от начала до окончания выполнения запроса, а не время, потраченное конкретно на данный запрос, то есть общая загруженность системы влияет на заполнение этого журнала. Справочное руководство: журнал медленных запросов
Справочное руководство: журнал медленных запросов
Журнал регистрации запросов не использующих индексы
В добавок к предыдущему журналу можно также протоколировать запросы, которые не используют индексы совсем. Для этого в версии 4.0.x активируйте log-long-format, а в 4.1 и выше log-queries-not-using-indexes.
Для результатов используется файл журнала медленных запросов.
Справочное руководство: журнал медленных запросов
Журнал регистрации всех запросов
В крайних случаях можно воспользоваться журналом всех запросов. Сервер протоколирует все подряд запросы без учета времени выполнения.
Рекомендуется использовать только на этапе тестирования. На загруженных системах файл очень быстро разрастается, а также заметно падает производительность сервера.
Справочное руководство: общий журнал запросов
Утилиты для анализа журналов
Пока только список:
- mysql_explain_log похожий скрипт от Jan Willamowius
- slow query log filter + описание и примеры использования
- http://www.jebriggs.com/php/wordpress/?p=135
Когда создавать индекс в MySQL?
К сожалению, у меня нет прямого ответа, когда следует создавать индекс. Однако некоторые сценарии и факторы могут повлиять на создание индекса. Стоит отметить, что вам, возможно, придется пойти на компромисс при создании индекса.
- Высокая доступность: если у вас есть регулярный доступ к таблице или столбцу, вы можете повысить их производительность, создав индекс.
- Размер: размер данных, хранящихся в таблице или столбце, также может играть роль при принятии решения о необходимости индекса. Большая таблица может получить больше преимуществ от индексов, чем меньшая таблица.
- Ключ индекса: тип данных целочисленного ключа также имеет значение. Например, целое число является гораздо лучшим индексным ключом из-за его небольшого размера.
- CRUD-операции: если у вас есть таблица или столбец с большим количеством CRUD-операций, индексирование этой таблицы или столбца может оказаться невыгодным и может отрицательно повлиять на производительность базы данных.
- Размер базы данных: индексирование — это структура данных, которая будет занимать место в вашей базе данных, что может быть важным фактором, особенно в уже больших базах данных.
Выше приведены некоторые ключевые концепции, которые могут быть задействованы при принятии решения о создании индекса базы данных.
Если вы хотите узнать больше о том, как MySQL использует индексы, рассмотрите возможность чтения ресурса, представленного ниже:
https://dev.mysql.com/doc/refman/8.0/en/mysql-indexes.html
Используте ORM
Используя ORM, можно получить определенную оптимизацию работы. Все, что можно сделать с помощью ORM, можно сделать и вручную. Но это требует дополнительной работы и более высокого уровня знаний.ORM замечателен для «ленивой» загрузки данных. Это означает выборку данных по мере необходимости. Но необходимо быть осторожным, т.к это может привести к появлению множества маленьких запросов, что приведет к снижению производительности.ORM также может объединять несколько запросов в пакеты, вместо отправки каждого отдельно.Моя любимая ORM для PHP — Doctrine. Я уже писал статью об установке Doctrine в CodeIgniter.


Разделяйте большие запросы DELETE и INSERT
Если вам необходимо сделать большой запрос на удаление или вставку данных, надо быть осторожным, чтобы не нарушить работу приложения. Выполнение большого запроса может заблокировать таблицу и привести к неправильной работе всего приложения.Apache может выполнять несколько параллельных процессов одновременно. Поэтому он работает более эффективно, если скрипты выполняются как можно быстрее.Если вы блокируете таблицы на долгий срок (например, на 30 секунд или дольше), то при большой посещаемости сайта, может возникнуть большая очередь процессов и запросов, что может привести к медленной работе сайта или даже к падению сервера.Если у вас есть такие запросы, используйте LIMIT, чтобы выполнять их небольшими сериями.
