
Установка
Unix и Linux
Чтобы установить Perl в Unix/Linux системе, необходимо выполнить несколько простых шагов:
- Найти ссылку на архив с исходным кодом Perl для Unix/Linux
- Скачать perl-5.x.y.tar.gz и выполнить в терминале следующие команды
$ tar -xzf perl-5.x.y.tar.gz $ cd perl-5.x.y $ ./Configure -de $ make $ make test $ make install
После этого Perl будет установлен в стандартную директорию /usr/local/bin, а его библиотеки будут установлены в /usr/local/lib/perlXX, где XX — версия Perl, которую вы используете.
Windows
Вот как можно установить Perl на Windows
- Скачать 32bit или 64bit версию инсталятора.
- Запустить инсталятор, щелкнув по нему дважды в Windows Explorer. После этого запустится программа установки Perl.
- Выберите стандартный способ установки и подождите, пока установка завершится.
Macitosh
Чтобы собрать свою собственную версию Perl, вам понадобится утилита ‘make’, которая является часть инструментов разработчика Apple, поставляемых на DVD вместе с Mac OS. Вам не понадобится последняя версия Xcode, чтобы установит make.
Выполите эти простые шаги, чтобы установит Perl в Max OS X
- Найти ссылку на архив с исходным кодом Perl для Mac OS X
- Скачать perl-5.x.y.tar.gz и выполнить в терминале следующие команды
$ tar -xzf perl-5.x.y.tar.gz $ cd perl-5.x.y $ ./Configure -de $ make $ make test $ make install
После этого Perl будет установлен в стандартную директорию /usr/local/bin, а его библиотеки будут установлены в /usr/local/lib/perlXX, где XX — версия Perl, которую вы используете.
Хэши — переменные и литералы
В программе хэш представляется в виде переменной, имеющей тип хэша, которая записывается с разыменовывающим префиксом % перед именем. Этот префикс обозначает, что это переменная-хэш, в которой хранится набор ассоциативных связей, иначе говоря, пар «ключ — значение»:
Листинг %hash # переменная-хэш
Непосредственные величины ключей и значений хэша могут быть представлены в виде списочного литерала, который записывается как список в круглых скобках, состоящий из элементов хэша. Каждый элемент в литерале состоит из двух частей: поискового ключа и связанного с ним значения, разделенных символами =>, например:
Листинг
('версия' => 5.8, 'язык' => 'Perl') # ключ - строка
(3.14 => 'число Пи') # ключ - дробь
(1 => 'one', 2 => 'two', 3 => 'three') # ключ - целое
($key1 => $value1, $key2 => $value2) # ключ в переменной
Операция эквивалентна запятой, за исключением того, что она создает строковый контекст, так что ее левый операнд автоматически преобразуется к строке. Именно поэтому числа в этом примере записаны без кавычек. Литеральные списки, содержащие ассоциативные пары, обычно применяются для присваивания хэшам начальных значений:
Листинг %quarter1 = (1 => 'январь', 2 => 'февраль', 3 => 'март'); %dns = ($site => $ip, 'www.perl.com' => '208.201.239.36'); %empty = (); # пустой список удаляет все элементы хэша
Если в качестве ключа хэша используется переменная с неопределенным значением, то оно преобразуется в пустую строку, которая и станет поисковым ключом. Значения ключей в хэше уникальны, поэтому хэш часто используется для моделирования множества или простой базы данных с уникальным поисковым индексом. При добавлении нескольких элементов с одинаковыми ключами в хэше остается только последний добавленный:
Листинг %num2word = (10 => 'десять', 5 => 'пять', 10 => 'ten'); # в %num2word останется только (5 => 'пять', 10 => 'ten')
Ситуация, когда с поисковым ключом хэша ассоциируется неопределенное значение, считается нормальной. Это чаще всего означает, что связанное с ключом значение будет добавлено позднее.
Начальные значения элементов хэша могут браться из любого списка, при этом значения нечетных элементов списка становятся в хэше ключами, а четных — ассоциированными с этими ключами значениями. Так что два следующих присваивания эквивалентны:
Листинг
%dictionary = ('я' => 'I', 'он' => 'he', 'она' => 'she');
%dictionary = ('я', 'I', 'он', 'he', 'она', 'she');
И конечно, для заполнения хэша элементами вместо списочного литерала можно использовать массив, содержащий пары «ключ — значение»:
Листинг %dictionary = @list_of_key_value_pairs; # массив пар
В повседневной работе хэш заполняется данными из списка, который считывается из файла или генерируется при помощи пользовательской функции.
Следует иметь в виду, что, в отличие от массивов, элементы в хэше не упорядочены, и порядок следования элементов при добавлении элементов в хэш и при выборке их из хэша обычно не совпадает. Все значения, хранящиеся в хэше, можно преобразовать в список, если употребить переменную-хэш в списочном контексте в правой части операции присваивания. Вот так:
Листинг @key_value_list = %hash; # список ключей и значений
При этом в список будут помещены все ассоциативные пары из хэша, и ключи станут нечетными элементами списка, а значения — четными. Порядок копирования в массив ассоциативных пар заранее не известен.
