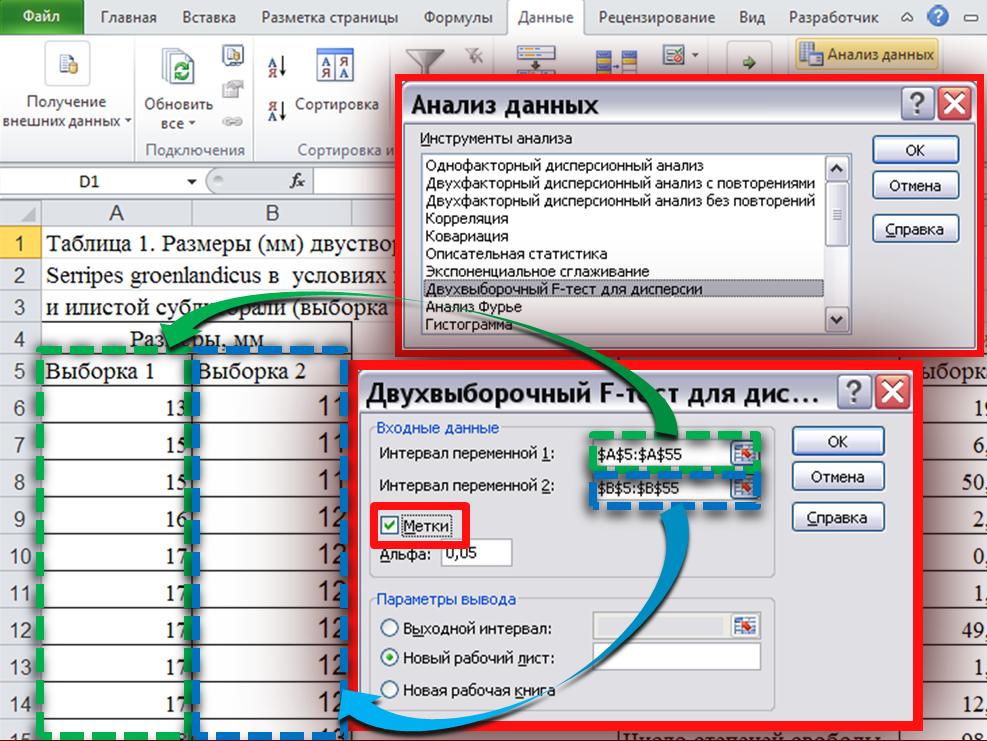
Оптимизация использования индексов
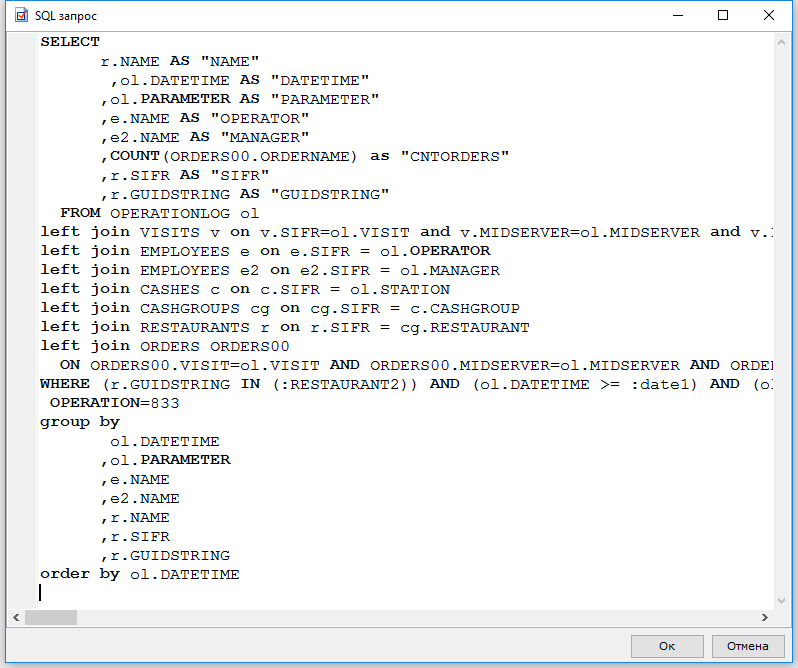
Как я уже говорил, MySQL может не использовать индексы, даже когда они присутствуют! Для примера возьмем ту же таблицу test2, и извлечем из нее все значения, у которых id > 1 (это 9998 записей), а затем все значения, у которых id > 123456 (это 0 записей):
mysql> EXPLAIN SELECT * FROM test2 WHERE id > 1; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | ALL | PRIMARY | NULL | NULL | NULL | 9999 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ mysql> EXPLAIN SELECT * FROM test2 WHERE id > 123456; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | range | PRIMARY | PRIMARY | 4 | NULL | 13 | Using where | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
В первом случае, индекс по полю id не используется. Во втором, MySQL заранее знает, что таких значений не более 13, и потому использует индекс (см. поле key). Но мы можем замедлить запрос, вызвав поиндексное сканирование таблицы при помощи инструкции FORCE INDEX(PRIMARY). Если в таблице имеется несколько индексов, можно указать любой из них. Для использования основного индекса, применяется служебное слово PRIMARY.
