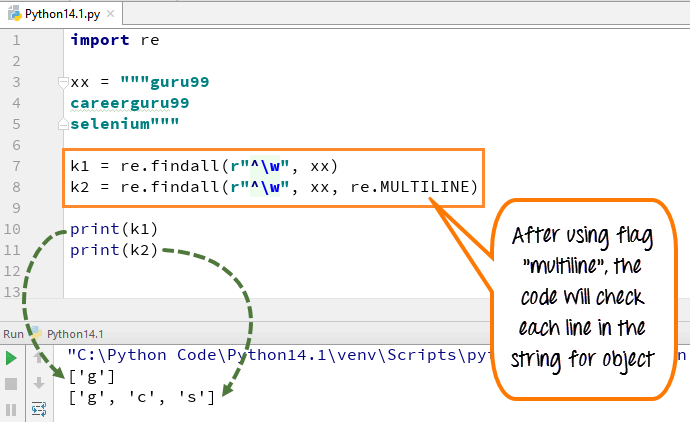
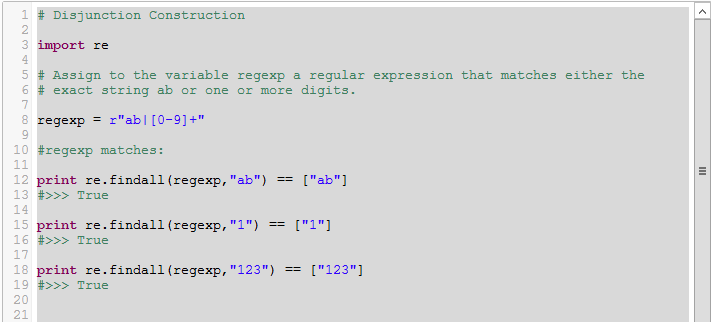
re.compile
Последний метод,
который мы рассмотрим в модуле re – это
re.compile(pattern,
flags)
который
выполняет компиляцию регулярного выражения и возвращает его в виде экземпляра
класса Pattern.
Компиляция
регулярного выражения выполняется, если один и тот же шаблон используется
многократно. Например, нашу предыдущую программу можно записать так:
text = """Москва
Казань
Тверь
Самара
Уфа"""
count =
def replFind(m):
global count
count += 1
return f"<option value='{count}'>{m.group(1)}</option>\n"
rx = re.compile(r"\s*(\w+)\s*")
list, total = rx.subn(r"<option>\1</option>\n", text)
list2 = rx.sub(replFind, text)
print(list, total, list2, sep="\n")
Смотрите, мы
здесь сначала скомпилировали шаблон и сохранили ссылку rx на класс Pattern. Затем, уже из
него вызываем методы subn и sub, но без
указания регулярного выражения, так как эти методы мы вызываем не из модуля re, а из класса Pattern. В нем они
переопределены так, чтобы не писать шаблон, который уже известен.
В общем случае,
класс Pattern имеет все те же
методы, что мы рассмотрели на этом и предыдущем занятиях модуля re и несколько
уникальных свойств:
-
flags – возвращает
список флагов, которые были установлены при компиляции; -
pattern
– строка
исходного шаблона; -
groupindex – словарь, ключами
которого являются имена сохраняющих групп, а значениями – номера групп (пустой,
если имена не используются).
Вот так можно
оперировать регулярными выражениями через методы модуля re.
Видео по теме
Регулярные выражения #1: литералы и символьный класс
Регулярные выражения #2: квантификаторы {m,n}
Регулярные выражения #3: сохраняющие скобки и группировка
Регулярные выражения #4: флаги и проверки
Регулярные выражения #5: объект re.Match, методы re.search, re.finditer, re.findall
Регулярные выражения #6: методы re.match, re.split, re.sub, re.subn, re.compile
Морж в комнате: выражение присваивания
Самое большое изменение в Python 3.8 — это введение выражений присваивания. Они написаны с использованием новой записи (: =). Этого оператора часто называют оператор морж (walrus), так как он напоминает глаза и бивни моржа на боку.