Perl access array elements
In the next example, we access array elements.
accessing.pl
#!/usr/bin/perl use 5.30.0; use warnings; my @vals = (11, 12, 13, 14, 15, 16); say $vals; say $vals; say $vals; say $vals; say '-----------------------'; say scalar @vals; say $#vals; say '-----------------------'; say $vals;
Array elements are access by their indexes. The first index has value 0. The
last index is . Array elements can be accessed from the end
by using negative indexes.
say $vals; say $vals; say $vals; say $vals;
We print the values of four elements. The first value has index 0, the second 1.
The last has index -1 and the last but one -2. The indexes are place between
characters and the variable name is preceded with the
sigil.
say scalar @vals; say $#vals;
We print the number of elements with the function and the
last index value with .
$ ./accessing.pl 11 12 16 15 ----------------------- 6 5 ----------------------- 16
Постоянное хранение
Многим программам, использующим ассоциативные массивы, в какой-то момент потребуется хранить эти данные в более постоянной форме, например, в компьютерный файл. Распространенным решением этой проблемы является обобщенная концепция, известная как архивирование или сериализация, который создает текстовое или двоичное представление исходных объектов, которое может быть записано непосредственно в файл. Чаще всего это реализуется в базовой объектной модели, такой как .Net или Cocoa, которая включает стандартные функции, преобразующие внутренние данные в текстовую форму. Программа может создать полное текстовое представление любой группы объектов, вызвав эти методы, которые почти всегда уже реализованы в базовом классе ассоциативных массивов.
Для программ, использующих очень большие наборы данных, такое хранилище отдельных файлов не подходит, и система управления базами данных (DB) не требуется. Некоторые системы БД изначально хранят ассоциативные массивы, сериализуя данные, а затем сохраняя эти сериализованные данные и ключ. Затем отдельные массивы могут быть загружены или сохранены из базы данных с помощью ключа для ссылки на них. Эти хранилища «ключ-значение» использовались в течение многих лет и имеют такую же долгую историю, как более распространенные реляционная база данных (RDB), но отсутствие стандартизации, среди прочего, ограничивало их использование определенными нишевыми ролями. Для этих ролей в большинстве случаев использовались RDB, хотя сохранение объектов в RDB может быть сложной задачей, известной как объектно-относительное рассогласование импеданса.
После c. 2010, потребность в высокопроизводительных базах данных, подходящих для облачные вычисления а более точное соответствие внутренней структуры программ, использующих их, привело к возрождению рынка магазинов «ключ-значение». Эти системы могут хранить и извлекать ассоциативные массивы естественным образом, что может значительно повысить производительность в обычных рабочих процессах, связанных с Интернетом.
Операции со структурами данных
Чтобы манипулировать сохраненными данными, необходимо выполнить с ними определенные операции. Каждая из этих операций является общепринятой и специфически настроенной. Рассмотрим некоторые из них:
- Обход (Traversing): получение доступа к каждому элементу данных в структуре ровно один раз и его обработка. Таким образом вы переходите прямо к элементу в СД.
- Вставка (Insertion): добавление другого элемента в СД. Вставка имеет определенное имя в зависимости от СД, например, в стеке — , в очереди — .
- Удаление (Deletion): выведение элемента из СД. В стеке — , в очереди — .
- Поиск (Searching): обнаружение определенного элемента в СД, проверка его наличия или отсутствия. Это часто используемая операция.
- Доступ (Access): получение значения элемента, фактическое местоположение которого известно.