mysql> SELECT * FROM test2 WHERE id > 1; 9998 rows in set (0.08 sec) mysql> SELECT * FROM test2 FORCE INDEX(PRIMARY) WHERE id > 1; 9998 rows in set (0.23 sec)
А вот планы выполнения обоих запросов:
mysql> EXPLAIN SELECT * FROM test2 FORCE INDEX(PRIMARY) WHERE id > 1; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | range | PRIMARY | PRIMARY | 4 | NULL | 9998 | Using where | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ 1 row in set (0.00 sec) mysql> EXPLAIN SELECT * FROM test2 WHERE id > 1; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | test2 | ALL | PRIMARY | NULL | NULL | NULL | 9999 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec)
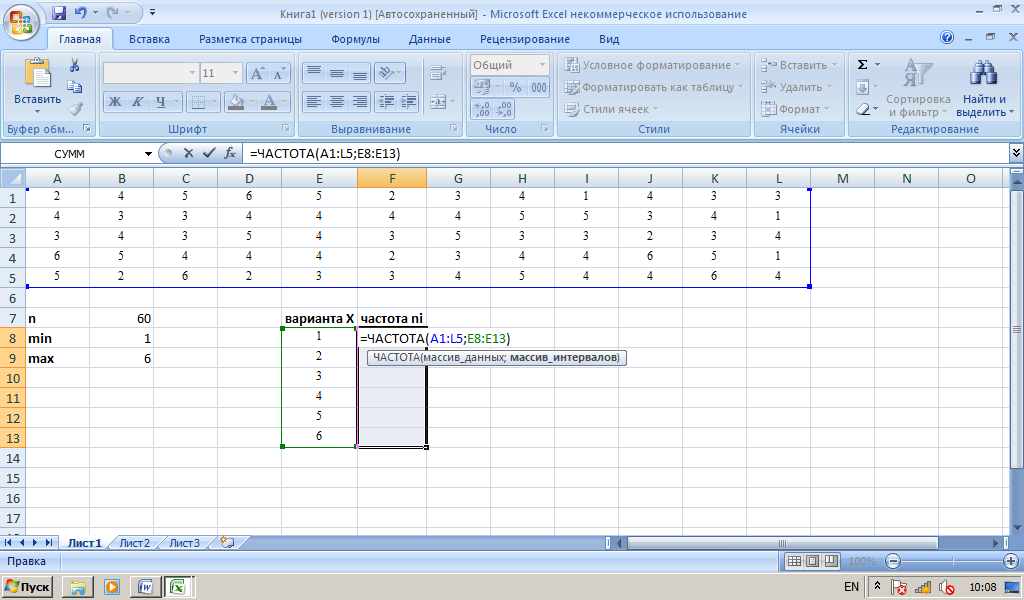
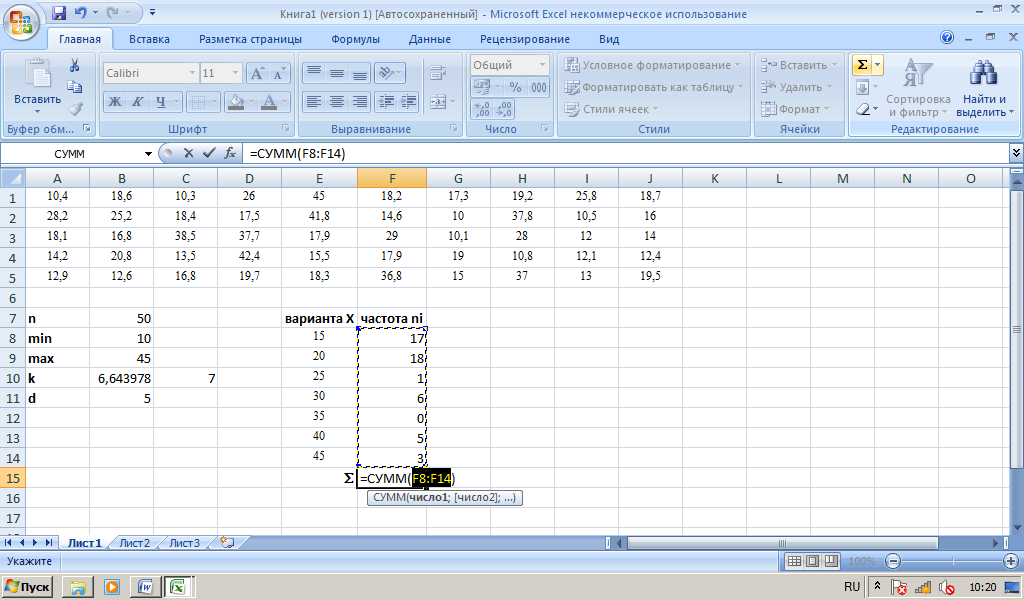
Также необходимо иметь ввиду, что база данных не будет использовать более одного индекса, и при помощи FORCE INDEX можно заставить ее использовать именно тот индекс, который нужен (если он определен неправильно). Для определения нужного индекса, используется максимально «уникальный» индекс. Узнать, какой из индексов максимально привлекателен, можно при помощи запроса SHOW KEYS FROM test2. Уникальность индекса характеризует столбец Cardinality.
SQL Working with Dates
You can compare two dates easily if there is no time component involved!
Assume we have the following «Orders» table:
| OrderId | ProductName | OrderDate |
|---|---|---|
| 1 | Geitost | 2008-11-11 |
| 2 | Camembert Pierrot | 2008-11-09 |
| 3 | Mozzarella di Giovanni | 2008-11-11 |