Выражения присваивания позволяют вам присваивать и возвращать значение в одном выражении. Например, если вы хотите присвоить переменную и вывести ее значение, вы обычно делаете что-то вроде этого:
>>> walrus = False >>> print(walrus) False
В Python 3.8 вам разрешено объединять эти два оператора в один, используя оператор walrus:
>>> print(walrus := True) True
Выражение присваивания позволяет присвоить True walrus и сразу же вывести значение. Но имейте в виду, что оператор walrus не делает ничего такого чего нельзя было бы сделать без него. Он только делает некоторые конструкции более удобными, и иногда может более четко сообщать о намерениях вашего кода.
Один из примеров, демонстрирующий некоторые сильные стороны оператора walrus, — это циклы while, где вам нужно инициализировать и обновить переменную. Например, следующий код запрашивает ввод у пользователя, пока он не наберет quit:
inputs = list()
current = input("Write something: ")
while current != "quit":
inputs.append(current)
current = input("Write something: ")
Этот код не идеален. Вы повторяете оператор input() два раза, так как вам нужно каким-то образом получить current, прежде чем зайти в цикл. Лучшее решение — установить бесконечный цикл while и использовать break для остановки цикла:
inputs = list()
while True:
current = input("Write something: ")
if current == "quit":
break
inputs.append(current)
Этот код эквивалентен приведенному выше, но избегает повторения и каким-то образом сохраняет строки в более логичном порядке. Если вы используете выражение присваивания, вы можете еще больше упростить этот цикл:
inputs = list()
while (current := input("Write something: ")) != "quit":
inputs.append(current)
PEP 572 описывает более подробно выражения присваивания, включая некоторые обоснования для их введения в язык, а также дает несколько того, как можно использовать оператор walrus.
Еще несколько примеров
Кэширование возвращаемых значений
Декораторы могут предоставить элегантный способ запоминания (кэширования) возвращаемых значений функции.
Представим себе следующую ситуацию, у нас в приложении используется достаточно ресурсоемкий (или с длительным временем обращения) API, и вы хотели бы, по возможности, как можно реже к нему обращаться. Идея состоит в том, чтобы сохранять и кэшировать значения, возвращаемые вызовами API для конкретных значений параметров запроса. В случае их повторного запроса с помощью API с указанными аргументами, вы могли бы просто сразу возвращать результаты из кэша вместо совершения повторного вызова методов API. Этот прием может значительно улучшить производительность вашего приложения. В примере кода ниже я смоделировал “дорогой” вызов API с использованием модуля time.
import functools
import time
def api(a):
"""API принимает в качестве параметра целое число и возвращает его квадрат.
Для имитации времени работы процесса обращения я добавил временную задержку."""
print("The API has been called...")
# Сделаем задержку 3 сек
time.sleep(3)
return a * a
api(3)
>>> The API has been called...
9
И так запуск и выполнение функции занимает примерно 3 секунды. Для того, чтобы кэшировать результат ее выполнения, мы можем использовать функцию . С ее помощью мы можем сохранить результат выполнения функции в словаре, а затем использовать его, когда снова будет необходим запрос к API с тем же параметром. При этом словарь, содержащий информацию о прошлых запросах к API, будет иметь следующий вид: в качестве ключей будет использоваться значение параметра запроса, а в качестве значения, соответствующего ключу – ответ API (результат выполнения функции). Единственным недостатком этого способа является то, что параметры (аргументы) запроса к API должны иметь такой вид, что могут быть легко преобразованы в хэш, а точнее корректное наименование ключа словаря.




import functools
@functools.lru_cache(maxsize=32)
def api(a):
"""API принимает в качестве параметра целое число и возвращает его квадрат.
Для имитации времени работы процесса обращения я добавил временную задержку."""
print("The API has been called...")
# This will delay 3 seconds
time.sleep(3)
return a * a
api(3)
>>> 9
Особенностью технической реализации метода является принцип хранения полученных ранее результатов Least Recently Used LRU, что подразумевает организацию элементов словаря в порядке их использования, что позволяет быстро определить, какой элемент не использовался в течение длительного времени.
В примере кода выше параметр метода определяет максимальное число возвращаемых значений, которые могут быть сохранены до того, как он начнет удалять самые ранние из них. И теперь если мы запустим функцию на выполнение, то увидим, что первый раз для возврата ее результата потребуется около 3 секунд. Но если вы снова запустите ее с тем же параметром, то она почти мгновенно вернет результат из своего кэша.