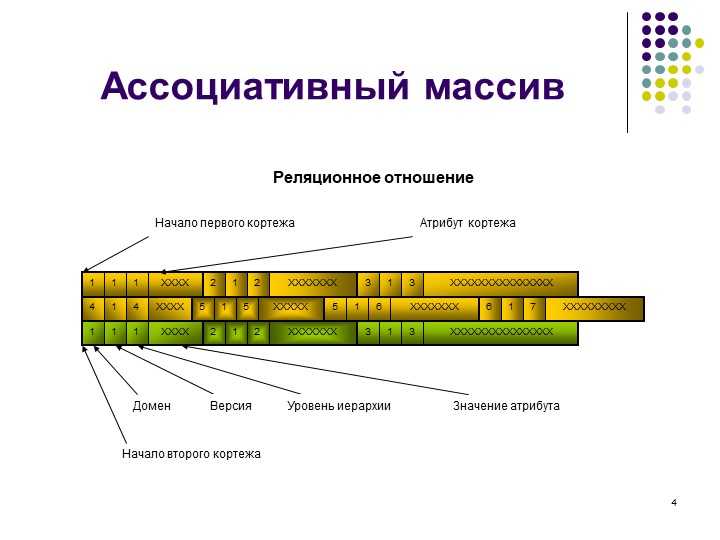
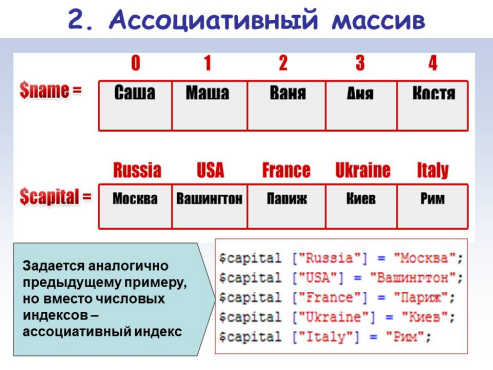
Ассоциации и хэши
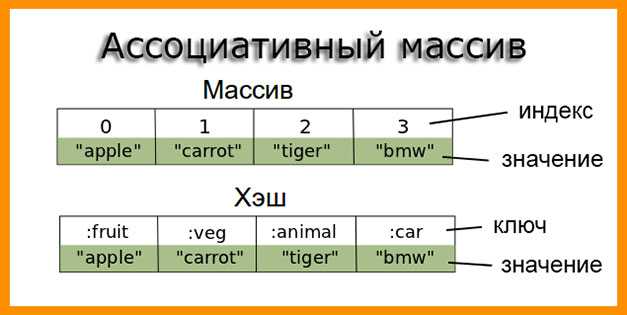
В программировании ассоциативные связи являются одним из основных видов связей между информационными объектами наряду с наследованием (связями типа «предок-потомок») и агрегацией (связями типа «часть-целое»). Ассоциации позволяют устанавливать необходимые логические связи между сущностями по избранному программистом критерию. Ассоциативная связь подобна стрелке на схеме, направленной от одного объекта к другому. Часто ассоциации используются для нахождения по заданной величине соответствующего значения. В этом случае две части ассоциативной связи соответственно называют поисковым ключом (key) и значением (value), ассоциированным с этим ключом. На этом принципе основана классическая структура данных, называемая словарем (dictionary).
В языке Perl для выражения ассоциаций имеются ассоциативные массивы или хэш-таблицы, которые для краткости принято называть хэшами. Хэш (hash) представляет из себя набор ассоциативных связей. Ключом хэша может быть любая скалярная величина: строка, ссылка, целое или дробное число, автоматически преобразуемое в строку. Причем значения всех ключей в хэше уникальны, поскольку внутренняя организация хэша не допускает ключей с одинаковыми значениями. Ассоциированное с ключом значение может быть любой скалярной величиной. Хэши сочетают в себе ряд привлекательных качеств: гибкость, мощь, быстроту и удобство работы. Поэтому они весьма часто используются при программировании на Perl самых различных задач. С помощью хэшей можно моделировать понятия из математики, информатики, лингвистики и других областей знаний: множества, словари, фреймы, семантические сети, программные объекты и простые базы данных. Размер хэша в Perl ограничен только доступной программе памятью, поэтому хэши позволяют эффективно обрабатывать большие объемы данных, в которых требуется выполнять быстрый поиск. Примечательно то, что в других языках ассоциативные массивы реализованы в виде коллекций объектов в библиотечных модулях, а в языке Perl хэши встроены в ядро языка, что обеспечивает их максимально эффективную работу.
Специальные хэши
Исполняющая система Perl предоставляет программисту доступ к специальным ассоциативным массивам, в которых хранится полезная служебная информация. Вот некоторые из специальных хэшей:
Листинг %ENV перечень системных переменных окружения (например, PATH) %INC перечень внешних программ, подключаемых по require или do %SIG используется для установки обработчиков сигналов от процессов
Например, так при выполнении программы можно использовать значения переменных окружения: перечислить все их значения или выбрать нужные.