Таблицы фиксированного размера (статичные) — быстрее
Если каждая колонка в таблице имеет фиксированный размер, то такая таблица называется «статичной» или «фиксированного размера». Пример колонок не фиксированной длины: VARCHAR, TEXT, BLOB. Если включить в таблицу такое поле, она перестанет быть фиксированной и будет обрабатываться MySQL по-другому.Использование таких таблицы увеличит эффективность, т.к. MySQL может просматривать записи в них быстрее. Когда надо выбрать нужную строку таблицы, MySQL может очень быстро вычислить ее позицию. Если размер записи не фиксирован, ее поиск происходит по индексу.Так же эти таблицы проще кэшировать и восстанавливать после падения базы. Например, если перевести VARCHAR(20) в CHAR(20), запись будет занимать 20 байтов, вне зависимости от ее реального содержания.Используя метод «вертикального разделения», вы можете вынести столбцы с переменной длиной строки в отдельную таблицу.
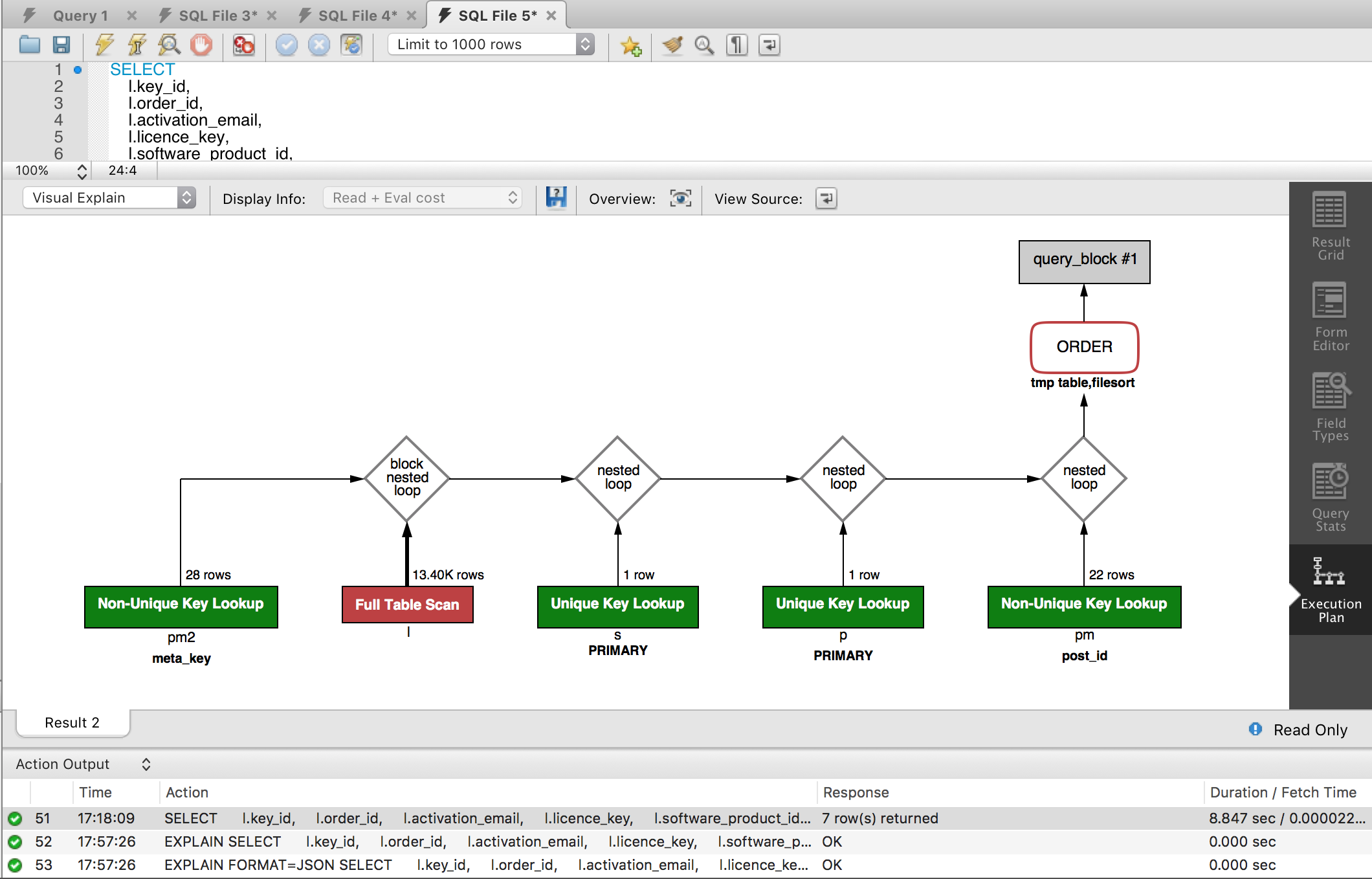
Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:
mysql> EXPLAIN SELECT * FROM users WHERE email = ''; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 336 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+
Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:
mysql> EXPLAIN SELECT * FROM users WHERE email = ''; +----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+ | 1 | SIMPLE | users | const | email | email | 386 | const | 1 | | +----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
Прочитана всего одна запись, т.к. был использован индекс.
Проверка длинны составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):
mysql> EXPLAIN SELECT * FROM users WHERE age = 29 AND gender = 'male'; +----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+ | 1 | SIMPLE | users | ref | age_gender | age_gender | 24 | const,const | 1 | Using where | +----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