Преобразование единиц измерения
Следующий декоратор, который мы рассмотрим преобразует длину из единиц измерения СИ в единицы измерения других систем, не загрязняя целевую декорируемую функцию логикой преобразования.
import functools
def convert(func=None, convert_to=None):
"""Этот код конвертирует единицы измерения из одного типа в другой."""
if func is None:
return functools.partial(convert, convert_to=convert_to)
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"Conversion unit: {convert_to}")
val = func(*args, **kwargs)
# Добавим правила для преобразования
if convert_to is None:
return val
elif convert_to == "km":
return val / 1000
elif convert_to == "mile":
return val * 0.000621371
elif convert_to == "cm":
return val * 100
elif convert_to == "mm":
return val * 1000
else:
raise ValueError("Conversion unit is not supported.") # этот тип единиц не поддерживается
return wrapper
Давайте используем этот пример кода и применим этот декоратор для функции, которая рассчитывает площадь прямоугольника.
@convert(convert_to="mile")
def area(a, b):
return a * b
area(1, 2)
>>> Conversion unit: mile
0.001242742
Полученный результат вызова функции расчета площади, к которой мы применили наш декоратор, показывает, что она не только рассчитывает правильное значение, но и выводит единицу длинны в которую мы преобразовывали входные значения. Поэкспериментируйте с другими единицами измерения и посмотрите, что получится.
Capturing groups
Capturing groups is a way to treat multiple characters as a single unit.
They are created by placing characters inside a set of round brackets.