Листинг
foreach my $name (keys %ENV) { print "$name=$ENV{$name}\n"; }
($who, $home) = @ENV{"USER", "HOME"}; # под Unix
($who, $home) = @ENV{"USERNAME", "HOMEPATH"}; # и Windows XP
пример
Предположим, что набор кредитов, предоставленных библиотекой, представлен в структуре данных. Каждую книгу в библиотеке может проверять только один посетитель библиотеки одновременно. Однако один посетитель может проверить несколько книг. Таким образом, информация о том, какие книги проверены для каких клиентов, может быть представлена ассоциативным массивом, в котором книги являются ключами, а посетители — значениями. Используя обозначения из Python или JSON, структура данных будет такой:


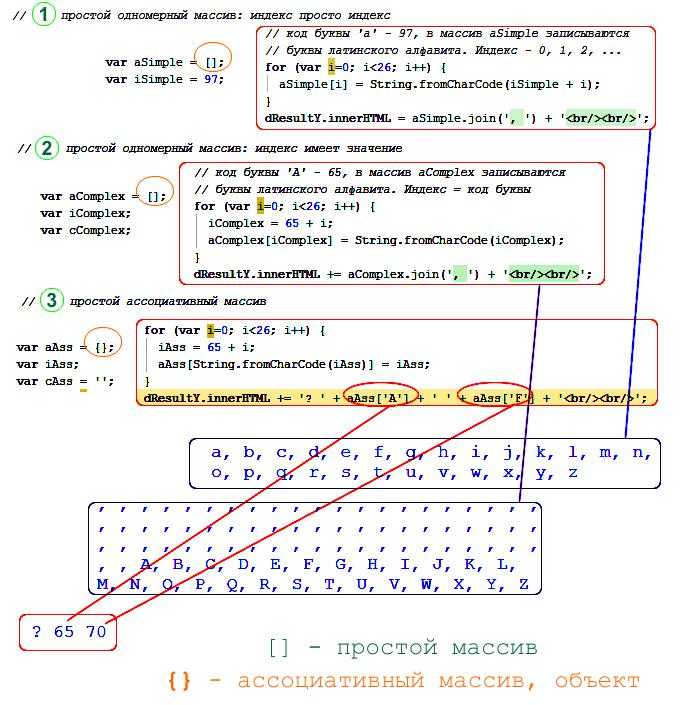





{ "Гордость и предубеждение" "Алиса", "Грозовой перевал" "Алиса", "Большие Надежды" "Джон"}
Операция поиска по ключу «Большие надежды» вернет «Джон». Если Джон вернет свою книгу, это вызовет операцию удаления, а если Пэт извлечет книгу, это вызовет операцию вставки, что приведет к другому состоянию:
{ "Гордость и предубеждение" "Алиса", "Братья Карамазовы" "Пэт", "Грозовой перевал" "Алиса"}
Хэши и списки
Так как весь хэш, его ключи или значения можно легко преобразовать в список, то для обработки хэшей можно применять любые функции, работающие со списками. Именно поэтому в предыдущем примере была применена функция . Например, вывести ключи и значения хэша на печать можно так:
Листинг
{ # организовать блок, где объявить временный массив
my @temp = %hash; # сохранить в нем хэш
print "@temp"; # и передать его функции print
} # по выходе из блока временный массив будет уничтожен
Можно напечатать хэш по-другому, построчно и в более облагороженном виде, при помощи функции map, которая также выполняет роль итератора:
Листинг
print map {"Ключ: $_ значение: $hash{$_}\n" } keys %hash;
В этом примере на основании списка ключей, возвращенного функцией , функция map формирует список нужных строк, вставляя из хэша в каждую из них ключ и значение. Она возвращает сформированный список функции , которая выводит его в выходной поток. Кстати, это типичный для Perl прием — обрабатывать данные при помощи цепочки функций, когда результат работы одной функции передается на обработку другой, как это принято делать с помощью конвейеров команд в операционных системах семейства Unix.
В приведенных выше примерах при необходимости обработки ключей хэша в алфавитном порядке они сортировались с помощью функции . Вот пример обработки хэша в порядке возрастания не его ключей, а его значений:
Листинг
foreach $key ( # каждый элемент списка,
sort # отсортированный по порядку
{$hash{$a} cmp $hash{$b}}# значений, ассоциированных
keys %hash) { # с ключами хэша
print "значение:$hash{$key} ключ:$key\n"; # обработать
} # в цикле
Здесь в блоке сравнения функции сопоставляется значения хэша, ассоциированные с очередными двумя ключами из списка, который предоставлен функцией .
Операции
В ассоциативном массиве связь между ключ и значение часто называют «отображением», и то же словесное отображение может также использоваться для обозначения процесса создания новой ассоциации.
Для ассоциативного массива обычно определяются следующие операции:
- Добавить или вставить: добавить новый (kеу,vалтые){ displaystyle (ключ, значение)} пара в коллекцию, сопоставляя новый ключ с его новым значением. Аргументами этой операции являются ключ и значение.
- Переназначить: заменить значение в одном из (kеу,vалтые){ displaystyle (ключ, значение)} пары, которые уже находятся в коллекции, отображая существующий ключ на новое значение. Как и при вставке, аргументами этой операции являются ключ и значение.
- удалять или Удалить: удалить (kеу,vалтые){ displaystyle (ключ, значение)} пара из коллекции, отключив данный ключ от его значения. Аргумент этой операции — это ключ.
- Искать: найти значение (если есть), связанное с данным ключом. Аргументом этой операции является ключ, а значение возвращается из операции. Если значение не найдено, некоторые реализации ассоциативного массива вызывают исключение, в то время как другие создают пару с данным ключом и значением по умолчанию для типа значения (ноль, пустой контейнер …).
Часто вместо добавления или переназначения используется один набор операция, которая добавляет новый (kеу,vалтые){ displaystyle (ключ, значение)} пара, если он еще не существует, в противном случае переназначает его.
Кроме того, ассоциативные массивы могут также включать в себя другие операции, такие как определение количества сопоставлений или построение итератор чтобы перебрать все сопоставления. Обычно для такой операции порядок, в котором возвращаются сопоставления, может определяться реализацией.