Значение key_len показывает используемую длину индекса. В нашем случае 24 байта — длинна всего индекса (5 байт age + 19 байт gender).
Если мы выполним изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:
mysql> EXPLAIN SELECT * FROM users WHERE age <= 29 AND gender = 'male'; +----+-------------+--------+------+---------------+------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------------+---------+------+------+-------------+ | 1 | SIMPLE | users | ref | age_gender | age_gender | 5 | | 82 | Using where | +----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:
mysql> Create index gender_age on users(gender, age); mysql> EXPLAIN SELECT * FROM users WHERE age < 29 and gender = 'male'; +----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+ | 1 | SIMPLE | users | range | age_gender,gender_age | gender_age | 24 | NULL | 47 | Using where | +----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
Поиск дублирующихся индексов
Дублирующиеся индексы не всегда замедляют запросы на выборку. Но они могут замедлить операции вставки/обновления, а также увеличивают размер используемого дискового пространства. В общем, лучше избегать дублирование ключей.
В Percona Toolkit можно найти инструмент под названием pt-duplicate-key-checker. Этот инструмент проанализирует вашу базу данных, и покажет, какие таблицы содержат дублирующиеся ключи. Представим, что у нас есть следующая таблица:
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `firstname` varchar(255) NOT NULL, `lastname` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `id_firstname` (`id`,`firstname`), KEY `firstname` (`firstname`), KEY `firstname_2` (`firstname`), KEY `firstname_lastname_id` (`firstname`,`lastname`,`id`) ) ENGINE=InnoDB
В этой таблице можно заметить три дублирующихся ключа. Запустим утилиту для того, чтобы определить, какие ключи дублируются.