| 4 | Mascarpone Fabioli | 2008-10-29 |
Now we want to select the records with an OrderDate of «2008-11-11» from the table above.
We use the following SELECT statement:
SELECT * FROM Orders WHERE OrderDate=’2008-11-11′
The result-set will look like this:
| OrderId | ProductName | OrderDate |
|---|---|---|
| 1 | Geitost | 2008-11-11 |
| 3 | Mozzarella di Giovanni | 2008-11-11 |
Now, assume that the «Orders» table looks like this (notice the time component in the «OrderDate» column):
| OrderId | ProductName | OrderDate |
|---|---|---|
| 1 | Geitost | 2008-11-11 13:23:44 |
| 2 | Camembert Pierrot | 2008-11-09 15:45:21 |
| 3 | Mozzarella di Giovanni | 2008-11-11 11:12:01 |
| 4 | Mascarpone Fabioli | 2008-10-29 14:56:59 |
If we use the same SELECT statement as above:
SELECT * FROM Orders WHERE OrderDate=’2008-11-11′
we will get no result! This is because the query is looking only for dates with no time portion.
Tip: To keep your queries simple and easy to maintain, do not allow time components in your dates!
Создание новых событий MySQL
Создание события производится аналогично созданию других объектов базы данных: таких как хранимые процедуры и триггеры.
Событие представляет собой проименованный объект, который содержит состояние SQL.
Хранимая процедура выполняется только при прямом вызове; триггер выполняется, когда происходит событие, связанное с таблицей: например добавление, обновление, или удаление. В то время как само событие может выполняться один или несколько раз с регулярным интервалом.