А Multimap обобщает ассоциативный массив, позволяя связывать несколько значений с одним ключом. А двунаправленная карта — это связанный абстрактный тип данных, в котором сопоставления действуют в обоих направлениях: каждое значение должно быть связано с уникальным ключом, а вторая операция поиска принимает значение в качестве аргумента и ищет ключ, связанный с этим значением.
Языковая поддержка
Ассоциативные массивы могут быть реализованы на любом языке программирования в виде пакета, и многие языковые системы предоставляют их как часть своей стандартной библиотеки. В некоторых языках они не только встроены в стандартную систему, но и имеют специальный синтаксис, часто использующий индексы типа массивов.
Встроенная синтаксическая поддержка ассоциативных массивов была представлена в 1969 г. СНОБОЛ4, под названием «таблица». TMG предлагает таблицы со строковыми ключами и целочисленными значениями. МАМПЫ сделаны многомерные ассоциативные массивы, опционально постоянные, его ключевые структуры данных. SETL поддержал их как одну из возможных реализаций наборов и карт. Большинство современных языков сценариев, начиная с AWK и в том числе Rexx, Perl, Tcl, JavaScript, Клен, Python, Рубин, Язык Wolfram Language, Идти, и Lua, поддерживают ассоциативные массивы в качестве основного типа контейнера. На многих других языках они доступны как библиотечные функции без специального синтаксиса.
В Болтовня, Цель-C, .СЕТЬ,Python, REALbasic, Swift, VBA и Delphi они называются словари; в Perl, Рубин и Семя7 они называются хеши; в C ++, Ява, Идти, Clojure, Scala, OCaml, Haskell они называются карты (увидеть карта (C ++), unordered_map (C ++), и ); в Common Lisp и Windows PowerShell, они называются хеш-таблицы (поскольку оба обычно используют эту реализацию); в Клен и Lua они называются столы. В PHP, все массивы могут быть ассоциативными, за исключением того, что ключи ограничены целыми числами и строками. В JavaScript (см. Также JSON) все объекты ведут себя как ассоциативные массивы со строковыми ключами, тогда как типы Map и WeakMap принимают произвольные объекты в качестве ключей. В Lua они используются как примитивный строительный блок для всех структур данных. В Visual FoxPro, они называются Коллекции. В Язык D также поддерживает ассоциативные массивы.
Perl array filter
The function filters an array based on the given expression.
filtering.pl
#!/usr/bin/perl
use 5.30.0;
use warnings;
my @vals = (-1, 0, 2, 1, 5, -6, -2, 3, 4);
my @r1 = grep {$_ > 0} @vals;
say "@r1";
my @r2 = grep {$_ < 0} @vals;
say "@r2";
my @r3 = grep {$_ % 2 == 0} @vals;
say "@r3";
In the example, we filter a list of integer values.
my @r1 = grep {$_ > 0} @vals;
This line extracts positive integers.
my @r2 = grep {$_ < 0} @vals;
Here, we get all negative ones.
my @r3 = grep {$_ % 2 == 0} @vals;
In this line, we get all the even numbers.
$ ./filtering.pl 2 1 5 3 4 -1 -6 -2 0 2 -6 -2 4
In the next example, we use a regular expression for filtering.
filtering2.pl
#!/usr/bin/perl
use 5.30.0;
use warnings;
my @data = ('sky', 'new', 3, 'tool', 7, 'forest', 'cup', 'cloud', 5);
my @r1 = grep /\d/, @data;
say "@r1";
my @r2 = grep !/\d/, @data;
say "@r2";
We define an array of words and integers. We filter out first all integers and
then words.
$ ./filtering2.pl 3 7 5 sky new tool forest cup cloud
We further use regular expressions.
filtering3.pl
#!/usr/bin/perl use 5.30.0; use warnings; my @words = qw/sky new tool bar forest cup cloud tennis ball wood pen coffee/; my @r1 = grep /^...$/, @words; say "@r1"; my @r2 = grep /(\w)(\1+)/, @words; say "@r2";
First, we extract all three-letter words and then all the words with repeated
characters.
$ ./filtering3.pl sky new bar cup pen tool tennis ball wood coffee
The is a module for traversing directories.
filtering4.pl
#!/usr/bin/perl use 5.30.0; use warnings; use File::Find::Rule; $, = ' '; my @files = File::Find::Rule->name("*.pl")->in(".."); my @found = grep { -M $_ > 180 } @files; say join "\n", @found;
In the example, we find all Perl files that are older than 180 days. The
returns an array of found files.








In this tutorial, we have worked with arrays in Perl.
List .
Многомерные массивы
Многомерный массив каждый элемент в основном массиве также может быть массивом. И каждый элемент в sub-массиве может быть массивом и так далее. Значения в многомерном массиве доступны с использованием нескольких индексов.