# ######################################################################## # user # ######################################################################## # firstname_2 is a left-prefix of firstname_lastname_id # Key definitions: # KEY `firstname_2` (`firstname`), # KEY `firstname_lastname_id` (`firstname`,`lastname`,`id`) # Column types: # `firstname` varchar(255) not null # `lastname` varchar(255) not null # `id` int(11) not null auto_increment # To remove this duplicate index, execute: ALTER TABLE `user` DROP INDEX `firstname_2`; # firstname is a left-prefix of firstname_lastname_id # Key definitions: # KEY `firstname` (`firstname`), # KEY `firstname_lastname_id` (`firstname`,`lastname`,`id`) # Column types: # `firstname` varchar(255) not null # `lastname` varchar(255) not null # `id` int(11) not null auto_increment # To remove this duplicate index, execute: ALTER TABLE `user` DROP INDEX `firstname`; # Key firstname_lastname_id ends with a prefix of the clustered index # Key definitions: # KEY `firstname_lastname_id` (`firstname`,`lastname`,`id`) # PRIMARY KEY (`id`), # Column types: # `firstname` varchar(255) not null # `lastname` varchar(255) not null # `id` int(11) not null auto_increment # To shorten this duplicate clustered index, execute: ALTER TABLE `user` DROP INDEX `firstname_lastname_id`, ADD INDEX `firstname_lastname_id` (`firstname`,`lastname`); # ######################################################################## # Summary of indexes # ######################################################################## # Size Duplicate Indexes 1032 # Total Duplicate Indexes 3 # Total Indexes 5
Хоть индекс является дубликатом индекса , на самом деле они оба являются дубликатом индекса . Почему же это так? Потому, что также является крайним левым префиксом ключа . Когда вы генерируете индекс по трем полям (A, B, C), на самом деле покрываются три индекса:
- A
- A, B
- A, B, C
Так как ключ является первым полем в индексе , нет необходимости в создании отдельного индекса.
Последний найденный индекс может привести в замешательство. Согласно утилите, индекс может быть упразднен. В этом случае это из-за того, что мы используем движок InnoDB. InndoDB использует кластерные индексы, в которых хранятся данные столбца. Обычно InoDB использует первичный ключ в качестве идентификатор кластера. То есть, InnoDB уже использует значение поля id в ключе, следовательно, для этого поля не надо задавать отдельный индекс.
Оптимизация использования индексов
Как я уже говорил, MySQL может не использовать индексы, даже когда они присутствуют! Для примера возьмем ту же таблицу test2, и извлечем из нее все значения, у которых id > 1 (это 9998 записей), а затем все значения, у которых id > 123456 (это 0 записей):
mysql> EXPLAIN SELECT * FROM test2 WHERE id > 1; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | ALL | PRIMARY | NULL | NULL | NULL | 9999 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ mysql> EXPLAIN SELECT * FROM test2 WHERE id > 123456; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | range | PRIMARY | PRIMARY | 4 | NULL | 13 | Using where | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
В первом случае, индекс по полю id не используется. Во втором, MySQL заранее знает, что таких значений не более 13, и потому использует индекс (см. поле key). Но мы можем замедлить запрос, вызвав поиндексное сканирование таблицы при помощи инструкции FORCE INDEX(PRIMARY). Если в таблице имеется несколько индексов, можно указать любой из них. Для использования основного индекса, применяется служебное слово PRIMARY.
mysql> SELECT * FROM test2 WHERE id > 1; 9998 rows in set (0.08 sec) mysql> SELECT * FROM test2 FORCE INDEX(PRIMARY) WHERE id > 1; 9998 rows in set (0.23 sec)
А вот планы выполнения обоих запросов:
mysql> EXPLAIN SELECT * FROM test2 FORCE INDEX(PRIMARY) WHERE id > 1; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | range | PRIMARY | PRIMARY | 4 | NULL | 9998 | Using where | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ 1 row in set (0.00 sec) mysql> EXPLAIN SELECT * FROM test2 WHERE id > 1; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | ALL | PRIMARY | NULL | NULL | NULL | 9999 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec)
Также необходимо иметь ввиду, что база данных не будет использовать более одного индекса, и при помощи FORCE INDEX можно заставить ее использовать именно тот индекс, который нужен (если он определен неправильно). Для определения нужного индекса, используется максимально «уникальный» индекс. Узнать, какой из индексов максимально привлекателен, можно при помощи запроса SHOW KEYS FROM test2. Уникальность индекса характеризует столбец Cardinality.