Чтобы создать и запланировать новое событие, нужно использовать оператор CREATE EVENT следующим образом:
CREATE EVENT event_name ON SCHEDULE schedule DO event_body
Давайте рассмотрим этот оператор более подробно:
- Во-первых, после CREATE EVENT необходимо указать имя события. Оно должно быть уникальным в структуре базы данных;
- Во-вторых, после оператора ON SCHEDULE вы задаете график. Если событие является единичным, используется синтаксис: AT timestamp . Если событие периодическое, используется условие EVERY: EVERY interval STARTS timestamp ENDS timestamp ;
- В-третьих, вы размещаете оператор SQL после ключевого слова DO. Стоит отметить, что вы можете вызвать хранимую процедуру внутри тела события. В случае если у вас есть составные операторы SQL, вы можете заключить их в блок BEGIN END.
Давайте рассмотрим несколько примеров создания события, которые позволят лучше понять приведенный выше синтаксис.
Чтобы создать и запланировать новое одноразовое событие, которое добавляет сообщение в таблицу сообщений, нужно сделать следующее:
Во-первых, нужно с помощью оператора CREATE TABLE создать новую таблицу с именем messages:
CREATE TABLE IF NOT EXISTS messages (
id INT PRIMARY KEY AUTO_INCREMENT,
message VARCHAR(255) NOT NULL,
created_at DATETIME NOT NULL
);
Во-вторых, создаем событие с помощью оператора CREATE EVENT:
CREATE EVENT IF NOT EXISTS test_event_01
ON SCHEDULE AT CURRENT_TIMESTAMP
DO
INSERT INTO messages(message,created_at)
VALUES('Test MySQL Event 1',NOW());
В-третьих, проверяем таблицу messages. Вы увидите, что у нас есть одна запись. Это значит, что событие было выполнено во время его создания:



SELECT * FROM messages;
Для вывода всех событий базы данных, можно использовать следующий оператор:
SHOW EVENTS FROM classicmodels;
![]()
Мы видим, что нам не возвращается ни одна запись, потому что событие автоматически удаляется, когда истек его срок. В нашем случае это одноразовое событие, и его срок истек, когда его исполнение было завершено.
Чтобы изменить этот сценарий, вы можете использовать условие ON COMPLETION PRESERVE. Следующий оператор создает еще одно одиночное событие, которое выполняется спустя 1 минуту после его создания и не удаляется после выполнения:
CREATE EVENT test_event_02
ON SCHEDULE AT CURRENT_TIMESTAMP + INTERVAL 1 MINUTE
ON COMPLETION PRESERVE
DO
INSERT INTO messages(message,created_at)
VALUES('Test MySQL Event 2',NOW());
Спустя 1 минуту проверяем таблицу сообщений, и видим, что в нее была добавлена еще одна запись:
SELECT * FROM messages;
Если мы снова запустим на исполнение оператор SHOW EVENTS, то увидим, что события все еще хранятся в структуре базы данных, потому что мы использовали условие ON COMPLETION PRESERVE:
SHOW EVENTS FROM classicmodels;
![]()
Следующий оператор создает повторяющееся событие, которое выполняется каждую минуту, и срок которого истекает спустя 1 час после времени его создания:
CREATE EVENT test_event_03
ON SCHEDULE EVERY 1 MINUTE
STARTS CURRENT_TIMESTAMP
ENDS CURRENT_TIMESTAMP + INTERVAL 1 HOUR
DO
INSERT INTO messages(message,created_at)
VALUES('Test MySQL recurring Event',NOW());
Обратите внимание, что мы использовали операторы STARTS и ENDS, чтобы задать для события срок действия. Вы можете протестировать это повторяющееся событие, подождав несколько минут, а затем вновь проверив таблицу сообщений:
SELECT * FROM messages;
![]()
Как настроить условия задачи в планировщике задач
Помимо триггера, вы можете указать несколько условий для запуска задачи на основе прошедшего времени простоя, независимо от того, включен ли компьютер от сети переменного тока или доступна определенная сеть. Чтобы установить их, нажмите или коснитесь вкладки Условия
Обратите внимание, что если вы хотите создать задачу выключения, как мы, вам не нужно настраивать любое из этих условий
Если вы хотите, чтобы задача не мешала вашей работе, вы можете настроить ее выполнение только тогда, когда компьютер простаивает. Установите флажок «Запускать задачу, только если компьютер простаивает» и выберите один из доступных периодов. После того, как вы задали запуск задачи, вы можете подождать, пока компьютер перейдет в состояние ожидания в течение определенного периода, или вы можете выбрать «Не ждать в режиме ожидания». Когда компьютер больше не находится в режиме ожидания, вы можете решить остановить задачу или перезапустить ее, если состояние ожидания возобновится. Например, эти параметры простоя полезны, когда вы знаете, что для выполнения вашей задачи может потребоваться много системных ресурсов. Установка их для запуска, когда ваш компьютер или устройство находится в режиме ожидания, означает, что вы не будете беспокоиться о программах, которые работают медленно из-за этой задачи, поглощающей большую часть ресурсов вашего компьютера.