For instance, (book) is a single group containing ‘b’, ‘o’, ‘o’, ‘k’,
characters.
The capturing groups technique allows us to find out those parts of a
string that match the regular pattern.
capturing_groups.py
#!/usr/bin/python3
import re
content = '''<p>The <code>Pattern</code> is a compiled
representation of a regular expression.</p>'''
pattern = re.compile(r'(</?*>)')
found = re.findall(pattern, content)
for tag in found:
print(tag)
The code example prints all HTML tags from the supplied string by
capturing a group of characters.
found = re.findall(pattern, content)
In order to find all tags, we use the method.
$ ./capturing_groups.py <p> <code> </code> </p>
We have found four HTML tags.
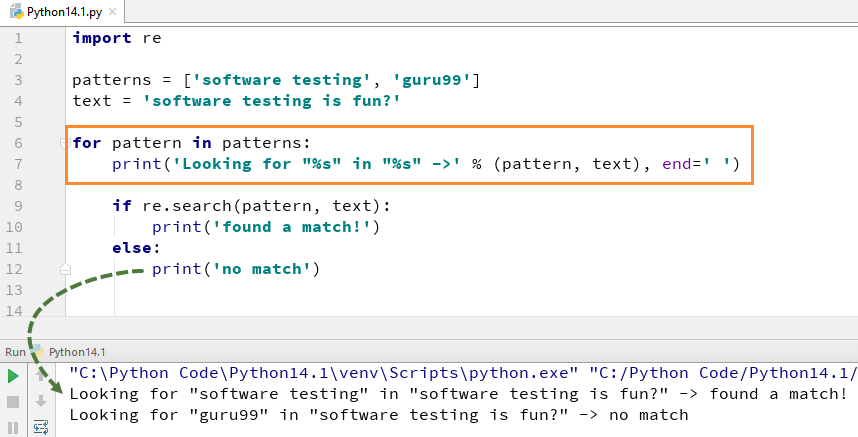
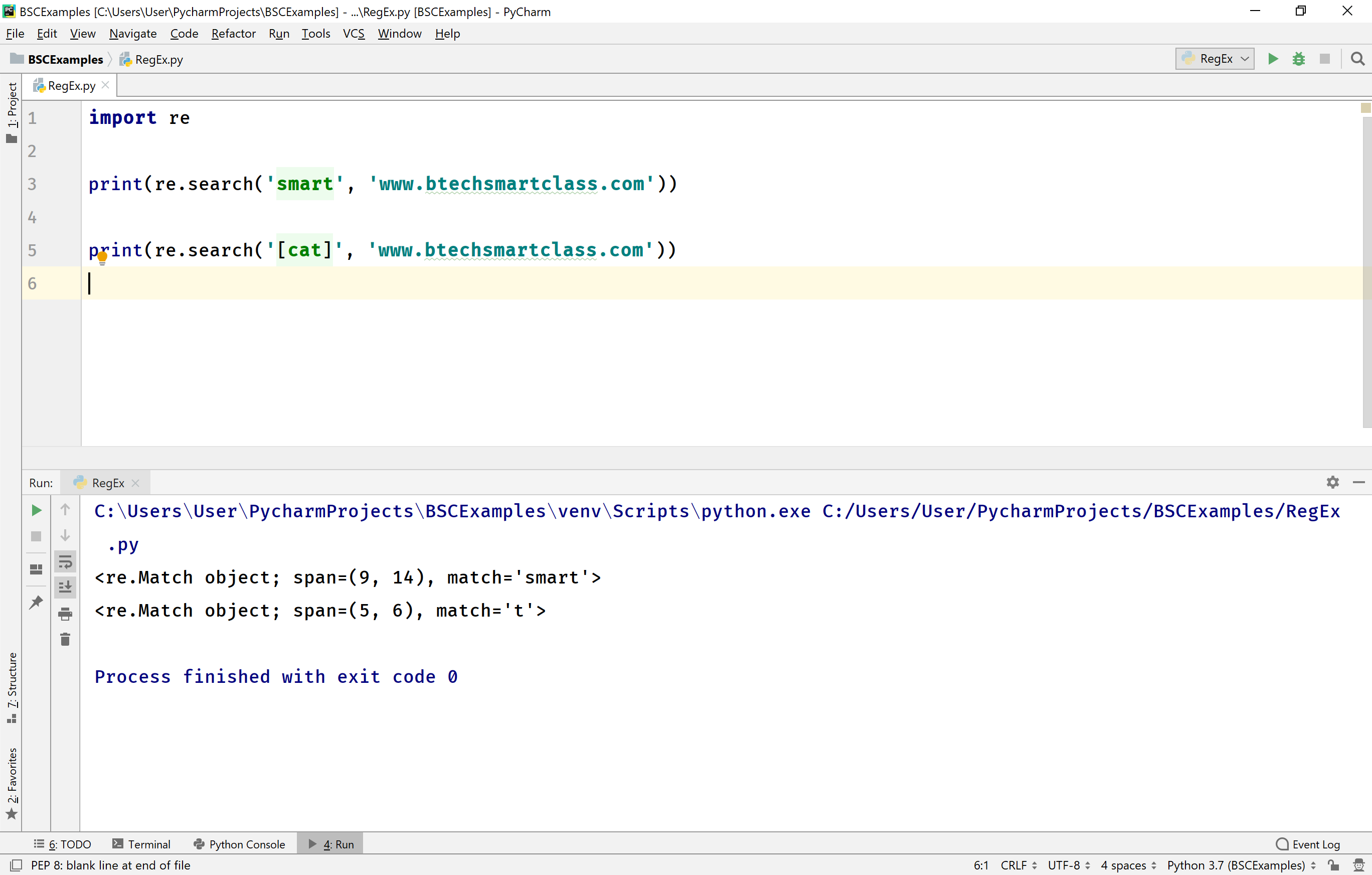
re.search()
Этот метод возвращает совпадающую часть строки и останавливается сразу же, как находит первое совпадение. Таким образом, его можно использовать для проверки выражения, а не для извлечения данных.
Синтаксис:
Возвращаемое значение может быть либо подстрокой, соответствующей шаблону, либо , если такой подстроки не окажется.
Давайте разберем пример: поищем в строке месяц и число.
import re
regexp = r"(+) (\d+)"
match = re.search(regexp, "My son birthday is on July 20")
if match != None:
print("Match at index %s, %s" % (match.start(), match.end())) #This provides index of matched string
print("Full match: %s" % (match.group(0)))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
else:
print("The given regex pattern does not match")
Что делает следующая программа?
import threading, Queueitem = Queue.Queue()def consumer(nm): while True: print item.get(), nmdef producer(nm): while True: item.put(nm)for n in range(3): threading.Thread(target=consumer, args=(«»c»»+str(n),)).start() threading.Thread(target=producer, args=(«»p»»+str(n),)).start()
- (Правильный ответ) программа беспрерывно печатает строки вида pN cM, где N — номер производителя, а M — номер потребителя
- программа содержит ошибку в цикле, где запускаются потоки
- программа беспрерывно печатает строки вида p0 c0, p1 c1 или p2 c2, где число после p — номер производителя, а число после c — номер потребителя
- программа ничего не делает или, в некоторых случаях, успевает напечатать несколько строк вида pN cM, после чего останавливается на попытке прочитать из пустой очереди
Sets
A set is a set of characters inside a pair of square brackets with a special meaning:
| Set | Description | Try it |
|---|---|---|
| Returns a match where one of the specified characters (, , or ) are present |
Try it » | |
| Returns a match for any lower case character, alphabetically between and |
Try it » | |
| Returns a match for any character EXCEPT , , and |
Try it » | |
| Returns a match where any of the specified digits (, , , or ) are present |
Try it » | |
| Returns a match for any digit between and |
Try it » | |
| Returns a match for any two-digit numbers from and | Try it » | |
| Returns a match for any character alphabetically between and , lower case OR upper case |
Try it » | |
| In sets, , , , , , , has no special meaning, so means: return a match for any character in the string |
Try it » |
Шаблоны в structural pattern matching
Шаблоны могут быть простыми значениями или содержать более сложную логику сопоставления.
Вот несколько примеров:
case ’a’: сопоставить с единственным значением ’a’.
case : сопоставить с коллекцией (collection) .
case : сопоставить с коллекцией, в которой два значения, и поместить второе значение в переменную value1.
case : сопоставить с коллекцией, в которой как минимум одно значение. Остальные значения, если они есть, хранить в values
Обратите внимание, что вы можете включить только один элемент со звездочкой в шаблон.
case (’a’|’b’|’c’): Оператор or, он же |, может использоваться для обработки нескольких обращений в одном блоке case. Здесь мы сопоставляем ’a’, ’b’, или ’c’.
case (’a’|’b’|’c’) as letter: То же, что и выше, за исключением того, что теперь мы помещаем соответствующий элемент в переменную letter.
case if Переменная связывается только если expression истинно
Переменные, которые мы хотим связать, можно использовать в . Например, если мы используем if value in valid_values, то case будет действительным только в том случае, если захваченное значение value был на самом деле в коллекции valid_values.
case : будет соответствовать любая коллекция элементов, которая начинается с ’z’.
Пример использования всех основных функций
import re
match = re.search(r'\d\d\D\d\d', r'Телефон 123-12-12')
print(match.group(0) if match else 'Not found')
# -> 23-12
match = re.search(r'\d\d\D\d\d', r'Телефон 1231212')
print(match.group(0) if match else 'Not found')
# -> Not found
match = re.fullmatch(r'\d\d\D\d\d', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'\d\d\D\d\d', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'\W+', 'Где, скажите мне, мои очки??!'))
# ->
print(re.findall(r'\d\d\.\d\d\.\d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# ->
for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m.group(0), 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'\d\d\.\d\d\.\d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ()
Так как символ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида .
Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также.
В результате с точки зрения питона означает просто два слеша .
Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй.
Тем самым как шаблон для регулярки означает просто текст .
Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ , что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)».
Соответственно можно будет писать .
Использование дополнительных флагов в питоне
| Константа | Её смысл |
|---|---|
| По умолчанию , , , , , , , соответствуют все юникодные символы с соответствующим качеством. Например, соответствуют не только арабские цифры, но и вот такие: ٠١٢٣٤٥٦٧٨٩. ускоряет работу, если все соответствия лежат внутри ASCII. | |
| Не различать заглавные и маленькие буквы. Работает медленнее, но иногда удобно | |
| Специальные символы и соответствуют началу и концу каждой строки | |
| По умолчанию символ конца строки не подходит под точку. С этим флагом точка — вообще любой символ |
Dot metacharacter
The dot (.) metacharacter stands for any single character in the text.
dot_meta.py
#!/usr/bin/env python
import re
words = ('seven', 'even', 'prevent', 'revenge', 'maven',
'eleven', 'amen', 'event')
pattern = re.compile(r'.even')
for word in words:
if re.match(pattern, word):
print(f'The {word} matches')
In the example, we have a tuple with eight words. We apply a pattern
containing the dot metacharacter on each of the words.
pattern = re.compile(r'.even')
The dot stands for any single character in the text. The character must
be present.
$ ./dot_meta.py The seven matches The revenge matches
Two words match the pattern: seven and revenge.
Ответы
- В данном случае будет выведена строка ‘Spam’, потому что функция обращается к глобальной переменной в объемлющем модуле (если внутри функции переменной не присваивается значение, она интерпретируется как глобальная).
- В данном случае снова будет выведена строка ‘Spam’, потому что операция присваивания внутри функции создает локальную переменную и тем самым скрывает глобальную переменную с тем же именем. Инструкция print находит неизмененную переменную в глобальной области видимости.
- Будет выведена последовательность символов ‘Ni’ в одной строке и ‘Spam’ — в другой, потому что внутри функции инструкция print найдет локальную переменную, а за ее пределами – глобальную.
- На этот раз будет выведена строка ‘Ni’, потому что объявление global предписывает выполнять присваивание внутри функции переменной, находящейся в глобальной области видимости объемлющего модуля.
- В этом случае снова будет выведена последовательность символов ‘Ni’ в одной строке и ‘Spam’ – в другой, потому что инструкция print во вложенной функции отыщет имя в локальной области видимости объемлющей
функции, а инструкция print в конце фрагмента отыщет имя в глобальной области видимости. - Этот фрагмент выведет строку ‘Spam’, так как инструкция nonlocal (доступная в Python 3.0, но не в 2.6) означает, что операция присваивания внутри вложенной функции изменит переменную X в локальной области видимости объемлющей функции. Без этой инструкции операция присваивания классифицировала бы переменную X как локальную для вложенной функции и создала бы совершенно другую переменную — в этом случае приведенный
фрагмент вывел бы строку ‘NI’. - Поскольку значения локальных переменных исчезают, когда функция возвращает управление, то информацию о состоянии в языке Python можно сохранять в глобальных переменных, для вложенных функций — в области
видимости объемлющих функций, а также посредством аргументов со значениями по умолчанию. Иногда можно использовать прием, основанный на сохранении информации в атрибутах, присоединяемых к функциям,
вместо использования области видимости объемлющей функции. Альтернативный способ заключается в использовании классов и приемов ООП, который обеспечивает лучшую поддержку возможности сохранения ин-
формации о состоянии, чем любой из предыдущих приемов, основанных на использовании областей видимости, потому что этот способ делает сохранение явным, позволяя выполнять присваивание значений атрибутам.
Python 3 курс
Python3 курсPython3 Базовая грамматикаPython3 Основные типы данныхPython3 переводчикPython3 примечаниеPython3 операторыPython3 цифровойPython3 строкаPython3 списокPython3 КортежPython3 словарьPython3 Первый шаг в программированииPython3 условия контроляPython3 LoopsPython3 Итераторы и генераторыPython3 функцияPython3 структура данныхPython3 модульPython3 Ввод и выводPython3 FilePython3 OSPython3 Ошибки и исключенияPython3 Объектно-ориентированныйPython3 Стандартная библиотека ОбзорPython3 примеровPython3 Регулярные выраженияPython3 CGIпрограммаPython3 MySQLPython3 Сетевое программированиеPython3 SMTPОтправить по электронной почтеPython3 МногопоточностьPython3 XMLрешениеPython3 JSONPython3 Дата и время
Specify Pattern Using RegEx
To specify regular expressions, metacharacters are used. In the above example, and are metacharacters.
MetaCharacters
Metacharacters are characters that are interpreted in a special way by a RegEx engine. Here’s a list of metacharacters:
[] . ^ $ * + ? {} () \ |
— Square brackets
Square brackets specifies a set of characters you wish to match.
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| 2 matches | ||
| No match | ||
| 5 matches |
Here, will match if the string you are trying to match contains any of the , or .
You can also specify a range of characters using inside square brackets.
- is the same as .
- is the same as .
- is the same as .
You can complement (invert) the character set by using caret symbol at the start of a square-bracket.
- means any character except a or b or c.
- means any non-digit character.
— Period
A period matches any single character (except newline ).
| Expression | String | Matched? |
|---|---|---|
| No match | ||
| 1 match | ||
| 1 match | ||
| 2 matches (contains 4 characters) |
— Caret
The caret symbol is used to check if a string starts with a certain character.
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| 1 match | ||
| No match | ||
| 1 match | ||
| No match (starts with but not followed by ) |
— Dollar
The dollar symbol is used to check if a string ends with a certain character.
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| 1 match | ||
| No match |
— Star
The star symbol matches zero or more occurrences of the pattern left to it.
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| 1 match | ||
| 1 match | ||
| No match ( is not followed by ) | ||
| 1 match |
— Plus
The plus symbol matches one or more occurrences of the pattern left to it.
| Expression | String | Matched? |
|---|---|---|
| No match (no character) | ||
| 1 match | ||
| 1 match | ||
| No match (a is not followed by n) | ||
| 1 match |
— Question Mark
The question mark symbol matches zero or one occurrence of the pattern left to it.
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| 1 match | ||
| No match (more than one character) | ||
| No match (a is not followed by n) | ||
| 1 match |
— Braces
Consider this code: . This means at least n, and at most m repetitions of the pattern left to it.




| Expression | String | Matched? |
|---|---|---|
| No match | ||
| 1 match (at ) | ||
| 2 matches (at and ) | ||
| 2 matches (at and ) |
Let’s try one more example. This RegEx matches at least 2 digits but not more than 4 digits
| Expression | String | Matched? |
|---|---|---|
| 1 match (match at ) | ||
| 3 matches (, , ) | ||
| No match |
— Alternation
Vertical bar is used for alternation ( operator).
| Expression | String | Matched? |
|---|---|---|
| No match | ||
| 1 match (match at ) | ||
| 3 matches (at ) |
Here, match any string that contains either a or b
— Group
Parentheses is used to group sub-patterns. For example, match any string that matches either a or b or c followed by xz
| Expression | String | Matched? |
|---|---|---|
| No match | ||
| 1 match (match at ) | ||
| 2 matches (at ) |
— Backslash
Backlash is used to escape various characters including all metacharacters. For example,
match if a string contains followed by . Here, is not interpreted by a RegEx engine in a special way.
If you are unsure if a character has special meaning or not, you can put in front of it. This makes sure the character is not treated in a special way.
Special Sequences
Special sequences make commonly used patterns easier to write. Here’s a list of special sequences:
— Matches if the specified characters are at the start of a string.
| Expression | String | Matched? |
|---|---|---|
| Match | ||
| No match |
— Matches if the specified characters are at the beginning or end of a word.
| Expression | String | Matched? |
|---|---|---|
| Match | ||
| Match | ||
| No match | ||
| Match | ||
| Match | ||
| No match |
— Opposite of . Matches if the specified characters are not at the beginning or end of a word.
| Expression | String | Matched? |
|---|---|---|
| No match | ||
| No match | ||
| Match | ||
| No match | ||
| No match | ||
| Match |
— Matches any decimal digit. Equivalent to
| Expression | String | Matched? |
|---|---|---|
| 3 matches (at ) | ||
| No match |
— Matches any non-decimal digit. Equivalent to
| Expression | String | Matched? |
|---|---|---|
| 3 matches (at ) | ||
| No match |
— Matches where a string contains any whitespace character. Equivalent to .
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| No match |
— Matches where a string contains any non-whitespace character. Equivalent to .
| Expression | String | Matched? |
|---|---|---|
| 2 matches (at ) | ||
| No match |
— Matches any alphanumeric character (digits and alphabets). Equivalent to . By the way, underscore is also considered an alphanumeric character.
| Expression | String | Matched? |
|---|---|---|
| 3 matches (at ) | ||
| No match |
— Matches any non-alphanumeric character. Equivalent to
| Expression | String | Matched? |
|---|---|---|
| 1 match (at ) | ||
| No match |
— Matches if the specified characters are at the end of a string.
| Expression | String | Matched? |
|---|---|---|
| 1 match | ||
| No match | ||
| No match |
Tip: To build and test regular expressions, you can use RegEx tester tools such as regex101. This tool not only helps you in creating regular expressions, but it also helps you learn it.
Now you understand the basics of RegEx, let’s discuss how to use RegEx in your Python code.
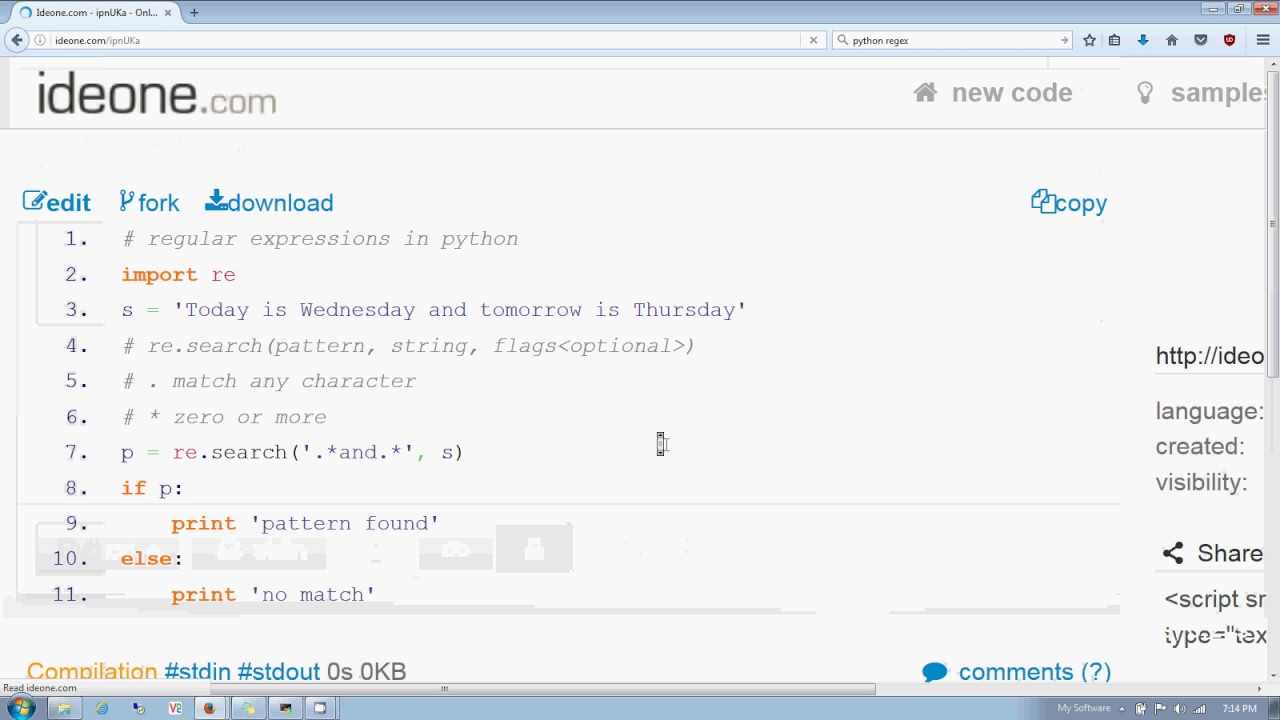
re.search метод
re.search сканировать всю строку и возвращает первый успешный матч.
Синтаксис функции:
re.search(pattern, string, flags=0)
Параметры функции:
| параметры | описание |
|---|---|
| шаблон | Матч регулярное выражение |
| строка | Строка для соответствия. |
| флаги | Флаг, регулярное выражение соответствия используется для управления, например: соответствует ли чувствительны к регистру, многострочный, и так далее. |
Успешный метод матча re.search возвращает объект соответствия, в противном случае None.
Мы можем использовать эту группу (NUM) или группы () функцию, чтобы получить объекты, соответствующие выражения совпадают.
| Соответствующие методы объекта | описание |
|---|---|
| группа (Num = 0) | Весь соответствующий строковое выражение, группа () может ввести более одного номера группы, в этом случае он будет возвращать значение, соответствующее этим группам кортежей. |
| группы () | Он возвращает кортеж из всех групп строки, от 1 до количества, содержащегося в группе. |
Пример 1:
#!/usr/bin/python3
import re
print(re.search('www', 'www.w3big.com').span()) # 在起始位置匹配
print(re.search('com', 'www.w3big.com').span()) # 不在起始位置匹配
Запуск в приведенном выше примере выход:
(0, 3) (11, 14)
Пример 2:
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")
searchObj.group() : Cats are smarter than dogs searchObj.group(1) : Cats searchObj.group(2) : smarter