Пример
В этом примере мы создаем двухмерный массив для хранения меток трех студентов по трем предметам. Этот пример представляет собой ассоциативный массив, вы можете создать числовой массив таким же образом.
<?php $marks = array( "mohammad" => array ( "physics" => 35, "maths" => 30, "chemistry" => 39 ), "qadir" => array ( "physics" => 30, "maths" => 32, "chemistry" => 29 ), "zara" => array ( "physics" => 31, "maths" => 22, "chemistry" => 39 ) ); /* Accessing multi-dimensional array values */ echo "Marks for mohammad in physics : " ; echo $marks . " "; echo "Marks for qadir in maths : "; echo $marks . " "; echo "Marks for zara in chemistry : " ; echo $marks . " "; ?>
Это приведет к следующему результату —
Новые статьи
- Ошибки в PHP и обработка исключений — 12/04/2018 19:21
- Регулярные выражения PHP -Кванторы, мета-символы и модификаторы — 12/04/2018 19:20
- Сеансы PHP — Запуск, уничтожение, сессии без файлов cookie — 12/04/2018 19:20
- PHP-файлы cookie — Настройка, доступ и удаление cookie — 12/04/2018 19:19
- Файлы PHP и ввод-вывод — открытие, чтение, запись и закрытие файла — 12/04/2018 19:18
- Методы PHP GET и POST, переменная $_REQUEST — 12/04/2018 19:17
- Загрузка файлов PHP — Создание формы и сценария загрузки — 12/04/2018 19:16
- Объектно-ориентированное программирование в PHP — 12/04/2018 19:15
- Включение файла в PHP — Функция include и require — 12/04/2018 19:14
- Предопределенные переменные PHP — Суперглобальные массивы и переменные сервера — 12/04/2018 19:13
- Функции с параметрами, динамические вызовы, создание функции в PHP — 12/04/2018 19:12
- Типы операторов PHP — категории, присваивания, логические операторы — 12/04/2018 19:11
- Типы циклов PHP for, foreach, continue, break, do-while — 12/04/2018 19:10
- Принятие решений PHP — ElseIf Switch — 12/04/2018 19:09
- Типы констант PHP — Различия между константами и переменными — 12/04/2018 19:08
Предыдущие статьи
- Типы переменных, область и имена переменных в PHP — 12/04/2018 19:06
- Строки в PHP, strpos, strlen, конкатенация строк — 12/04/2018 19:05
- Дата и время, получение, преобразование времени в PHP — 12/04/2018 19:03
- Обзор синтаксиса, канонические теги, комментирование PHP-кода — 12/04/2018 19:02
- Введение в PHP. Общее использование, характеристики PHP — 12/04/2018 19:01
Perl command line arguments
Perl stores command line arguments in a special variable .
cmd_argv.pl
#!/usr/bin/perl use 5.30.0; use warnings; use Data::Dumper qw(Dumper); die "Usage: $0 arg1 arg2 arg3\n" if @ARGV < 3; say $ARGV; say $ARGV; say Dumper \@ARGV;
In the example, we print two arguments and then the whole array with
.
die "Usage: $0 arg1 arg2 arg3\n" if @ARGV < 3;
We end the script with usage output if there are less than three arguments.
The variable refers to the program name. In this expression
(), the array is used in a scalar context and we
compare the number of elements in the array with value 3.
$ ./cmd_argv.pl 1 2 3 1 3 $VAR1 = ;
Perl array foreach loop
In a foreach loop, we run a block of code for each element of an array.
foreach_loop.pl
#!/usr/bin/perl
use 5.30.0;
use warnings;
my @vals = (1 .. 10);
$\ = ' ';
foreach my $val (@vals) {
print $val;
}
say "\n------------------------";
foreach (@vals) {
print $_;
}
$\ = '';
print "\n";
We use the loop to go through the elements of an array of
integers.
foreach my $val (@vals) {
print $val;
}
In each iteration, the current value is stored in the temporary
variable.
foreach (@vals) {
print $_;
}
If we omit the auxiliary variable, the current value is stored in the special
variable.
$ ./foreach_loop.pl 1 2 3 4 5 6 7 8 9 10 ------------------------ 1 2 3 4 5 6 7 8 9 10
If the temporary variable is omitted, the loop is a synonym
for .
for_foreach.pl
#!/usr/bin/perl
use 5.30.0;
use warnings;
my @vals = (1 .. 10);
$\ = ' ';
foreach (@vals) {
print $_;
}
say "\n--------------------------";
for (@vals) {
print $_;
}
$\ = '';
print "\n";
In this example, the and loops are
identical.