Поскольку задача может выполняться долго, планировщик задач позволяет вам задать условия для задачи, чтобы она запускалась только при питании компьютера от сети переменного тока, и останавливать задачу, если вы переключаетесь на питание от батареи. Если ваш компьютер находится в спящем режиме, и настало время запустить задачу, вы можете настроить компьютер на пробуждение и запуск задачи.
Если вы знаете, что вам нужно определенное сетевое соединение для запуска задачи, установите флажок «Запускать только при наличии следующего сетевого соединения» и выберите интересующее вас соединение.
Закрытие явного курсора
Когда-то в детстве нас учили прибирать за собой, и эта привычка осталась у нас (хотя и не у всех) на всю жизнь. Оказывается, это правило играет исключительно важную роль и в программировании, и особенно когда дело доходит до управления курсорами. Никогда не забывайте закрыть курсор, если он вам больше не нужен!






![Разработка расписания проекта [курсовая №37086]](https://luxe-host.ru/wp-content/uploads/7/2/0/7209c2ffba31054d0f23d81c12288d38.jpeg)
Синтаксис команды :
Ниже приводится несколько важных советов и соображений, связанных с закрытием явных курсоров.
- Если курсор объявлен и открыт в процедуре, не забудьте его закрыть после завершения работы с ним; в противном случае в вашем коде возникнет утечка памяти. Теоретически курсор (как и любая структура данных) должен автоматически закрываться и уничтожаться при выходе из области действия. Как правило, при выходе из процедуры, функции или анонимного блока действительно закрывает все открытые в нем курсоры. Но этот процесс связан с определенными затратами ресурсов, поэтому по соображениям эффективности иногда откладывает выявление и закрытие открытых курсоров. Курсоры типа по определению не могут быть закрыты неявно. Единственное, в чем можно быть уверенным, так это в том, что по завершении работы «самого внешнего» блока , когда управление будет возвращено или другой вызывающей программе, неявно закроет все открытые этим блоком или вложенными блоками курсоры, кроме. В статье «Cursor reuse in static » из Oracle Technology Network приводится подробный анализ того, как и когда закрывает курсоры. Вложенные анонимные блоки — пример ситуации, в которой не осуществляет неявное закрытие курсоров. Интересная информация по этой теме приведена в статье Джонатана Генника « ?».
- Если курсор объявлен в пакете на уровне пакета и открыт в некотором блоке или программе, он останется открытым до тех пор, пока вы его явно не закроете, или до завершения сеанса. Поэтому, завершив работу с курсором пакетного уровня, его следует немедленно закрыть командой (и кстати, то же самое следует делать в разделе исключений):
Курсор можно закрывать только в том случае, если ранее он был открыт; в противном случае будет инициировано исключение INVALID_CURS0R. Состояние курсора проверяется с помощью атрибута %ISOPEN:
Если в программе останется слишком много открытых курсоров, их количество может превысить значение параметра базы данных OPEN_CURSORS. Получив сообщение об ошибке, прежде всего убедитесь в том, что объявленные в пакетах курсоры закрываются после того, как надобность в них отпадет.
Когда использовать курсоры
Ниже приведен анализ различных сценариев, в которых логика на базе курсора может быть предпочтительной и наоборот:
- OLTP (оперативная обработка транзакций) – в большинстве сред OLTP логика на основе множества строк (INSERT, UPDATE или DELETE) имеет наибольшее предпочтение для коротких транзакций. Наша команда выполняла стороннее приложение, которое использовало курсоры для любой обработки, что вызывало проблемы, но это случалось нечасто. Обычно логики на основе множеств более чем достаточно, и курсоры редко могут понадобиться.
Отчеты – для проектирования отчетов курсоры обычно не нужны. Однако наша команда столкнулась с требованиями к отчетности, когда не существовало ссылочной целостности в используемой базе данных, и было необходимо использовать курсор для корректного вычисления отчетных значений. Мы имели подобный опыт при необходимости агрегировать данные для последующих процессов. Подход на основе курсора было быстро разработать и выполнить в приемлемой манере.
Последовательная обработка – если вам необходимо выполнить процесс в последовательной манере, курсоры являются работоспособным вариантом.
Административные задачи – многие административные задачи, подобные резервированию баз данных или проверки согласованности баз данных, требуется выполнять в последовательной манере, которая хорошо вписывается в основанную на курсорах логику. Но существуют и другие системные объекты, которые удовлетворяют эту потребность. В некоторых из этих случаев курсоры используются для завершения процесса.
Большие наборы данных – при больших наборах данных вы можете столкнуться с одним или несколькими из следующих случаев:
- Логика на основе курсора может не масштабироваться в достаточной мере.
Операции на основе множеств с большими объемами данных на сервере с минимальным количеством памяти могут привести к тому, что данные будут выгружаться, отнимая много времени и потенциально вызвая конфликты и проблемы с памятью. В этом случае, решение на базе курсора может оказаться приемлемым.
Некоторые инструменты фактически кэшируют данные в файл, поэтому обработка данных в памяти может и не иметь места.
Если данные могут быть обработаны на автономном SQL Server, то влияние на производственную среду будет оказываться только на финальной стадии обработки. Все ресурсы автономного сервера могут использоваться для процессов ETL, после чего полученные данные импортируются.
SSIS поддерживает пакетную обработку наборов данных, которая может решить общую необходимость разбить большой набор данных на более мелкие и справиться с ними лучше, чем построчным методом на базе курсора.
В зависимости от того, как закодирована логика курсора или SSIS, может иметься возможность перезапуска с точки сбоя на основе контрольных точек, или обработки каждой строки при помощи курсора. Однако при подходе на основе множеств это может оказаться недоступным, пока не будет обработан весь набор данных. В таком случае найти строку, которая вызвала сбой, будет более сложным.
Динамическое создание периодических задач
Основная мысль, которую я бы хотел донести в статье, заключается в том, что периодические задачи являются обычными моделями, с которыми можно работать через Django ORM. Сейчас покажу на примере:
Допустим, вы создаете сервис, который делает заказы на стороннем сервисе через API. В ответе от этого сервиса вы получаете статус вашего заказа. Если мы получили статус от сервиса, то все отлично, дальше мы выполняем всю необходимую логику с этим заказом. Если же нет (например, пришел ответ ) — тогда необходимо переотправлять запрос, пока статус не будет получен.
Мы не будем усложнять себе жизнь работой с API каких-либо сервисов. Сымитируем ответ от воображаемого сервиса с помощью custom command, которую самостоятельно напишем.
В папке приложения создадим папку «management», в ней папку «command» и в ней файл с кодом, например, «make_order.py».
И напишем код будущей консольной команды.
Данная команда ожидает 2 аргумента на вызове: первый — это статус, второй — id заказа. Если мы получаем статус от нашего воображаемого сервиса, тогда нам необходимо повторно отправлять запросы на получение статуса. Тут-то нам и пригодятся периодические задачи. В данном примере мы создаем из . В качестве аргументов мы передаем ей следующие параметры:
- Имя создаваемой задачи: , в дальнейшем с ее помощью мы будем останавливать задачи, если нам это необходимо.
- Задача, которая будет периодически выполняться через определенный промежуток времени. В нашем случае это: .
- Интервал, через который мы хотим, чтобы задача выполнялась: . также является моделью из , поэтому мы можем пользоваться функциональностью, предоставляемой Django ORM
- Аргументы, которые будут передаваться в указанную функцию. В нашем случае задаче будет передан аргумент , то есть .
- И время начала работы периодической задачи: .
Давайте теперь посмотрим на код задачи . Создадим файл «task.py» в корне нашего приложения (как на скриншоте) и напишем следующий код.