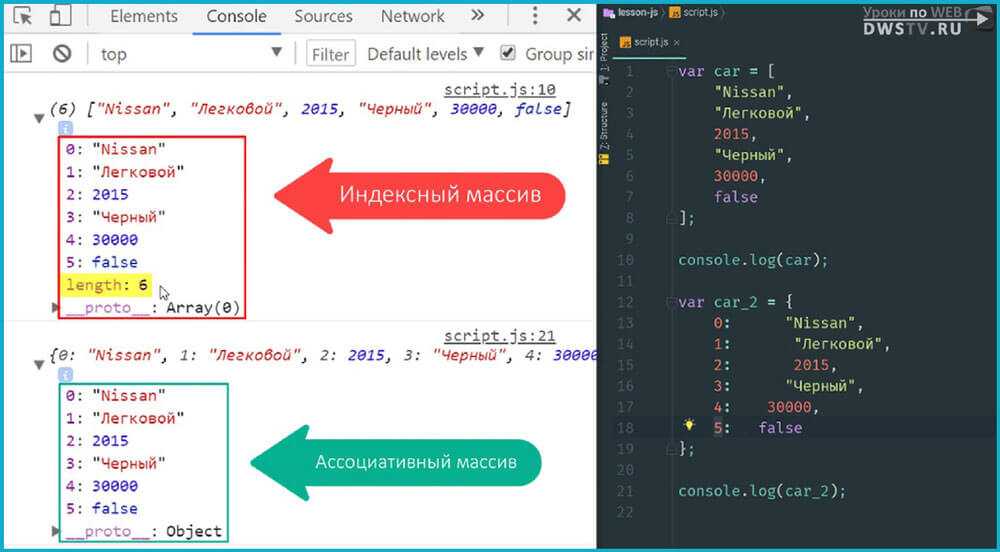
Ассоциативный JavaScript-массив как объект
В виде ассоциативного массива мы можем использовать и объект.
Для создания пустого ассоциативного массива (объекта) нам подойдёт один из следующих вариантов:
// с помощью литерала объекта
var arr = {};
// с помощью стандартной функции-конструктора Object
var arr = new Object();
// с помощью Object.create
var arr = new Object.create(null);
Чтобы заполнить ассоциативный массив в момент его создания, поступаем следующим образом:
var myArray = {
"ключ1" "значение1"
,"ключ2" "значение2"
, ... }
Теперь добавим в наш ассоциативный массив элемент (пару «ключ-значение»):
// добавляем в массив arr строку «текстовое значение», которое связано с ключом «key1» arr"key1" = "текстовое значение" // добавляем в массив число 22, которое связано с ключом «key2» arr"key2" = 22;
Обратите внимание, что добавление элемента в JavaScript-массив выполнится лишь тогда, когда данного ключа в нём нет. Если ключ уже имеется, то выражение лишь поменяет значение уже существующего ключа
В роли значения ключа мы можем использовать любой тип данных, включая объекты.
Стоит добавить, что в JavaScript кроме записи с квадратными скобками мы можем использовать точку. Однако это доступно лишь для ключей, имена которых соответствуют правилам именования переменных.
arr.key1 = "текстовое значение" arr.key2 = 22;
Чтобы получить значение элемента по ключу, подойдёт следующий синтаксис:
myArray"key1"]; myArray"key2"]; myArray.key1; myArray.key2;
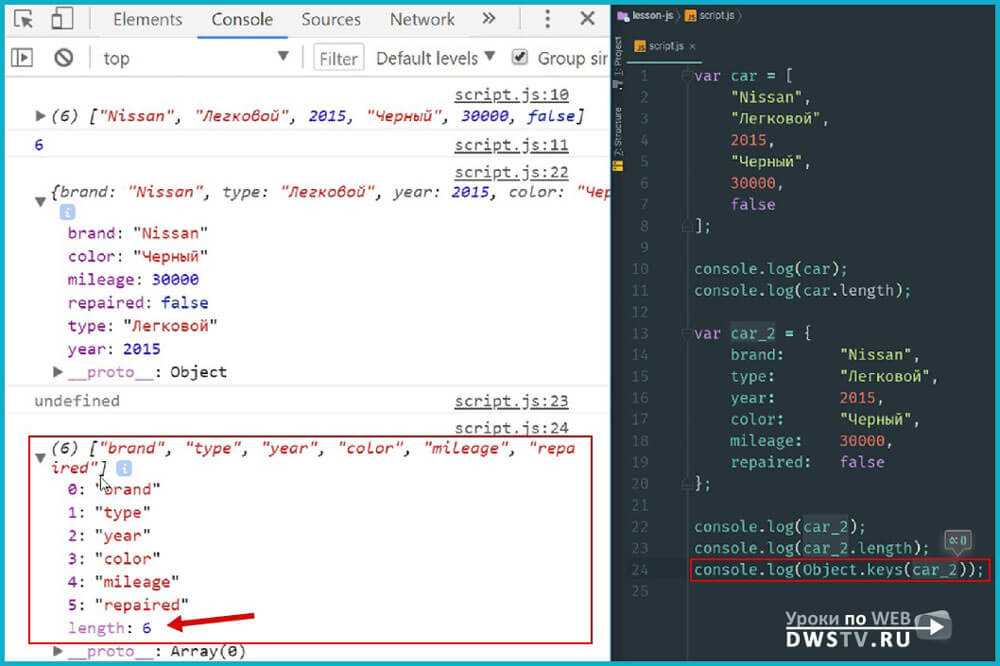
Чтобы получить число ключей (длину) ассоциативного массива, поступаем следующим образом:
var myArray = { "key1""value1", "key2""value2", "key3""value3"}
// 1 – получаем массив ключей посредством метода keys
// 2 - применяем свойство length, дабы узнать длину массива
Object.keys(myArray).length; // 3
Если надо удалить элемент из ассоциативного массива, применяем оператор delete.
delete myArray"key1"];
Когда нужно проверить, существует ли ключ в нашем ассоциативном массиве:
var myArray = {"key1""value1", "key2""value2" };
// 1 способ (задействуем метод hasOwnProperty)
if (myArray.hasOwnProperty("key1")) {
console.log("Ключ key1 есть!");
} else {
console.log("Ключ key1 не существует!");
}
// 2 способ
if ("key1" in myArray) {
console.log("Ключ key1 существует в массиве!");
} else {
console.log("Ключ key1 не существует в массиве!");
}
Если нужно перебрать элементы ассоциативного массива, подойдёт цикл for…in:

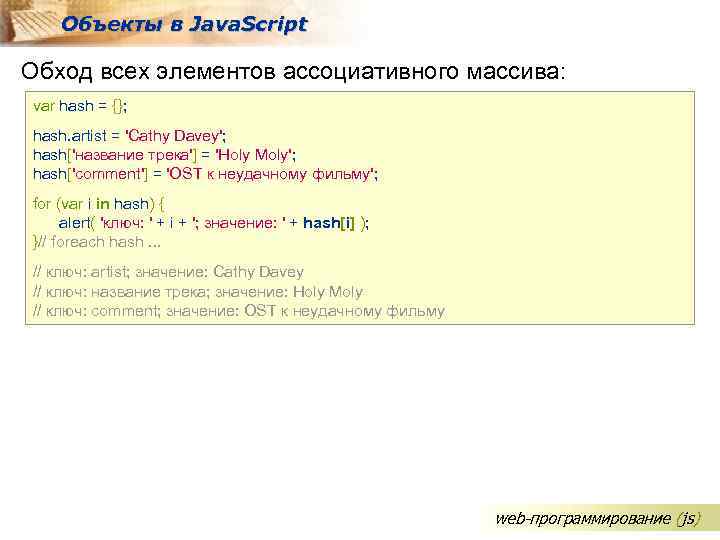
![Функция хеширования (хеширование) [реферат №4154]](https://luxe-host.ru/wp-content/uploads/0/d/5/0d59f0134c3dff214188f701a6167181.jpeg)



// myArray — ассоциативный массив
for(key in myArray) {
console.log(key + " = " + myArraykey]);
}
А чтобы преобразовать ассоциативный JavaScript-массив в JSON и назад, поступаем так:
// Ассоциативный массив (объект)
var myArr = {
key1 "value1",
key2 "value2",
key3 "value3"
};
// в JSON
jsonStr = JSON.stringify(myArr);
// из JSON в ассоциативный массив
arr = JSON.parse(jsonStr);
//получаем значение по ключу key1 (выводим в консоль)
console.log(arr.key1);
При написании статьи использовались материалы:
— «JavaScript — Ассоциативные массивы»;
— «Ассоциативный массив как объект»;
— «Настоящие ассоциативные массивы в JavaScript».
Perl array slice
A slice is a portion of an array. Slices can be created with the
range operator or the comma operator.
slices.pl
#!/usr/bin/perl use 5.30.0; use warnings; my @vals = (1 .. 10); $, = ' '; say @vals; say '--------------------'; my @sl1 = @vals; my @sl2 = @vals; my @sl3 = @vals; my @sl4 = @vals; say @sl1; say @sl2; say @sl3; say @sl4;
We create a couple of slices from an array of integers.
say @vals;
This slice contains elements with indexes 1, 2, and -1.
my @sl1 = @vals;
This slice has elements with indexes 1 through 4.
my @sl3 = @vals;
This slice has elements starting from 5 until the last element.
$ ./slices.pl 2 3 10 -------------------- 2 3 4 5 2 3 5 6 6 7 8 9 10 3 4 5 6 7
Perl курс
Perl курсPerl Краткое введениеPerl Установка по окружающей средеPerl Базовая грамматикаPerl Типы данныхPerl переменнаяPerl скаляруPerl массивPerl мешанинаPerl Условные операторыPerl циркуляцияPerl операторыPerl Дата и времяPerl подпрограмма(функция)Perl котировкаPerl форматированный выводPerl Операции с файламиPerl Операции СправочникPerl Обработка ошибокPerl Специальные переменныеPerl Регулярные выраженияPerl Отправить по электронной почтеPerl Socket программаPerl Объектно-ориентированныйPerl Связь с базами данныхPerl CGI программаPerl Пакеты и модулиPerl Управление процессами