В коде учитывается, что если заказ уже получил статус, то нет необходимости больше выполнять написанную нами периодическую задачу. Для того, чтобы остановить последующее выполнение задачи, мы получаем экземпляр задачи с помощью метода , передавая в качестве аргумента имя, которое мы дали во время создания задачи. Затем мы переводим поле в состояние , что остановит выполнение задачи в дальнейшем, и обязательно сохраняем экземпляр задачи.
Давайте теперь проверим результаты наших трудов. Запустим написанную нами команду с помощью . То есть мы делаем заказ №1 и как будто получаем ответ со статусом . Это должно создать новую периодическую задачу. Давайте глянем в celery_beat командой .
И увидим, как началось периодическое выполнение задачи , которую мы описали выше. А также заглянем в Celery командой (я запускал каждую команду в отдельном окне терминала).
Видно, что Celery получает, и посылаем задачи для исполнения.
Теперь изменим статус нашего заказа, снова запустив команду , но уже с параметрами «Принят, 1». То есть . После чего можно посмотреть в терминал с celery-beat и увидеть сообщение о том, что было изменено расписание выполнения задач, после чего постоянный вызов прекратится.
Таким образом, мы научились создавать периодические задачи прямо в коде программы, без использования административного сайта проекта, и также научились их останавливать. Я постарался привести пример из личного опыта, однако максимально упростил его, чтобы выжать максимум информации по конкретному случаю использования периодических задач. Если вы хотите больше узнать о том, как пользоваться периодическими задачами или посмотреть другие кейсы использования этого инструмента, я рекомендую ознакомиться со следующими материалами: раз и два.
Какие задачи выполняются для обслуживания системы
Можно выполнить обслуживание вручную из панели управления или командой MSchedExe.exe Start и посмотреть, что при этом происходит. Для полного счастья откройте сначала диспетчер задач, а заодно монитор ресурсов на вкладке «Диск».
Так, я первым делом увидел процессорную активность процесса MsMpEng.exe. Открыв Windows Defender, я убедился в том, что выполняется быстрое сканирование . Одновременно начал мигать индикатор внешнего диска, а монитор ресурсов указал на активность в папке с изображениями. Мое предположение о том, что это дело рук истории файлов, быстро подтвердилось фильтром Process Monitor.
В любом случае вы увидите потребление ресурсов CPU процессом system, поскольку обслуживание выполняется от имени системы. В частности, в обслуживание входят еще такие задачи:
- Автоматическое создание резервной копии реестра
- Передача данных об использовании системы в рамках
- Отправка
- Оптимизация и дефрагментация дисков
- Обновление
- Оптимизация загрузки системы
- Создание точки восстановления системы
Я сознательно не стал перечислять все задачи, поскольку вы можете выяснить их список самостоятельно! Для этого пробегитесь по папкам планировщика в разделе Windows, обращая внимание на время последнего запуска задания. Если задание выполнялось вскорости после запуска Manual Maintenance, оно входит в общий список задач по обслуживанию
На рисунке выше видно несколько заданий планировщика, которые система выполнила сразу после запуска единого задания обслуживания
Если задание выполнялось вскорости после запуска Manual Maintenance, оно входит в общий список задач по обслуживанию. На рисунке выше видно несколько заданий планировщика, которые система выполнила сразу после запуска единого задания обслуживания.

Впрочем, все эти задачи вовсе необязательно выполняются в полном объеме. Если вы не участвуете в CEIP или отсутствуют новые отчеты о неполадках, то и отправлять нечего. Точно так же, , она не и не будет создаваться.
Our Database Plan
Our blog database has a problem. Old posts are marked as deleted rather than being removed from the `blog` table. Our table will grow indefinitely and become slower over time. We could purge the old posts but that would remove them forever. Therefore, we’ll move posts and their associated audit records to archive tables. The archive tables can grow without affecting the speed of the main web application and we can undelete old posts if necessary.
Two archive tables are required:
- `blog_archive`: identical to the `blog` table except it does not require a deleted flag or an auto-incrementing ID.
- `audit_archive`: identical to the `audit` table except the timestamp is not automatically generated and it does not require an auto-incrementing ID.
The following SQL creates both tables: